

根据维基百科,高速缓存(英语:cache)简称缓存,原始意义是指访问速度比一般随机存取存储器(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。
当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器(Main memory)中读取数据——由于CPU的运行速度一般比主内存的读取速度快,主存储器周期(访问主存储器所需要的时间)为数个时钟周期。因此若要访问主内存的话,就必须等待数个CPU周期从而造成浪费。
早在PC-AT/XT和80286时代,并没有Cache,CPU和内存都很慢,CPU直接访问内存。但到了80386的芯片组增加了对可选的Cache的支持,高级主板带有64KB,甚至高端的128KB Write-Through Cache。
到了80486 CPU里面,则加入了8KB的L1 Unified Cache,当时也叫做内部Cache,不分代码和数据,都存在一起;芯片组中的Cache,变成了L2,也被叫做外部Cache,从128KB到256KB不等;增加了Write-back的Cache属性。Pentium CPU的L1 Cache分为Code和data,各自8KB;L2还被放在主板上。Pentium Pro的L2被放入到CPU的Package上。Pentium 3开始,L2 Cache被放入了CPU的Die中。从Intel Core CPU开始,L2 Cache为多核共享。
CPU的缓存曾经是用在超级计算机上的一种高级技术,不过现今电脑上使用的的AMD或Intel微处理器都在芯片内部集成了大小不等的数据缓存和指令缓存,通称为L1缓存(L1 Cache即Level 1 On-die Cache,*级片上高速缓冲存储器);而比L1更大容量的L2缓存曾经被放在CPU外部(主板或者CPU接口卡上),但是现在已经成为CPU内部的标准组件;更昂贵的CPU会配备比L2缓存还要大的L3缓存(level 3 On-die Cache第三级高速缓冲存储器)。
但直到现在,主流芯片还是止步于L3。
01 缓存的演进
据Quora博主,高级架构师Jerason Banes所说,之所以L4没被采用,这与CPU架构的发展有着莫大的关系。
他表示,如果我们如果将时钟回滚到 6502 CPU,您会发现这是一个非常简单的设计,在实际使用中也很精确,这主要是因为 6502 使用了冯·诺依曼架构。这是一个非常简单的结构,内存、CPU 和 I/O 都根据一个主时钟以锁步方式发生。
这意味着如果 CPU 以 1.4MHz 运行,则内存必须以 1.4MHz 运行,但这这很快成为一个问题。
他表示,随着 CPU 开始加速到 10 MHz,能够跟上的 RAM 变得非常昂贵。而事实上,从 RAM 到 CPU 的物理距离几乎不可能跟上 CPU。此外,RAM 容量的增加(兆字节大小)意味着需要使用更复杂的控制电路来寻址内存位置。这意味着当您非顺序地读取内存时,内存会变得具有不可预测的设置时间。
对此,行业提出的解决方案是保留少量 CPU 快速内存,这就是L1 缓存。现在,L1 + CPU 的行为就像旧的 6502 CPU 一样,但它可以调用 RAM,就像它是一个超高速硬盘驱动器一样,可以获取当前不在 L1 中的任何 RAM 块。就像硬盘驱动器一样,CPU 只会等待必要的数据被提取到 L1 缓存中。
这种方法之所以奏效,是因为程序的关键部分往往非常小。足够小到 CPU 在需要返回主内存之前可以花费大量时间运行程序。但美中不足的是——数据与代码。因为一个程序可能会处理大量数据。这会导致 L1 缓存的使用不佳,并导致缓存中出现大量“misses”。所以 CPU 会有效地减慢主内存的速度,这是可以接受的,除了 CPU 比这更慢的事实。
问题是 CPU 正在运行的代码很容易落入“最近最少使用”的桶中,并被淘汰出 L1 以支持正在处理的数据。一旦 CPU 返回到该代码块,它就必须停止并从主内存中重新获取代码。这是非常低效的。
为了解决这个问题,CPU 转向哈佛架构. (以早期的Harvard-1 计算机命名.) 在哈佛架构中,代码与数据保存在不同的内存中。这具有简化数据路径的优势,因为可执行代码来自一组路径,而数据来自另一组路径。更重要的是,通过将 L1 缓存分成两部分(代码与数据),数据永远不会意外驱逐正在运行的代码。
于是我们将 64KB L1 缓存拆分为 32KB 代码和 32KB 数据。
缓存的其余部分用于尝试处理越来越快的 CPU。CPU 时钟越快,电能在时钟周期之间的时间片内传输的距离就越短。由于这是一个无法克服的物理问题,CPU 设计人员开始从主内存“暂存”他们需要的数据。L2 的速度通常是 CPU 的一半,但尺寸更大,因此它可以在 CPU 本身繁忙时按顺序流式传输接下来的几个块。当 CPU 请求下一个数据时,它几乎不需要等待那么长时间,这就是我们获得 256KB L2 缓存的方式。
但是L3呢?那个是从哪里来的?
