

根据摩尔定律,每一代全新制程节点都会使晶体管密度增加一倍,而这一增速是提升芯片性能和降低制造成本两者妥协的结果。随着晶体管尺寸达到量子级别,仅依靠制程微缩带来的能效增益将被短沟道效应等副作用抵消,因此,需要其它技术优化手段,以用于芯片设计和制造。
其中一种技术路线是对晶体管结构进行创新,如应变调控、HKMG和新型器件结构;另一种路线是通过设计与工艺协同优化(Design-Technology Co-Optimization,DTCO)来实现芯片面积的缩小的同时,提升性能,并降低功耗水平。目前,DTCO已经成为实现先进制程节点性能目标的基本实现路径之一,台积电在其技术资料中多次提到,DTCO对5nm制程芯片性能提升的贡献超过了40%。
之所以提出DTCO,主要是因为越来越多的IC设计工程师遇到了同样的问题和挑战,即无论是在电路设计、物理设计,还是应用层面,都会引发影响整个系统的新问题:工程师可以像以前一样把晶体管设计得更快(高性能),但很快意识到这是以高功耗为代价的,这就需要加强设计和制造等芯片生成各环节之间的协作,才能共同优化整个芯片系统,以获得更高的PPAc(高性能、低功耗、小面积、低成本)水平。
通过DTCO,可以在芯片开发的早期阶段同时读取设计和工艺(晶圆厂制造阶段)。DTCO类似于DFM(Design for Manufacturing,一种考虑制造过程的设计方法),但二者有很大区别,DTCO 有助于预测设计(布局)产生的问题并优化工艺配方,还可以提高生产良率。
01、DTCO的发展史
DTCO并不是这几年才出现的新概念,只是因为近些年制程工艺难以按照摩尔定律的节奏前进,DTCO的作用和地位才凸显出来。
大约在2007年,当时,45nm制程技术引入了全新的栅极结构(HKMG),这种新的栅极堆栈能够克服随晶体管进一步微缩出现的漏电问题,但它也改变了晶体管的特性,其性能(电流和电压)开始出现偏差。随着进一步扩展,需要对设计进行更改以补偿这种偏差,可以说,这标志着摩尔定律自由发挥效用时代的结束,技术专家和设计工程师开始看到协作优化技术和设计的好处。也就是从那时起,业界提出了DTCO概念,当制程节点发展到20nm~30nm区间时,DTCO正式进入商业化发展阶段。
之后,制程工艺发展到10nm~20nm区间,为了开发1xnm技术节点,引入了结构微缩“助推器”,作为DTCO工作的辅助。这些“助推器”可以进一步减小面积,不是在晶体管级别,而是在单元级别,这里,单元是由晶体管构建的最小功能电路。结构微缩“助推器”的一个例子是自对准栅极接触,它允许将接触晶体管的栅极直接放置在晶体管的顶部,从而减少整体接触面积,这样,单元可以进一步微缩到极端紧凑的水平。
DTCO 巧妙地改变了逻辑单元的布局,以实现进一步制程微缩。当今的芯片中已经可以找到多种DTCO技术,例如,在隔离单个逻辑单元时,设计人员已将双扩散中断替换为单扩散中断,从而提供了明显的微缩优势,设计人员还实现了鳍片的减少,将每个晶体管的鳍片数量从三个减少到两个。还有,如上文所述,设计人员也在追求栅极上的接触,将晶体管的电接触从侧面移到顶部。
