

近日,由行业知名人士Jim Keller担任CEO的Tenstorrent宣布完成由三星证券和 AFW Partners 领投的 6.93 亿美元 D 轮融资。在这轮融资之后,这家 AI 芯片初创公司的估值约为 26 亿美元。
Tenstorrent 创始人兼半导体先驱 Jim Keller 在接受采访时表示,该公司希望开发一款芯片,试图打破 Nvidia 对 AI 业务的垄断,该公司在由韩国 AFW Partners 和三星证券领投的一轮融资中筹集了资金。Bezos Expeditions 与 LG Electronics Inc. 和 Fidelity 联手参与了这轮融资,看好 Keller 的实力和人工智能技术领域的蓬勃发展机会。
值得一提的是,Bezos Expeditions的实控人为亚马逊创始人Jeff Bezos。考虑到AWS对英伟达芯片的采购量,可以看到这个投资背后的深层次含义。
除了领投方之外,许多知名投资者也参与了此轮融资,其中包括 XTX Markets、Corner Capital、MESH、加拿大出口发展局、安大略省医疗养老金计划、LG 电子、现代汽车集团、富达管理与研究公司、Baillie Gifford、Bezos Expeditions 等。
Tenstorrent方面表示,由于投资者需求强劲,该轮融资获得超额认购。Jim Keller 在接受采访时更是表示,该公司希望开发一款芯片,试图打破 Nvidia 对 AI 业务的垄断。
Tenstorrent是谁?
关于谁是Jim Keller,媒体已经做了很多报道,我们就不再多言。参考半导体行业观察之前发布的文章《Jim Keller的芯片研发封神之路》可以看到其光辉的履历。至于Tenstorrent,则是一家由Jim Keller支持并担任CEO的公司。
Tenstorrent 总部位于加利福尼亚州圣克拉拉,主要开发和销售专为 AI 工作负载而设计的计算系统,这些系统均围绕该公司的 Tensix 核心开发。该公司的愿景是打破 Nvidia 在芯片硅片市场的垄断,设计出更实惠的 AI 训练和部署硬件,避免使用 Nvidia 使用的高带宽内存等昂贵组件。
