

以生成式模型(generative model)为代表的下一代AI正在席卷科技行业乃至整个人类社会。目前,人们对于生成式模型的关注还主要在于以OpenAI和谷歌为代表的人工智能巨头运行在云端服务器的模型,这些模型需要巨大的算力,并且一般运行在GPU上。然而,随着技术的发展,我们认为生成式模型运行在手机端已经到了一个转折点,马上会进入大规模铺开的阶段。
在看具体技术之前,我们不妨先看一下,用户对于运行在手机端的生成式模型有哪些具体应用场景。这期是值得我们仔细考虑,因为像ChatGPT这样的人工智能对话应用并不需要真正运行在手机终端——让ChatGPT完成文稿设计这样的需求的*使用场景还是在接入互联网的电脑上,而不是运行在手机本地。我们认为,最适合生成式模型运行在手机终端芯片上的*是拍摄增强,包括超分辨、去模糊、照片补全等,这些应用需要模型能在任何时候都能低延迟地运行,因此需要在本地执行。另一个任务是智能助理,指的是通过运行一个大模型去检索所有用户本地的备忘录、短信记录等,通过综合用户所有的个人信息来实现智能助理的功能——例如如果检测到用户和某个联系人最近的短信是关于约在饭店吃饭,助理可以自动设置一个提醒信息,等等。由于涉及到用户隐私,因此这类模型也需要运行在手机本地的芯片上。
对于用于拍摄增强的生成式模型主要是以扩散(diffusion)模型为代表的图像生成式模型。扩散模型在去年一年中取得了长足的进步,其生成内容的质量足以改变用户的拍摄体验,包括:
1 | 超分辨:使用扩散模型可以把低分辨率的图片以很高的质量转换成高分辨率图像,其质量远高于目前已有的其他模型。 |