多年来,DTCO的价值愈加凸出,为了能够在晶体管微缩这条道路上继续前行,技术人员一直在探索为逻辑和存储器应用构建新晶体管架构,典型案例是台积电在16nm制程节点中引入了FinFET晶体管,其在微缩尺寸方面产生了比传统MOSFET更好的性能。同样,对于存储器,imec等研究机构探索了多种新技术,以取代一些传统的存储技术。
目前,除了DTCO,业界还发展出了系统工艺协同优化(System Technology Co-optimization,STCO)。
STCO可以做DTCO难以做到的事情,例如,可以减少逻辑和SRAM单元面积,而不依赖于器件的尺寸微缩。STCO还可以优化不可见的SoC功能,例如供电。
02、DTCO面对的挑战
虽然DTCO能够解决一些摩尔定律解决不了的问题,但它也不是*的,特别是市场对高性能芯片的综合水平的要求越来越高,DTCO也面临着诸多挑战,具体包括:由于DTCO的数据来自不同软件而非单一平台,因此难以整合和汇总这些数据;很难将每个技术元素连接起来,因为仅在一个地方收集的数据不仅复杂,而且范围、规模和抽象程度不同;优化本身难以计算,因为变量多且复杂。
目前,先进制程设计的挑战在于:扩展不再仅仅基于制程节点级别的增量变化,DTCO需要考虑对单元库的影响,以及对布局布线设计的影响。这显然比仅仅开发一个PDK,且设计人员使用它的方式与他们使用之前节点几乎相同的方式更复杂、更昂贵,尤其是在所有事情都必须手动完成的情况下。
DTCO最初专注于设计规则优化,然后升级到标准单元逻辑布局(特别是减少在垂直维度上采用的金属轨道数量),现在涵盖整个物理设计流程,因为可布线性严重依赖工艺特征。
即将实现量产的3nm制程,已经达到了FinFET缩放的极限,一个很大的问题是:接下来的环栅(GAA)、CFET(堆叠N和P晶体管)、垂直栅极等晶体管架构,会出现什么新的问题?还有一个需要考虑的因素是埋入式电源轨 (BPR) 或前端供电,以及对布局有重大影响的其它选项。这些都是DTCO要面临的挑战。
当然,未来的先进制程工艺芯片设计要面临的挑战不止以上这些,将对IC设计工程师提出更高的要求,DTCO也必须与时俱进,这就需要芯片产业链各环节,特别是EDA、半导体制造设备,以及晶圆厂能够提供更好的工具、设备,以及服务,才能保证DTCO继续发挥优秀效用。
03、产业链协同,各施绝技
DTCO就是IC设计厂商、EDA工具厂商、半导体设备供应商,以及晶圆代工厂等芯片产业链各环节之间的更深度合作,达到你中有我,我中有你的“技术渗透”效果,例如,IC设计厂商及其工程师必须对晶圆代工厂的制造工艺及相关参数有更全面和深入的了解,半导体设备供应商必须能为晶圆厂提供可以解决IC设计客户问题的方案,而EDA工具厂商则要与IC设计和晶圆厂双向深度整合,提供DTCO所需的工具支持。
首先看EDA。
前些年,当7nm制程即将量产之前,imec和Cadence就对7nm和5nm制程芯片的设计做过联合研究,以分析IC设计工程师的各种潜在决策对EDA工具和库的影响。具体方法是使用真实设计运行多个实验,并了解这对设计质量的影响以及它如何影响PPAc(性能,功率,面积和成本),结果与imec生态系统(每个做高级工艺开发的工程师)共享。
这些研究不断迭代,以共同优化流程和工具,具体内容如下。
采用标准单元设计的反馈环路:如果存在非常多的DRC错误,则需要更改库的架构;如果只有几个,那么这些单元应该重新设计。
