

在12月推出AI新品之际,英特尔CEO基辛格把枪口对准了英伟达。基辛格先是公开强调英伟达CUDA软件的护城河没有外界想象的那么深,接着在麻省理工的一场论坛上名褒暗贬,称英伟达在AI GPU领域极其幸运(extraordinarily lucky)。
基辛格把英伟达的成功归结为运气,并且认为好运曾站在英特尔那边。
他强调,英伟达最初拿GPU做通用运算完全没有考虑过AI。他不无可惜地提到,如果他当初没有被踢出英特尔,他看好的Larrabee项目就不会被终止,那么改变AI形态的可能是Larrabee,而不是CUDA。
Larrabee是英特尔早期开发的通用图形处理器(GPGPU),英伟达同期也在做类似项目,并在此基础上推出了CUDA平台。
基辛格的判断并非没有理由,他在13年前被迫从英特尔离开的时候,英伟达推出CUDA没多久。CUDA 1.0的早期文档中描述了通用计算的前景,涉及物理模拟、计算金融和计算生物学,确实没有AI的身影。更重要的是,帮助英伟达CUDA做深度神经网络库的高管就来自基辛格所说的Larrabee项目。
这位高管是英伟达现在的深度学习应用研究副总裁Bryan Catanzaro。但在基辛格发难之际,他在社交媒体X上表达了相反的观点。他认为,“英伟达今天的地位并非来自运气,而是眼光和执行力”。
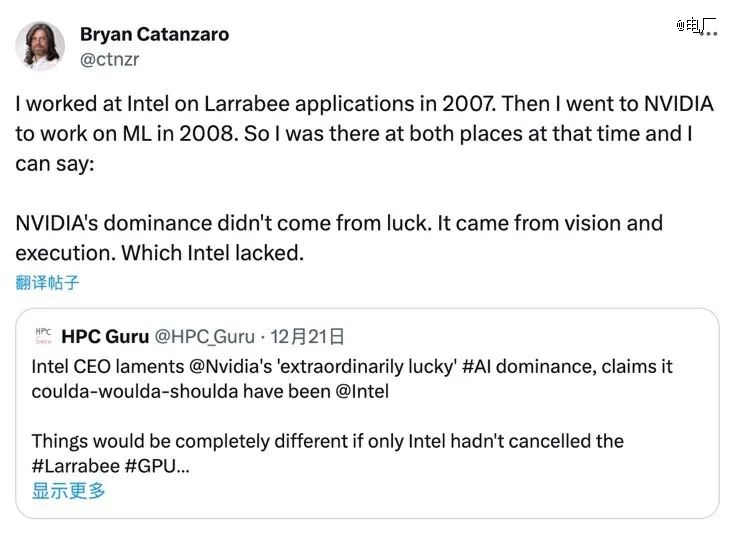
回看商业领域的企业浮沉,运气常常是被忽略的因素。99岁的芒格在生命的最后一段时间做出如此总结:“那些脱颖而出的人和公司,通常具备智慧、勤劳和大量的运气。”
翻看GPU和AI技术互动的历史,不难发现英伟达不仅有好运气,甚至好运气的周期足够长。问题是,支撑这种好运气的到底是不是“眼光和执行力”?
