

根据英伟达的数据显示,在2023年,公司与AI工作负载相关的英伟达数据中心部门的销售收入为184亿美元,比去年同期增长了409%。2023年,Nvidia在数据中心GPU市场占有约98%的份额,因为其旗舰H100芯片几乎没有竞争对手。
进入2024年,英伟达的GPU销量依然猛增,英伟达CEO黄仁勋也直言,公司新推出的Blackwell在市场的关注度非常高,也有很多客户在买。根据Jon Peddie Research的数据,今年全球GPU市场预计将超过985亿美元。黄仁勋也认为,数据中心运营商将在未来四年内花费1万亿美元升级其基础设施,以满足AI开发人员的需求,因此这个机会足以支持多家GPU供应商。
最近几天的消息看来,Elon Musk和Mark Zuckerberg已经率先开始了新一轮GPU争夺赛。
Elon Musk要打造100万GPU集群
据金融时报最新报道,埃隆·马斯克的人工智能初创公司xAI承诺将其Colossus超级计算机扩大十倍,以容纳超过100万个图形处理单元,以超越谷歌、OpenAI和Anthropic等竞争对手。
Colossus于今年早些时候建成,仅用了三个月时间,被认为是世界上*的超级计算机,运行着一个由100,000多个互连的Nvidia GPU组成的集群。马斯克位于孟菲斯的超级计算机非常引人注目,因为他的初创公司能够快速将GPU组装成一个AI处理工作集群。“从开始到结束,只用了122天,”马斯克说。超级计算机通常需要数年时间才能建成。
他的公司可能还花费了至少30亿美元来组装这台超级计算机,因为目前这台超级计算机由10万块Nvidia H100 GPU组成,每块GPU的价格通常约为3万美元。马斯克现在想用H200 GPU来升级这台超级计算机,H200 GPU的内存更大,但每块GPU的价格接近4万美元。
Nvidia也透露,称xAI的“Colossus”超级计算机的规模正在扩大一倍。马斯克还在推特上表示,这台超级计算机即将在一座占地785000平方英尺的建筑物内整合200000个H100和H200 Nvidia GPU。
戴尔首席运营官杰夫·克拉克周四在接受采访时表示:“我们从一张白纸开始,在短短几个月内大规模部署了数万个GPU。”“该集群仍在建设中,我们正在脱颖而出。”
如上所述,马斯克的初创公司xAI正在开发一个大型设施,以提高其在打造人工智能工具的竞赛中的计算能力。大孟菲斯商会周三也发表声明称,扩大田纳西州孟菲斯工厂规模的工作已经开始。商会表示,Nvidia、戴尔和超微电脑也将在孟菲斯建立业务以支持扩张,同时将成立一支“xAI特别行动团队”,以“为公司提供全天候礼宾服务”。
相关报道指出,目前尚不清楚xAI计划在扩展期间使用当前一代Hopper还是下一代Blackwell GPU。Blackwell平台的扩展性预计比Hopper更好,因此使用即将推出的技术而不是现有技术更有意义。但无论如何,获得800,000–900,000个AI GPU都很难,因为Nvidia产品的需求量巨大。另一个挑战是让1,000,000个GPU以最高效率协同工作,而Blackwell再次更有意义。
据华尔街日报之前的报道,英伟达的一位销售主管告诉同事,马斯克对芯片的需求给公司的供应链带来了压力。Nvidia的一位发言人表示,公司一直努力满足所有客户的需求。
当然,此次扩张的资金需求是巨大的。购买GPU(每个花费数万美元)以及电力和冷却基础设施可能会将投资推高至数百亿美元。xAI今年已筹集了110亿美元,最近又获得了50亿美元。目前,该公司的估值为450亿美元。
Meta也砸百亿建设数据中心
在Elon Musk抢购GPU的同时,Mark Zuckerberg也不甘示弱。
Meta Platforms Inc周三表示,公司计划在路易斯安那州东北部建设一个价值100亿美元的人工智能数据中心园区,这将是该公司迄今为止建设的*数据中心。该园区占地400万平方英尺,将坐落于里奇兰教区,这是一个以农田为主的农村地区,靠近现有的公用基础设施,预计本月破土动工,并持续到2030年。
数据中心规划的基础设施将容纳处理海量数据所需的网络和服务器,以支持日益增长的数字技术使用,并将针对人工智能工作负载进行优化,这些工作负载尤其需要数据和计算。一旦上线,它将能够支持Meta的所有服务,包括Facebook、Messenger、Instagram、WhatsApp和Threads。
在此次数据中心投资消息公布之前,其他公司也在努力扩大其数据和计算能力,以满足人工智能和机器学习应用程序和工作负载日益增长的需求。
Meta数据中心战略总监Kevin Janda表示:“Meta正在构建人类连接的未来以及实现这一目标的技术。这个数据中心将成为这一使命的重要组成部分。”
路易斯安那州州长杰夫·兰德里表示,新数据中心将为该地区带来新的技术机遇。路易斯安那州经济发展局是一家致力于改善该州商业环境的政府机构,据该机构估计,该园区将创造约1,500个就业岗位。
“Meta的投资将使该地区成为路易斯安那州快速发展的科技行业的支柱,振兴我们州美丽的乡村地区之一,并为路易斯安那州的工人创造未来高薪工作的机会,”兰德里说。
Meta没有透露新设施将支持多少GPU,也没有透露打算使用哪家公司的芯片。据Entergy称,该中心将由三座天然气厂提供电力,总发电量为2.2千兆瓦。他们也强调,其中大部分成本将用于加速器以及支持它们的主机、存储和网络。如果你假设人工智能设施90%的成本用于IT设备,那么建设该设施的成本为10亿美元,而设备成本为90亿美元。假设IT设备成本的一半多一点用于加速器,那么现在就是50亿美元。以平均25000美元的价格计算,这相当于200000个人工智能加速器。如果你假设这里将挤满未来自主研发的MTIA加速器,而这些加速器的成本只有这里一半,那么这些加速器的成本将达到400000美元。
Meta首席执行官马克·扎克伯格此前曾表示,到2024年底,公司将在公司数据中心运行350000块Nvidia H100芯片,尽管该公司也在开发自己的AI硬件。
谁拥有最多的GPU?