器件反馈回路:为各种器件选项提供PPA信息,以便做出正确的选择。
包含材料/BEOL选择的反馈回路:使用PPA信息查看导体和电介质选择的芯片级影响。
反馈回路与光刻,设计规则:比较不同图案化选项的效果。
EDA循环:当时工具的beta版本即将使用,需要对工具进行增强和调试。
通过这些EDA工具优化,可降低制造成本,事实证明,使用imec成本模型,相应的晶圆成本降低了5%。当时,imec的7nm设计在晶圆代工厂风险生产前约两年完成,之后,Imec进入了下一个制程节点研发工作流程,而上一代产品则在代工厂启动,工艺良率得到优化,为批量生产做好了准备。
另一家EDA和IP大厂Synopsys也很重视DTCO,该公司开发了虚拟PDK,以加速新制程节点评估。虚拟PDK对于弥合技术建模和设计实现环境之间的差距很有价值。虽然不像晶圆代工厂发布的PDK那样功能齐全,但这些虚拟PDK可以通过基于仿真的方法快速生成,以便在晶圆厂PDK发给设计团队之前实现设计实现和设计分析。
这些虚拟PDK包含的关键功能包括:创建用于电路仿真的紧凑型模型;能够在定制设计上运行晶体管级寄生提取;能够在块级设计上运行栅极寄生提取;为综合、贴装和布线解决方案创建技术文件。
该公司的DTCO方案可以通过其技术开发平台的自动化来生成这些虚拟PDK,从而实现技术和设计环境之间的无缝链接。
再来看半导体设备供应商。
这里以全球*的半导体设备供应商应用材料为例。针对DTCO,该公司发布了基于TCAD(Technology Computer Aided Design,计算机辅助设计技术,此处特指半导体工艺模拟以及器件模拟工具)技术与MSCO平台。该平台将DTCO以晶体管结构为主要优化对象的范围拓宽到MOL/BEOL环节的材料、工艺方法和设计端的design rules等影响因素的更广大范围,通过TCAD模拟测试技术形成了一个综合的协同优化解决方案,可进一步提升先进制程芯片的PPAc水平。
在新工艺的开发中,TCAD工具可大大降低开发的成本和周期。传统基于TCAD的DTCO技术流程中,FEOL前道工艺的调参与器件仿真都是通过TCAD完成的,更先进的modeling-based TCAD不仅包含传统DTCO中电气特性建模功能,还整合了MOL中道工艺和BEOL后道工艺中寄生电容和电阻参数提取功能,这种涉及芯片内互连线路的优化,就是前文所述的STCO。
为此,应用材料开发了“材料到系统的协同优化平台”(简称MSCO)。
MSCO在传统DTCO基础上综合考虑了器件级影响因素(器件架构、工艺步骤、材料等)和设计级影响因素(design rules、标准单元内track数量、功率分配),将协同优化的覆盖面拓展到系统级模拟,并且能够快速评估主要的技术参数及其对整个电路系统的影响。
为了展示MSCO平台的应用价值,应用材料针对各种FEOL前道工艺、MOL中道工艺、BEOL后道工艺进行了实验测试,并展示了各种工艺参数调整对器件和电路性能的影响。具体测试内容和参数就不在此赘述了。
最后看一下晶圆代工厂。
这里以台积电为例。该公司即将量产3nm(N3)制程芯片。与N5相比,台积电的普通N3的性能提升了10%。与普通N3相比,N3 HPC性能提升了3%,再通过HPC DTCO优化,速度又额外提升了9%,总共达到12%。该测试设计基于Arm Cortex-A78。