1、“泼天富贵”降临的时刻
今天英伟达一卡难求H100 GPU有两个主要买家,其中包括微软。根据Omdia Research的报告和瑞杰金融的估价,微软买了15万块H100,总花费在数十亿美元。考虑到H100供不应求的现状,可以说这钱是微软“求着”让英伟达收下的。
然而时间回到2011年,如果当时微软研发专家想采购一块1万美元的GPU,要遭到不少内部压力,即便这些GPU会被用在*商业潜力的项目上。不仅是微软,谷歌也一样,10年前认识到GPU能力的人和公司屈指可数。
2013年,谷歌人工智能主管了解到,公司挖角的深度学习研究员从不使用公司强大的数据中心,而是私自架一台GPU藏在工位下面使用。了解情况后,他申请1.3亿美元预算采购4万块GPU。科技记者Cade Metz在《深度学习革命》一书中记录,这笔预算遭到了管理层强烈反对,最后创始人Larry Page拍板才被通过。
更夸张的是,英伟达也没有完全认识到GPU的潜力,直到谷歌1.3亿美元的订单砸下来,才在深度学习领域有实质的业务布局。英伟达2014年的技术大会上首次出现了深度学习、机器视觉这样的主题。
2013年被认为是英伟达被命运选中的时刻,也是长达10年的“泼天富贵”的起点。然而英伟达不想把这天降的命运归结为运气,它坚持认为,2000年代中期就意识到了GPU在神经网络应用的潜力。
2、商业巨头合力改写历史
在今年的一篇博客文章中,英伟达把GPU应用于深度学习的成功案例追溯到2008年的一篇论文,论文来自于斯坦福大学教授吴恩达 (Andrew Ng)。吴恩达的小组得出结论,当时GPU在深度学习工作中的计算能力远远超过了多核CPU。他们使用两张GTX 280 GPU,训练具有1亿个参数的神经网络时,速度比使用CPU提高了70倍,训练时间从数周缩短到一天左右。
英伟达的编程软件CUDA在2007年推出,由于不是为了深度学习而生,研究人员需要借助CUDA把原本基于CPU的代码重写成GPU代码。吴恩达的这篇论文中有相当篇幅介绍CUDA的使用思路,因此在后来进入了英伟达的视野。
2008年,Bryan Catanzaro从英特尔来到英伟达,他认为自己是英伟达*个,也是当时*一个AI研究人员。Catanzaro在接受媒体采访时表示,他从纽约大学人工智能实验室得知,有一群机器学习研究人员在疯狂地为GPU核心编写软件。他受到启发,在当时的工作成果的基础上,催生了CUDA深度神经网络库(cuDNN)。
如果把CUDA比作AI的工作台,cuDNN就是AI专用的螺丝刀,cuDNN于2014年发布,是英伟达*针对深度学习的软件产品。
Bryan Catanzaro认为,真正让英伟达GPU在AI领域出圈的是一场比赛。2012年举办的ImageNet图象识别大赛中,首次参赛的AlexNet神经网络表现出超出人们想象的识别率而一鸣惊人。这次比赛引发轰动,被认为是深度学习爆发的初始事件。
AlexNet来自于有“深度学习之父”之称的Geoffrey Hinton和他的两个学生。比赛中,他们没有采用当时普通会用的计算机视觉代码,而是押注在深度学习上,让机器自学识别图像。当时最让人吃惊的是,AlexNet只用了两块GTX 580 GPU。谷歌同期的技术想要从图像中识别猫,需要用到数据中心当中的2000个CPU。
在此基础上,Catanzaro详细研究GPU和CPU的能力对比。他发现,当时2000个CPU的深度学习性能,只要12个英伟达GPU就可以实现。一系列突破和研究让商业公司窥见到深度学习的未来,硅谷巨头们,包括百度等科技公司开始着手用AI重构未来版图,GPU成为他们版图中的砖块,英伟达从此划出了第二条增长曲线。
然而需要强调的是,这个看起来完整的故事并非全部。在2012年之前,深度学习是一个很小的领域,商业公司的参与让这个小领域成了共识。反过来,由于商业公司以自己的视角参与和讲述其中的过程,也因此改变了历史样貌。
在一些研究人员看来,他们对GPU的认识和使用远早于商业公司的发现,在英伟达运气的背后,有着被遗忘的人与事。
3、一桩深度学习的公案
2012年,Geoffrey Hinton用AlexNet奠定了自己和两位学生在深度学习领域的地位。Hinton的其中一位学生在2015年进入OpenAI,他是2023年OpenAI“宫斗”闹剧的主角之一——IIya Sutskever。
IIya因为闹剧而走出实验室,被全世界的网友认识,成为科技名人。在闹剧最激烈的时候,吃瓜的Elon Musk发了一条推文,向网友介绍了从未出圈的重磅科学家Jurgen Schmidhuber。