除了上述两家厂商以外,包括微软、谷歌、AWS和CoreWeave以及国内一众的云厂商都成为了英伟达GPU的追逐者。财富在日前的报道中指出,一个由三家特别财力雄厚的客户组成的精英群体,在截至10月底的前九个月内,分别购买了价值100亿至110亿美元的商品和服务。(具体参考文章《》)
而统计当前的GPU拥有量,按博客lesswrong的预估,如果都换成以H100的等效算力。截至目前,世界五大科技公司的2024年拥有的算力,以及2025年的预测:
微软有75万-90万块H100,明年预计达到250万-310万;
谷歌有100万-150万块H100,明年预计达到350万-420万;
Meta有55万-65万块H100,明年预计达到190万-250万;
亚马逊有25万-40万块H100,明年预计达到130万-160万;
xAI有10万块H100,明年预计达到55万-100万;
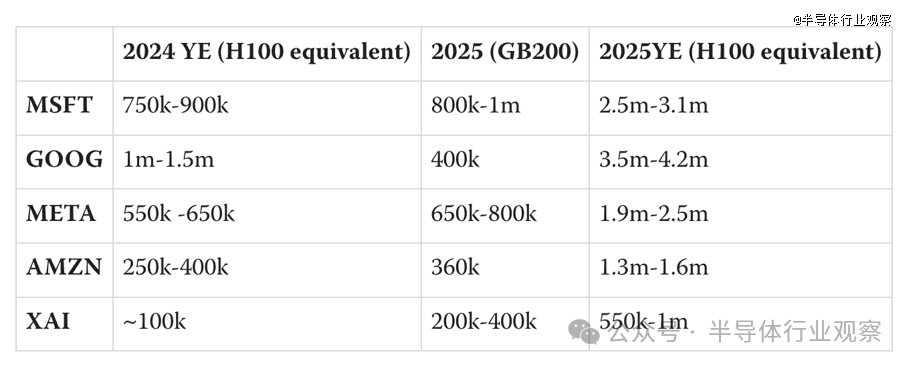
该博客同时指出,按照2024年人工智能状况报告主要供应商购买Blackwell芯片的情况进行了估计——大型云公司正在大量购买这些GB200系统:微软购买了70万到140万个,谷歌购买了40万个,AWS购买了36万个。据传,OpenAI至少拥有40万个GB200。
由此可见,新一代的Blackwell的受欢迎程度很高。目前正在建设的数据中心可能会采用Nvidia的Blackwell芯片,该公司预计明年将大量出货。不过,市场已经开始期待该公司推出的Rubin芯片,这是Blackwell之后的下一代芯片。
英伟达首席执行官黄仁勋在10月初接受CNBC的《Closing Bell Overtime》节目采访时表示,该公司下一代人工智能芯片Blackwell的需求“疯狂”。他说道:“每个人都想拥有最多,每个人都想成为*。”
黄仁勋在接受CNBC采访时表示:“在技术发展如此迅速的时代,我们有机会三倍投入,真正推动创新周期,从而提高产能、提高产量、降低成本、降低能耗。我们正在朝着这个方向努力,一切都在按计划进行。”
首席财务官科莱特·克雷斯(Colette Kress)八月份曾表示,公司预计第四财季Blackwell营收将达数十亿美元。
Jensen表示,Nvidia计划每年更新其AI平台,将性能提高两到三倍。
Melius Research分析师Ben Reitzes在一份研究报告中写道:“越来越多的猜测认为,Nvidia的下一代GPU(继Blackwell之后)——名为Rubin——可能会比大多数投资者预计的2026年提前6个月准备就绪。”
Reitzes警告称,芯片的发布很少会提前,并维持该股195美元的目标价,他表示,这是假设Rubin在2026年下半年进行部署。
写在最后
在GPU广受欢迎的当下,英伟达无疑是*的赢家。但AMD也不甘人后,正在努力成为这个市场的另一个重要角色。除此以外,微软、Meta、谷歌、AWS等巨头,也都在打造自主的AI芯片,希望在这个市场凭借自研的加速器,去英伟达GPU之间找到另一个平衡点。
例如AWS首席执行官马特·加曼(Matt Garman)在日前的大会中所说:“如今,GPU方面实际上只有一个选择,那就是Nvidia。我们认为客户会喜欢有多种选择。”