台积电一系列HPC优化单元可提供更快的触发器、双高单元和使用通孔柱的单元。
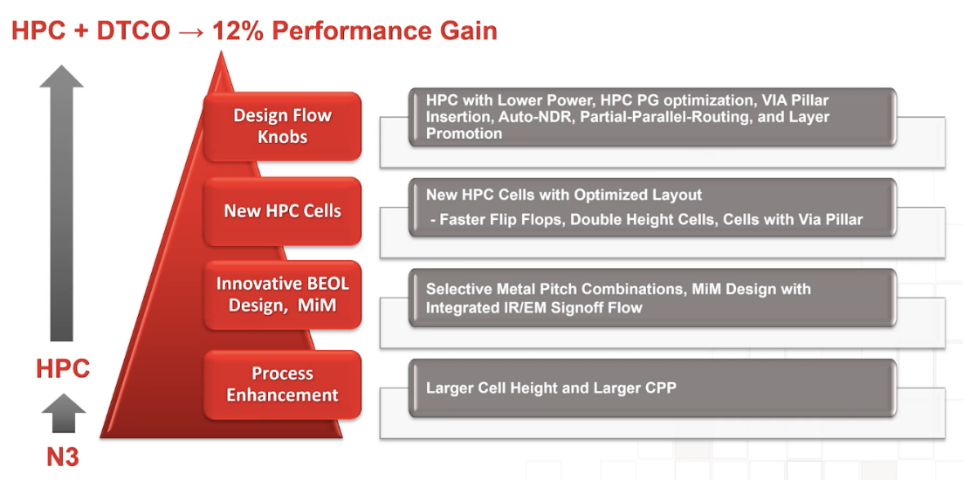
如上图所示,红色区域由下向上分为四部分,具体优化情况如下。
工艺改进:(更大的 CPP 和更高的单元)速度比现有的HC单元提升10%(在相同的功率下)。
以HPC为中心的BEOL设计应对更长的互连和相应的线延迟通常是一个巨大的挑战。在移动设备中,由于需要进行密度缩放,因此使用了最小金属间距。然而,HPC 应用通常需要更大的金属间距(更低的RC)和更大的通孔(更低的电阻)。台积电创建了特殊的金属间距组合和设计规则,以对PPA进行更好的权衡。结果是性能提高了2%-4%。
MiM在HPC设计中对于防止电压下降和提高性能至关重要,因此,台积电创造了一种超高密度 MiM,既具有良好的密度,又具有良好的频率响应。这减小了压降,使性能提升了约3%。
另外,标准单元库随架构和布局优化的变化,可使性能提升约2%。对库的更改包括:针对更低电容和更高速度的M0优化;用于高驱动单元的双高度单元;优化多级组合单元的定量和性能。
除了提高性能,也可以使用DTCO获得更低的功耗。台积电可以保持10%的性能提升,但面积更小,功耗还可以降低15%。面积减小有助于提升逻辑密度,由于导线更短(R 减小),也有助于提高性能。
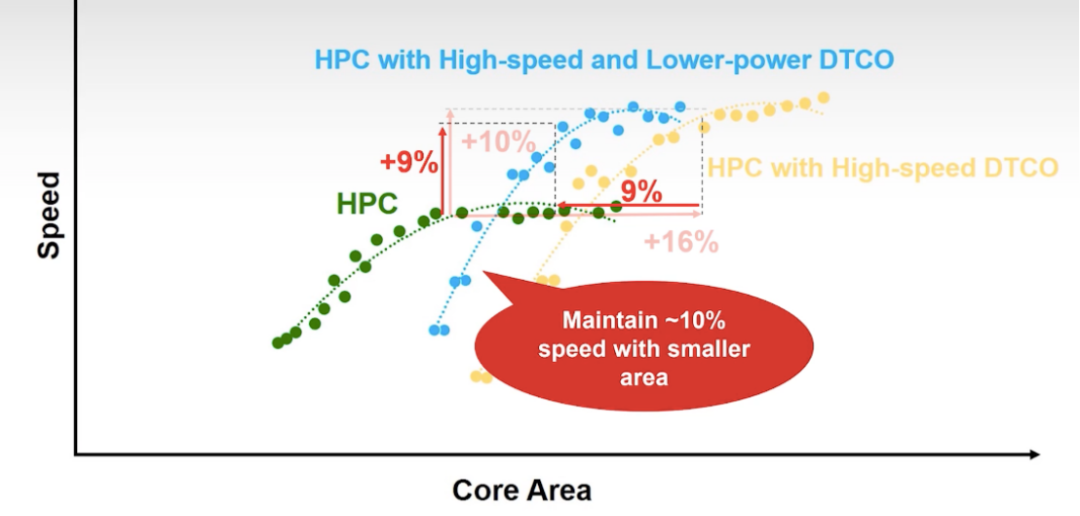
对于 HPC 设计,配电网络 (PDN) 变得越来越重要。这是减少IR压降,从而提升性能的关键。台积电开发了一种特殊的设计流程,它以更集中的方式分配电源和接地,从而为信号路由腾出空间,减少障碍。此外,时钟网络布线性能更好,偏斜减少,从而带来更好的性能。
04、结语
DTCO越来越重要,但要想做好绝非易事,制程研发团队与IC设计研发团队一开始就必须携手合作,针对下一代技术的定义进行DTCO,两个团队必须保持开放的心态,探索设计创新与制程能力的可能性,许多创新的想法都在这个阶段被提出来,其中有些想法可能因为太超前而无法通过已有技术实现,有些想法乍看起来很有潜力,但是结果却没那么实用, DTCO的目的就在于定义真正有意义的调整,超越单纯的几何微缩,进而达成提升整体效能的目标。
台积电先进技术业务开发处资深处长袁立本认为,完成DTCO参数定义后,下一步则是找出“制程窗口”的极限,通过来回的、密集的互动过程调整,定义制程的范围边界以达成*的效能、功耗、面积,并仍可以高良率量产。
为了确保DTCO创新带来的性能、功耗、面积优势能够应用在客户的产品上,IC设计厂商必须与EDA工具开发商、晶圆代工厂紧密合作,另外,半导体设备供应商也必须深度参与到晶圆厂的工艺和PDK研发工作中。这样,无论是EDA工具,还是半导体设备,都能够精准符合新的制程工艺设计规则,充分利用新的技术优化来进行设计优化。
半导体产业链上各环节诸多厂商越来越重视DTCO,其未来的价值和意义将更大。本文只列出了EDA工具、半导体设备和晶圆代工厂这三个环节中*企业的DTCO案例,实际上,不止这几家,有越来越多的厂商深度参与了DTCO。
有了DTCO这个“外挂”,摩尔定律这场“游戏”或许能玩得更久。