Jurgen Schmidhuber是当今*的AI科学家之一。他在1997年发明的长短期记忆网络(LSTM)现在被用在绝大多数的语音识别和机器翻译产品当中,比如苹果的Siri、亚马逊智能音箱、谷歌翻译等等。
在他的个人博客当中,详细记录了自己团队对整个AI社区的技术贡献。他在博文中说明,GPT当中代表“Transformer”的“T”和代表“预训练”的“P”都基于他的团队的工作成果。这可能也是马斯克发表那条推文想表达的思想。
最让Schmidhuber耿耿于怀的,是让Geoffrey Hinton名声大噪的AlexNet。在他看来,AlexNet取得的成就基于AI社区的技术成果,不该拿走所有的光环。他提到同期的DanNet神经网络,DanNet更早使用了GPU训练,更早在比赛中超过了人的视觉识别能力,并且获奖更多。
电厂翻阅DanNet的资料发现,它来自于Jurgen Schmidhuber领导的团队,所参加的比赛往往直接服务于商业和科学应用,比如手写字识别、癌症医学图象识别等。DanNet首次获奖于2011年,且在2012年拿下了参加的所有比赛冠军。由于DanNet专注于参加识别大图像的比赛,因此没有在2012年跟AlexNet同台竞技。
外界基于从AlexNet开始的商业视角认识深度学习,把AI社区的荣誉加诸于Geoffrey Hinton身上,这让Schmidhuber感到不满。2020年,他试图通过《自然》杂志纠正这种现象,由此引发了AI社区在当年的激烈辩论。
这场公案也显示,用GPU训练神经网络在2011年就已经是成熟的方法。电厂根据DanNet早期论文发现,英伟达好运气的起点可以追溯到2000年初期。
4、被忽视的十年
上世纪80年代,AI研究从危机中走出来,各种新技术相继诞生。1986年Geoffrey Hinton的反向传播算法、1989年Yann LeCun的卷积神经网络、1997年Jurgen Schmidhuber的长短期记忆(LSTM)等帮助AI社区破冰。
进入2000年,这些新型的理论技术需要算力支持才能高效地投入研究,但基于CPU的工作往往要经历相当长的周期。幸运的是,学术界使用GPU从事数值计算的工作启发了神经网络研究人员。
同期,为游戏而生的GPU开始被迁移到Windows平台,游戏画面也从2D进入3D。为了应对需求,英伟达不断升级GPU性能。
GPU要在3D转换中运行大量矩阵乘法,这跟CPU的逻辑运算完全不同,却跟神经网络的工作过程非常相似。如果把CPU比作一个具有逻辑思维的成年人,GPU就是100个学会了加减法的小学生,神经网络训练需要后面这种方式。
电厂把时间追溯到2004年,当年出现的一篇论文中,研究人员使用ATI Radeon 9700 Pro显卡把神经网络训练效率提升了20倍。2005年和2006年,圈子里陆续出现测评论文,在奔腾处理器、ATI GPU和英伟达GPU之间做比较。2007年,英伟达推出CUDA软件简化了AI社区针对GPU的编程工作,成为AI社区的主要选择。
这时候,GPU训练的瓶颈出现在内存和GPU之间的数据传输环节。2008年吴恩达那篇论文显示,使用GTX 280 GPU的过程中,两个矩阵相乘所花费的总时间约为20毫秒,但实际计算只占其中的0.5%,剩下的时间都是传输数据的时间。
2010年,英伟达推出GTX480和GTX580显卡。虽然GTX480在游戏表现上因发热“翻车”,但由于引入了L2缓存,意外解决了之前GPU训练遇到的瓶颈问题。这代显卡成为了DanNet、AlexNet在训练上取得突破的硬件基础。
可以说,从CUDA到L2缓存,英伟达在GPU上的两次“无心插柳”的硬件设计,都击中了深度学习的需求,无意间参与到AI社区的发展当中。
总结来看,从2000年初期到2012年,英特尔、谷歌、微软等巨头成为科技的主导力量,但AI的漫长探索始终处在他们的盲区。这其中,英伟达“无心插柳”,但十年的周期足够一棵树长成一片森林。特别是2012年之后,英伟达在CUDA上的投入产生了更深远的价值。
如今,英伟达的AI芯片成了整个AI商业版图当中的砖块,基于CUDA的技术栈也成了砖块之间的水泥。看上去,在整个GPU生态中英伟达已经无可撼动。
然而就在这样的确定性时刻,依赖英伟达的科技巨头们反而暧昧起来,一方面加大跟英伟达的订单,另一方面纷纷推出自研芯片,微软推出了Maia 100,亚马逊更新了Trainium 2,谷歌的TPU v5p已经帮助节省了可观的成本。
英伟达H100这样通用GPU具备灵活性,及时补充了生成式AI爆发带来的需求。随着需求沉淀,AI商业社区在底层技术上一旦形成共识,对通用GPU的需求可能会让位给专用的TPU或者定制芯片。因此,比过去的任何时刻,英伟达都更加需要“无心插柳”的运气。