“如果你使用 HBM,你就无法击败 Nvidia,因为 Nvidia 购买的 HBM 最多,而且具有成本优势,”Jim Keller在接受彭博社采访时候说。“但他们永远无法像 HBM 内置到他们的产品和插槽中那样降低价格。”
众所周知,Nvidia 为开发人员提供了全套专有技术,涵盖从芯片到互连甚至数据中心布局的方方面面,并承诺所有部件都能更好地工作,因为它们是协同设计的。而竞争对手 AMD和 Tenstorrent 等公司则致力于与其他技术提供商实现更大的互操作性,无论是通过共享行业标准还是开放设计供他人使用。
为了吸引更多潜在客户,该公司专注于与其他供应商进行可互操作的硬件设计。它使用开放标准的RISC-V 处理器架构,旨在为工程师和开发人员提供一个更开放的生态系统,以便将其处理器和系统应用于他们的数据中心和服务器设置。“过去,我使用专有技术,这真的很艰难,”Jim Keller 说。“开源可以帮助你构建更大的平台。它吸引了工程师。是的,这是一个充满激情的项目。”
为了实现这一目标,Tenstorrent将 AI 和 RISC-V 知识产权授权给想要拥有和定制专用芯片的客户。RISC-V 是一种开源指令架构,用于基于所谓的“精简指令集”为不同应用开发定制处理器,这使得它非常易于使用、定制和优化功率、性能和功能。
与 RISC-V 和日本合作伙伴 Rapidus一样,Tenstorrent 仍有很多需要证明的地方。迄今为止,这家新兴公司已与客户签订了总额近 1.5 亿美元的合同,与 Nvidia 每季度数百亿美元的数据中心收入相比,这相形见绌。
该公司表示,将利用新资金构建开源 AI 软件堆栈,并聘请开发人员来扩大全球开发和设计中心。这将使该公司能够构建系统和云,供 AI 开发人员在其系统上使用和测试模型。