最后一块拼图来自多核处理器。每个内核都想继续工作,但如果每次需要从主内存中获取更多数据时它们都必须落后于对方,那么它们就做不到。因此,L3 缓存在每个内核上的不同 L2 缓存之间充当缓冲区。它将依次尝试为所有主内存调用提供服务,每次都会多拉一点,以增加在 L2 缓存请求时它已经拥有数据的可能性。这就是为什么 L3 的数量往往会随着核心数量的增加而增加。内核越多,它们就越有可能进入主内存的“战斗”。
资料显示,L3 缓存在 Nehalem(*代酷睿 i7 系列)中成为主流,这是*个单片四核 CPU 芯片,这意味着所有 4 个内核都在同一块硅片上。相比之下,它的前身 Core 2 Quad 由同一封装上的两个独立 Core 2 Duo 芯片组成。
02 为何止步于L4?
在这部分开始之前,我们必须申明,虽然L4目前没有被主流采用,但IBM早在2000年代就在其自己的某些X86芯片组中添加了L4缓存,并在2010年在System z11大型机的NUMA互连芯片组中添加了L4缓存。
据了解,IBM的z11处理器具有四个内核,每个内核具有64 KB的L1指令和128 KB的L1数据高速缓存,以及每个内核1.5 MB的L2高速缓存和在这四个内核之间的24 MB共享L3高速缓存。z10的NUMA芯片组具有两排96 MB的L4缓存,总计192 MB。
在谈到为什么没有用到L4缓存的时候,知乎用户tjunangang在一个问答下面回应直言——缓存太占地方,而且投入和回报不成正比,不划算。他表示,如下图所示,三级缓存差不多占据了两个核心的面积,如果加上四级呢?五级呢?要知道缓存容量都是急速递增的,如果有四级缓存,单独的缓存面积就比整个现有的CPU大。
在tjunangang看来,如果继续引入L4缓存,可能引致下述问题:
1.同样的晶圆,原本能生产32块CPU,加上四级缓存可能10块都生产不了,价格暴涨没人买账。
2.核心面积大,功耗大,发热量大,对散热设备要求高,与未来发展趋势对着干.. 而且核心面积大,良品率低,比较悲剧的是容易碎(我按碎过好多块)
3.堆缓存这种方式,明显是土豪作风,要知道intel早期处理器连L3 Cache都没有。而且关键的问题是,你单纯的堆缓存,早晚有一天会混不下去,和之前攀主频的竞赛类似,还不如想办法去提升架构。
4.对于整体性能的作用,L1 cache*,L2次之, L3甚至不到L1 cache的十分之一。若是不计成本的话,加到L4还有情可原,加到L5其实已经和系统内存差不多了。
知名博主“老狼”则表示,目前已经有L4了,它有两种形式,分别是eDRAM和Optane DIMM。例如在英特尔的Iris系列中,就有一块高速DRAM被放入Package中(eDRAM),它平时可以充当显存,也可以被设定为L4缓存。
曾经任职于Cray Research,Sun Microsystems,Oracle,Broadcom,Cavium和Marvell的芯片架构师Rabin Sugumar在接受nextplatform采访的时候表示,并没有人规定L4缓存必须由嵌入式DRAM(就像IBM对其芯片所做的那样)或更昂贵的SRAM构成。
根据他的观点,就目前而言,我们的L3已经很大。因此关于L4缓存,Rabin Sugumar也认为也许是eDRAM,甚至是HBM或DRAM。在这种情况下,一个看起来很有趣的是——L4高速缓存实现是将HBM用作高速缓存,而不是延迟高速缓存,而不是带宽高速缓存。
“这样做的想法是,由于HBM容量有限且带宽较高,因此我们可以获得一些性能提升,并且在带宽受限的使用案例中我们确实看到了显着的收益。缓存未命中数。但是,就性能和成本而言,需要做的数学就是添加另一个缓存层是否值得。”Rabin Sugumar说。
有那么多人发布如此多观点,在笔者看来,Intel才是其中的关键因素。在日前,他们带来了一个新的分享?
03 即将走向主流?