2 | 图像修补:包括把图像中不想要的内容去除/更换(即inpainting),或者把图片内容进一步补全(即outpainting)。 |

对于基于扩散模型的生成式图像模型,自从Stable Diffusion从去年下半年发布之后,已经获得了业界极大的关注。扩散模型一般的模型都较大,而且需要运行多步的采样过程,之前虽然也有运行在手机上的例子,但是因为运行时间过程(10秒左右),尚未得到真正大规模应用。然而,随着今年10月份中国清华团队发表了latent consistency model(LCM)的研究论文,在手机上运行高性能图像生成式模型已经不再遥不可及。
LCM模型和Stable Diffusion的模型结构类似,但是LCM通过数学上的优化,可以把一次生成需要的模型执行次数从Stable Diffusion的50次降低到2-4次,相当于把端到端的运行速度提升了10倍,而且生成图像的质量和Stable Diffusion接近。目前,LCM已经在人工智能社区得到了广泛的关注和应用,我们认为很快LCM就会成为手机上运行图像生成式模型的*,而且LCM的低延迟可以真正实现全新的用户体验;例如,高质量的实时超分辨可以让数字变焦得到的拍摄质量和光学变焦相似,但是同时又避免了厚重的镜头;又如,inpainting/outpainting可以让用户快速编辑拍摄的照片并分享,能实现在手机上拥有和photoshop相似的效果,这也将会大大提升用户体验。
对于智能助理应用来说,目前主要还处于探索阶段,如何将多模态的信息(包括用户的短信、备忘录、日历等等)整合在一起并不容易,但是我们认为最终模型的形态最有可能还是类似GPT这样的大语言模型,通过海量数据与训练来实现对于用户数据的深入理解并且给出相应帮助。这类智能助手的*步落地应用可能是用户消息编辑和改写,例如用户可以让智能助手去改写一条短信以改变语气,这样的应用预计在明年就会落地。
手机生成式模型需要什么样的芯片
首先,我们从用于拍摄增强的图像生成式模型(LCM)开始分析,因为这类模型的应用较为明确。
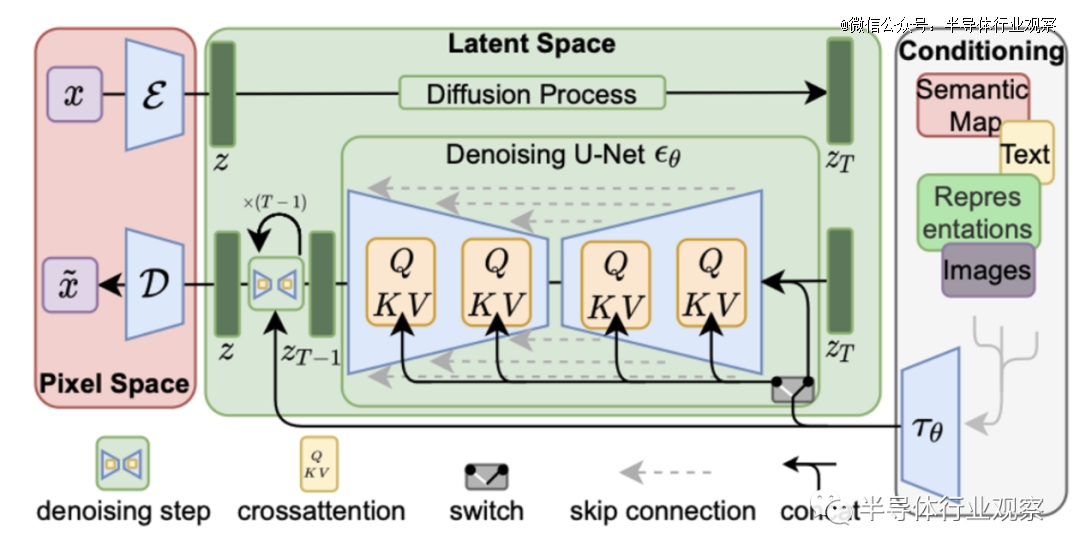
我们对于模型芯片支持的分析可以从算符、算力和内存三方面来入手。从算符来看,LCM或者Stable Diffusion模型使用的算符主要是常用的卷积和注意力(attention)层,这些算符在目前的手机芯片人工智能加速器中已经得到了非常好的支持。而在算力和内存方面,图像生成式模型的复杂度和模型尺寸都比现有的运行在手机上的人工智能模型要大一到两个数量级:LCM的参数量达到了10亿以上,而相对而言目前主流手机人工智能模型的参数量都在千万左右。如我们之前所说的,手机需要能实时执行这样的模型,因此需要在算力上满足模型的需求。
算力能满足需求可以从两方面来考虑,首先是增加人工智能加速器的峰值算力,主要的方法就是增加计算单元的数量。但是,计算单元数量的增加是以更大的芯片面积(即更高的成本)为代价的,为了能在成本和性能之间得到一个较好的折衷,需要能使用“性价比”更好的计算单元。在服务器的LCM版本中,使用的计算是基于32位或者16位浮点数的,但是在手机端执行时32/16位浮点数计算单元太贵,因此绝大多数的计算必须使用更低精度,例如8位定点数,或者8位浮点数9甚至是4位浮点数)。这里就涉及到了一个软硬件协同设计的问题,即如何在使用低精度计算的条件下同时确保模型输出质量不受太大影响,具体是使用8位浮点数还是8位定点数性价比更高等等,因此需要模型设计团队和芯片设计团队合作才能完成。另外,由于模型的尺寸远大于之前的主流模型到达了GB数量级,因此很可能需要手机的DRAM容量进行升级才能较好的支持。
除了DRAM容量之外,模型参数量大也意味着对于内存接口的压力更大(否则可能会陷入内存墙问题,让内存访问成为整体模型执行速度的瓶颈)。从这个角度,一方面可望将会推动手机芯片加速使用下一代内存接口(例如LPDDR6),而在另一方面也推动SoC使用更多的片上内存(SRAM)来缓解DRAM访问的压力。最后,在Stable Diffusion和LCM模型中广为使用的U-Net神经网络结构也拥有更多的中间结果(activation),为了能确保*的延迟和能效比,这也需要SoC片上有更多的SRAM来满足需求。
对于大语言模型来说,其对于手机芯片的需求也可以从算符、算力和内存来看。同样,算符方面大语言模型使用的主要算符是attention,目前已经得到广泛支持;主要挑战则是大语言模型的参数量甚至比扩散模型/LCM更大一个数量级,到了百亿数量级,这对于手机内存容量和接口速度都将造成巨大的挑战,而如果大语言模型真的能在手机得到大规模应用,预计将会大大推动手机芯片内存容量和内存接口的发展。此外,由于大语言模型的参数量太大,很有可能需要多级缓存,每次只会有一部分模型参数加载在DRAM中,还会有一部分会留在非易失性存储器中,因此内存和非易失性存储器的接口速度提升可能也会得到推动。
生成式模型对手机芯片市场的潜在影响
目前,我们看到手机系统厂商已经越来越重视生成式模型在手机端的应用。在最近的发布会上,知名手机厂商vivo和Oppo都把这类生成式模型作为下一代新手机的主要卖点,原因很简单,因为目前生成式模型已经到了能够真正成为核心用户体验的时刻了,而且模型技术也足够成熟,爆发在即。
手机芯片格局也可能会在这次的生成式模型热潮中发生微妙的改变。生成式模型的支持能力可能会成为和手机镜头一样重要的核心硬件卖点,但是生成式模型的最终解决方案其实是一个软硬件结合设计的方案,这样来说,其实对于有自研芯片能力的手机厂商来说是非常有利的,因为这些手机厂商可以通过同时掌握模型和硬件的设计,从而实现最高效率的解决方案,或者换句话说有可能通过深度的协同优化,即使在芯片实现工艺和性能较为落后的情况下,仍然实现很好的用户体验,这一点对于一些中国的手机厂商例如华为来说尤其有利,因为他们同时拥有深度的人工智能模型开发、手机系统优化和芯片开发能力,通过在自研的*方应用(例如拍照以及照片浏览)应用中加入自研的模型跑在自研的芯片上,有机会充分利用端到端优化的机会。
对于为手机系统提供芯片平台的公司例如高通和联发科来说,则需要提供完整的参考设计。在这方面,高通已经把手机端生成式模型提到了核心位置,在最近发布的Snapdragon 8 Gen 3中,高通宣布可以实现以低于一秒的延迟实现Stable Diffusion图像生成,未来可望进一步提升质量并降低延迟,接下来就看使用高通芯片的手机系统厂商如何利用这样的算力了。联发科也基于亿级参数大语言模型的特性,开发了混合精度 INT4 量化技术,结合公司特有的内存硬件压缩技术NeuroPilot Compression,以更高效地利用内存带宽,大幅减少AI大模型占用终端内存,为端侧运行AI大语言模型突破手机内存限制,助力更大参数模型在端侧落地。
另一个疑问是,云端生成式模型芯片领域目前的统治者Nvidia会如何看待手机生成式模型的机会?Nvidia在移动端的尝试自从十多年前的Tegra系列之后似乎就停滞了,但是今年年中Nvidia传出和联发科合作并且下一代联发科旗舰手机SoC可能会使用Nvidia GPU的消息,可见Nvidia在手机生成式模型领域还是有机会能切入。Nvidia在这个领域的优势主要在于模型开发生态,但是在手机生态(包括*方应用)中是否继续这样的优势,还需要联合SoC厂商以及使用该SoC的手机系统厂商深度合作,这样的合作能进行到什么样的程度,还需拭目以待。