Tenstorrent 表示,其首批芯片由 GlobalFoundries制造,下一代芯片将来自台湾半导体制造公司和三星电子公司。该公司还开始为尖端的 2 纳米制造进行设计。台积电和三星将于明年开始大规模生产,Tenstorrent 正在与他们以及日本的 Rapidus 进行谈判,后者的目标是在 2027 年实现 2 纳米产量。
XTX Markets 首席技术官 Joshua Leahy 表示:“我们发现 Tenstorrent 的开源驱动方法令人耳目一新,尤其是在专有且通常保密的 AI 加速器领域。”
随着公司开始利用新资金扩大规模,它将在 Nvidia 占据优势的市场中面临阻力。然而,Jim Keller 仍然相信,通过提供更实惠、可以根据业务需求量身定制的 AI 芯片,并每两年发布一款新处理器,可以帮助该公司在 AI 芯片行业保持商业上可行的产品。
在接受媒体采访的时候,Jim Keller曾总结说:
Tenstorrent 是一家设计公司。我们设计CPU,我们设计人工智能引擎,我们设计人工智能软件堆栈。
因此,无论是软 IP、硬 IP chiplet还是完整芯片,这些都是实现。我们在这方面很灵活。例如,在 CPU 上,我们将在我们自己的chiplet流片之前对其进行多次许可。我们正在与六家想要从事定制内存芯片或 NPU 加速器等业务的公司进行交谈。我认为对于我们的下一代,无论是 CPU 还是 AI,我们将构建 CPU 和 AI chiplet。但随后其他人会做其他的小芯片。然后我们会将它们整合到系统中。
凭啥挑战英伟达?
从上面的介绍中,我们分享了Tenstorrent的愿景。接下来,我们了解一下这家公司的产品和路线图。
在2023年三月,Tenstorrent 的首席 CPU 架构师 Wei-Han Lien 在接受媒体采访的时候就表示,由于 Tenstorrent 着眼于解决广泛的 AI 应用问题,因此它不仅需要不同的片上系统或系统级封装,还需要各种 CPU 微架构实现和系统级架构,以实现不同的功率和性能目标。