据外媒tomshardware报道,英特尔即将推出代号为 Meteor Lake 的处理器,将配备 L4 缓存的非官方信息已经流传了一段时间。而现在, VideoCardz 发现的一项新英特尔专利表明,英特尔已经准备好代号为 Adamantine L4 的高速缓存块,这将可用于某些 CPU。
“该 IC 可以在某些应用中与 AMD 的 3D V-Cache 竞争,但该小芯片不会仅用作性能助推器。”VideoCardz表示。
该专利表明,英特尔的 Adamantine(或 ADM)缓存不仅可以改善 CPU 和内存之间的通信,还可以改善 CPU 和安全控制器之间的通信。例如,L4 可用于改进引导优化,甚至在重置时保留缓存中的数据以缩短加载时间。
报道表示,虽然专利本身没有提到 Meteor Lake,但随附的图像清楚地展示了一个处理器,该处理器具有利用Intel 4工艺生产的两个高性能的 Redwood Cove 和八个节能的 Crestmont,此外还包括一个基于英特尔 Gen 12.7 的图形小芯片,还有一个包含两个以上 Crestmont 内核的 SoC 块,以及一个使用英特尔 Foveros 3D 技术互连的 I/O 小芯片。该描述对应于英特尔的 Meteor Lake 处理器。
同时,Adamantine L4 缓存可用于 Meteor Lake 以外的广泛应用。
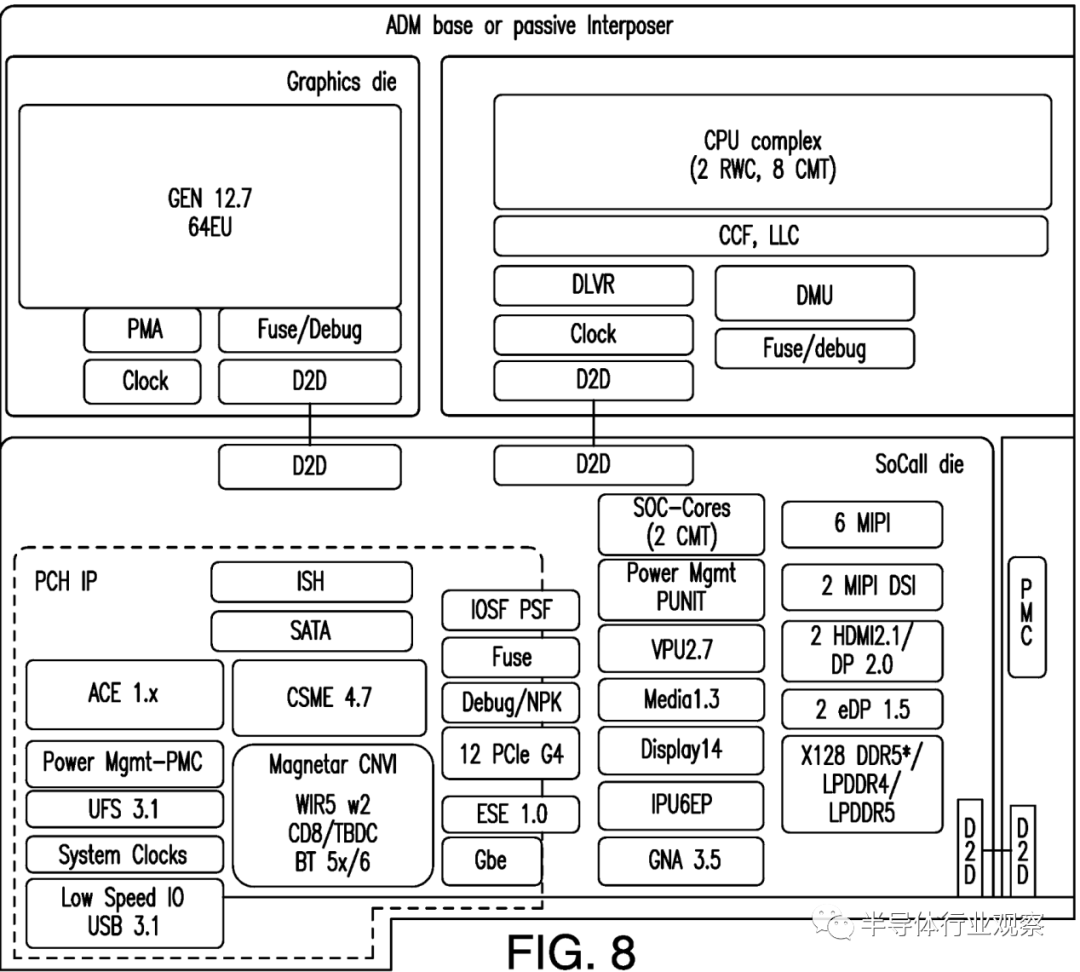
英特尔在介绍该专利的时候表示,下一代客户端 SoC 架构可能会引入大型封装缓存,这将允许新的用途。
他们认为,L4(例如,“Adamantine”或“ADM”)高速缓存的访问时间可能比 DRAM 访问时间短得多,后者用于改进主机 CPU 和安全控制器通信。实施例有助于保护启动优化方面的创新。重置时具有更高预初始化内存的高端芯片增加了价值,可能会增加收入。在重置时让内存可用还有助于消除传统 BIOS 假设,并为现代设备用例(如汽车 IVI、家用和工业机器人等)提供支持,这就推动产品走向新的细分市场。
也就就说,L4缓存要来了?