Tenstorrent 表示,公司的CPU 团队开发了一种无序 RISC-V 微架构,并以五种不同的方式实现它,以满足各种应用的需求。
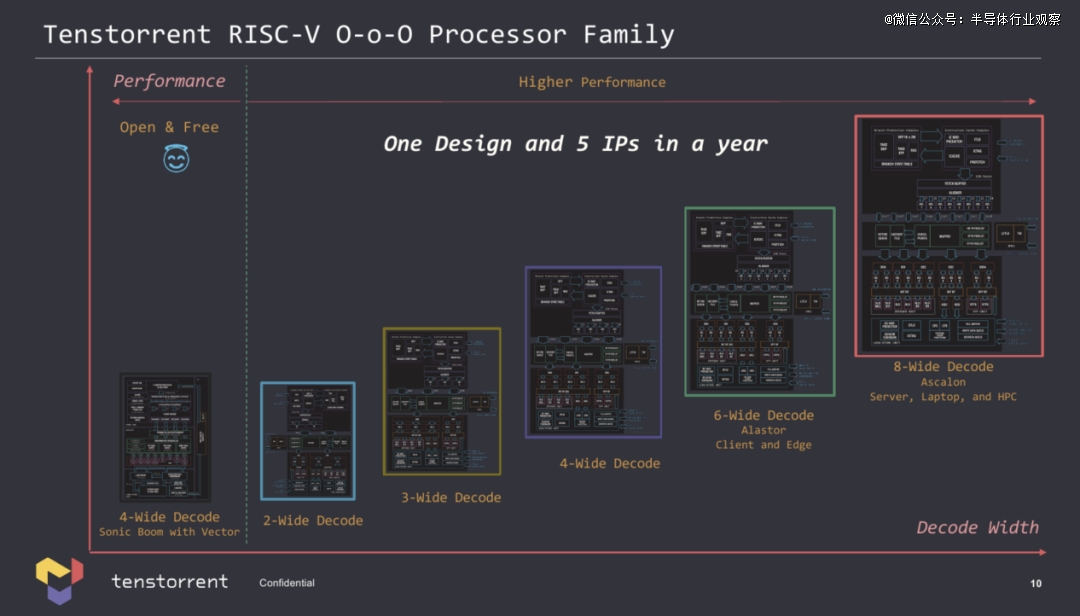
Tenstorrent 现在有五种不同的 RISC-V CPU 核心 IP,包括双宽、三宽、四宽、六宽和八宽解码,可用于自己的处理器或授权给感兴趣的各方。对于那些需要非常基本的 CPU 的潜在客户,该公司可以提供具有双宽执行能力的小核心,但对于那些需要更高性能用于边缘、客户端 PC 和高性能计算的客户,它有六宽 Alastor 和八宽 Ascalon 核心。
每个具有八宽解码的无序 Ascalon ( RV64ACDHFMV ) 核心都有六个 ALU、两个 FPU 和两个 256 位矢量单元,因此非常强大。考虑到现代 x86 设计使用四宽 (Zen 4) 或六宽 (Golden Cove) 解码器,我们看到的是一个功能非常强大的核心。

除了各种 RISC-V 通用核心外,Tenstorrent 还拥有专为神经网络推理和训练量身定制的专有 Tensix 核心。每个 Tensix 核心由五个 RISC 核心、一个用于张量运算的数组数学单元、一个用于矢量运算的 SIMD 单元、1MB 或 2MB 的 SRAM 以及用于加速网络数据包操作和压缩/解压缩的固定功能硬件组成。Tensix 核心支持多种数据格式,包括 BF4、BF8、INT8、FP16、BF16 甚至 FP64。

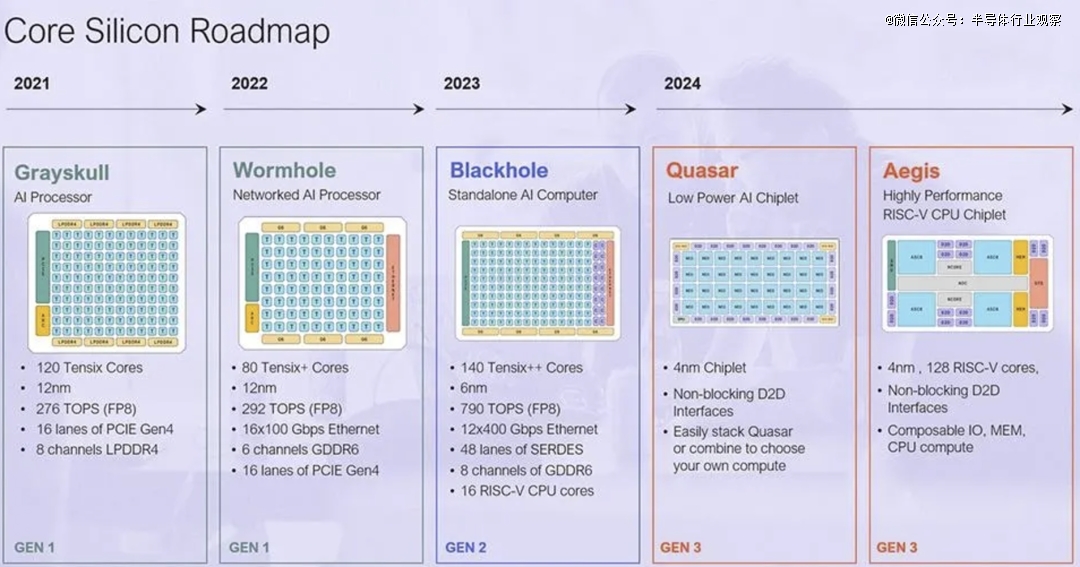
截止2023年三月,Tenstorrent 有两种产品:一种名为 Grayskull 的机器学习处理器,提供约 315 INT8 TOPS 的性能,可插入 PCIe Gen4 插槽;另一种是联网的 Wormhole ML 处理器,性能约为 350 INT8 TOPS,使用 GDDR6 内存子系统、PCIe Gen4 x16 接口,并与其他机器建立 400GbE 连接。

这两种设备都需要主机 CPU,可作为附加板使用,也可内置于预置的 Tenstorrent 服务器中。一台 4U Nebula 服务器包含 32 张 Wormhole ML 卡,可提供约 12 个 INT8 POPS 的性能,功率为 6kW。
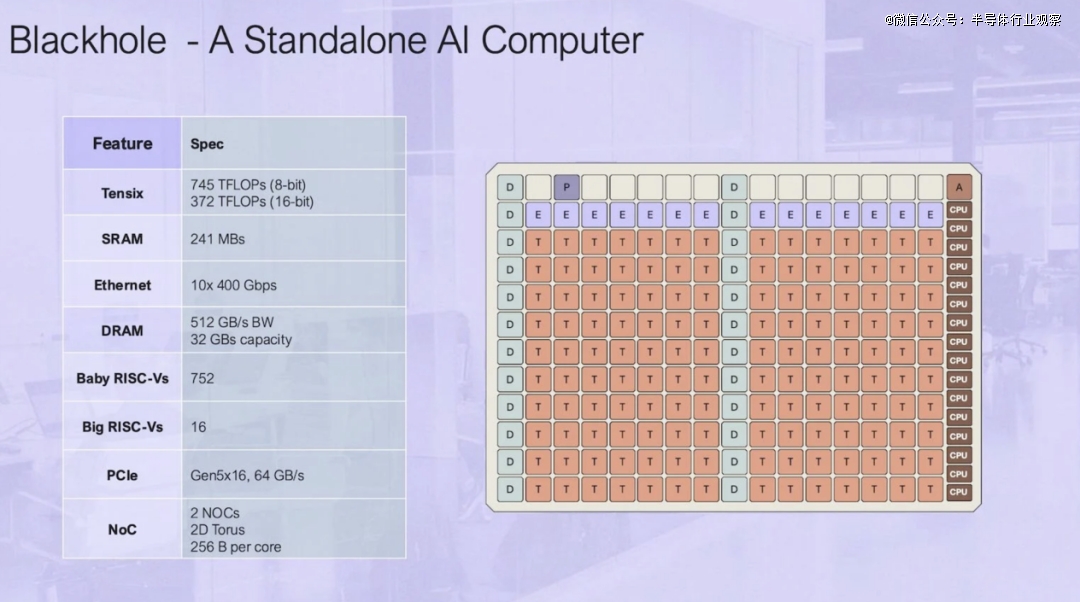
在今年八月举办的 Hot Chips 上,Tenstorrent披露了Blackhole AI 加速器进行。与之前作为基于 PCIe 的加速器部署的 Greyskull 和 Wormhole 部件不同,Tenstorrent 的 Blackhole旨在作为独立的 AI 计算机运行。
他们声称,该加速器在原始计算和可扩展性方面可以胜过 Nvidia A100。据介绍,每个 Blackhole 芯片都拥有 745 teraFLOPS 的 FP8 性能(FP16 为 372 teraFLOPS)、32GB 的 GDDR6 内存和基于以太网的互连,能够在其 10 个 400Gbps 链路上实现 1TBps 的总带宽。
Tenstorrent 展示了其最新芯片如何在性能上比 Nvidia A100 GPU 略有优势,尽管在内存容量和带宽方面都落后。然而,就像 A100 一样,Tenstorrent 的 Blackhole 旨在作为横向扩展系统的一部分进行部署。这家 AI 芯片初创公司计划将 32 个 Blackhole 加速器以 4x8 网格的形式连接起来,塞进一个节点,并将其称为 Blackhole Galaxy。
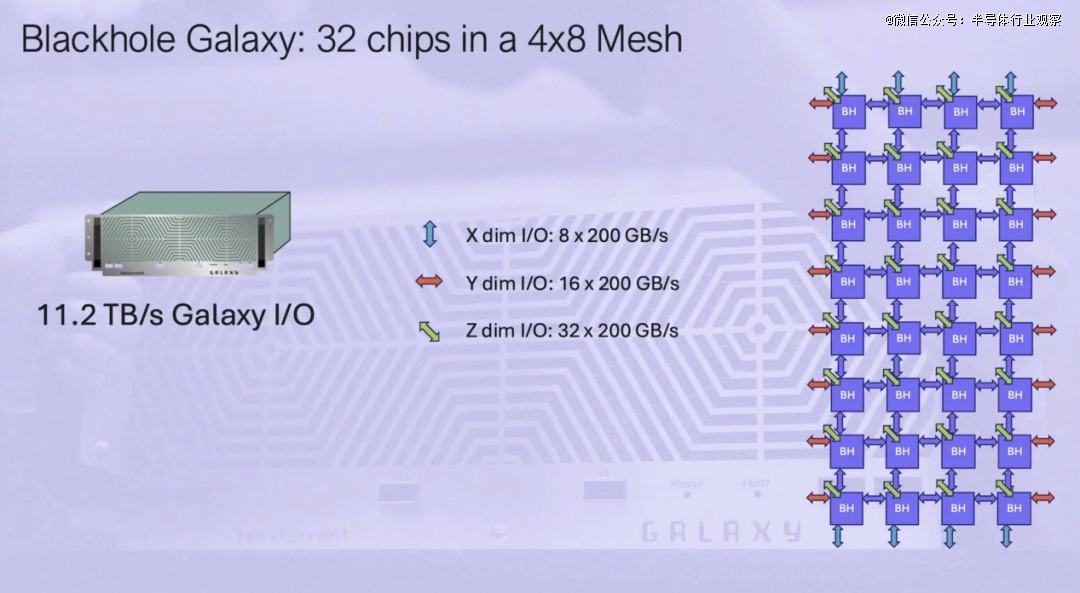
总体而言,单个 Blackhole Galaxy 承诺 FP8 的 23.8 petaFLOPS 或 FP16 的 11.9 petaFLOPS,以及能够提供 16 TBps 原始带宽的 1TB 内存。此外,Tenstorrent 表示,该芯片的核心密集型架构(我们稍后会深入探讨)意味着这些系统中的每一个都可以用作计算或内存节点,或用作高带宽 11.2TBps 的 AI 交换机。
Tenstorrent 人工智能软件和架构高级研究员 Davor Capalija 表示:“你可以用它作为乐高积木来搭建整个训练集群。”
值得一提的是。Tenstorrent 使用板载以太网,这意味着它避免了在芯片到芯片和节点到节点网络中处理多种互连技术所带来的挑战,而 Nvidia 则必须使用 NVLink 和 InfiniBand/以太网。在这方面,Tenstorrent 的横向扩展策略与英特尔的Gaudi 平台非常相似,后者也使用以太网作为其主要互连。考虑到 Tenstorrent 计划在一个盒子里塞入多少个 Blackhole 加速器,更不用说一个训练集群,看看它们如何处理硬件故障将会很有趣。
Tenstorrent 表示,Blackhole之所以能作为独立的 AI 计算机运行,主要归功于 16 个“Big RISC-V”64 位、双发射、有序 CPU 核心,这些核心排列在四个集群中。至关重要的是,这些核心足够强大,可以作为运行 Linux 的设备主机。这些 CPU 核心与 752 个“Baby RISC-V”核心配对,后者负责内存管理、片外通信和数据处理。
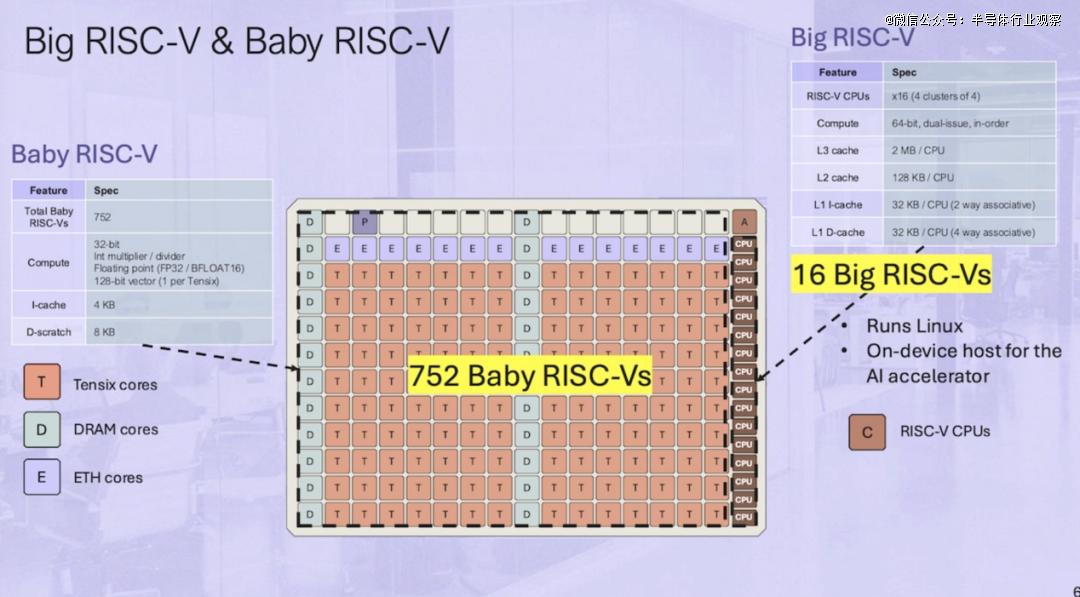
然而,实际计算是由 Tenstorrent 的 140 个 Tensix 核心处理的,每个核心由五个“Baby RISC-V”核心、一对路由器、一个计算综合体和一些 L1 缓存组成。
计算综合体由一个用于加速矩阵工作负载的图块数学引擎和一个矢量数学引擎组成。前者将支持 Int8、TF32、BF/FP16、FP8 以及 2 到 8 位的块浮点数据类型,而矢量引擎则以 FP32、Int16 和 Int32 为目标。
据他们所说,这种配置意味着该芯片可以支持 AI 和 HPC 应用中的各种常见数据模式,包括矩阵乘法、卷积和分片数据布局。
总体而言,Blackhole 的 Tensix 核心占了 752 个所谓的板载 RISC-V 核心中的 700 个。其余核心负责内存管理(“D”代表 DRAM)、片外通信(“E”代表以太网)、系统管理(“A”)和 PCIe(“P”)。
除了新芯片之外,Tenstorrent 还公开了其加速器的 TT-Metalium 低级编程模型。
熟悉 Nvidia CUDA 平台的人都知道,软件可以成就或毁掉性能最高的硬件。事实上,TT-Metalium 有点让人联想到 CUDA 或 OpenCL 等 GPU 编程模型,因为它是异构的,但不同之处在于它是从“AI 和横向扩展”计算开始构建的,Capalija 解释道。
其中一个区别是内核本身是带有 API 的纯 C++。“我们认为不需要特殊的内核语言,”他解释道。
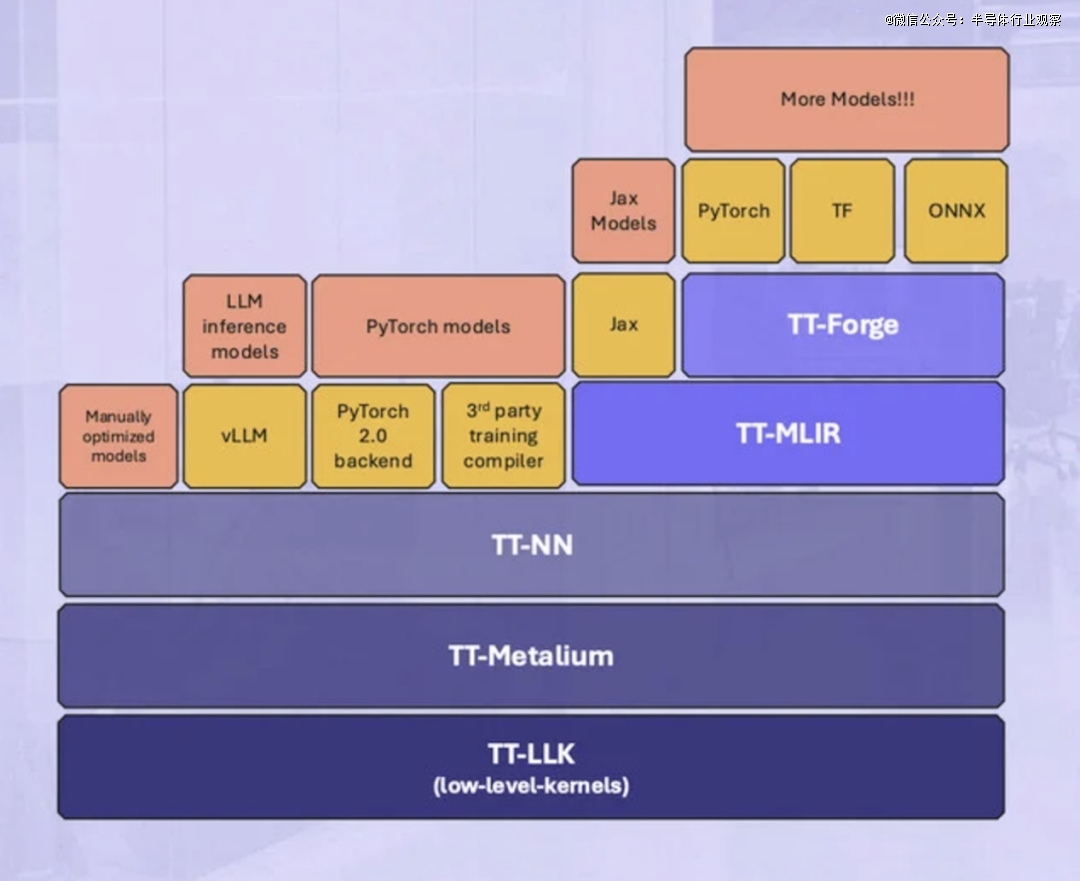
结合 TT-NN、TT-MLIR 和 TT-Forge 等其他软件库,Tenstorrent 旨在支持使用 PyTorch、ONNX、JAX、TensorFlow 和 vLLM 等常用运行时在其加速器上运行任何 AI 模型。
写在最后
替代英伟达是很多人的想法,但替代英伟达似乎是任何一个人都很难达成的目标。例如,大家都知道,英伟达能稳坐钓鱼台,除了得益于其*的硬件外,包括CUDA在内的软件实力,是他们能垄断至今的根本。
但Jim Keller曾表示:“CUDA并不是护城河,而是沼泽。”他同时认为,GPU并不是运行人工智能的全部。
“我希望可以帮助客户构建自己的产品,这是一件很酷的事情,您可以拥有并控制它,而不用向其他人支付 60% 或 80% 的毛利率。因此,当人们告诉我们 Nvidia 已经赢了,并问为什么 Tenstorrent 会参与竞争时,那是因为只要存在利润率极高的垄断,就会创造商机。”Jim Keller说。
在笔者看来,亚马逊后续会如何与英伟达battle,也会是一个有意思的话题。










