

Sora的技术文章发布之后,OpenAI用的一个词却在学界引发了不少的争议,这就是“世界模拟器”(World Simulator)。
01
关于世界模型的争议
目前,很多外界的舆论将OpenAI称Sora为的这个“世界模拟器”和“世界模型”相关联起来。
那么,什么是世界模型?为什么大家的期待这么热烈呢?
世界模型的概念最早也最常出现在机器人领域的论文中。2018年,两位名为David Ha和Jürgen Schmidhuber的学者发布了一篇名为World Models的文章,这篇文章也被Sora的技术解释论文所引用。

在这篇文章里,作者并没有对World Models给出一个明确的定义,但是却引用了一篇系统动力学之父Jay Wright Forrester发布于1971年的有关人脑mental model的文献来进行类比。Forrester指出,人类使用有限的感官感知世界,并基于这些感知建立起一个内部的、简化的世界模型。我们所做的决策和行动都是基于这个内部模型。

在这个mental model中,并不包含世界上的所有信息或细节,而只是包含了被我们选中的某些互相关联的概念。换句话说,人们在头脑中构建的世界图像是现实世界的一个简化版,这个简化的模型不仅帮助我们理解世界,更重要的,我们还会根据这个头脑中的简化世界决定预测未来走向。
而世界模型也采用了类似的思维模式:在有限的、有选择性的信息基础上进行有效的决策和预测。更重要的是,和人脑一样,世界模型不仅需要预测立即的结果,还要能够预测更长时间序列的后果,这对于理解复杂环境和规划长期策略至关重要。

具体到模型架构上,根据图灵奖获得者、Meta的首席AI科学家Yann LeCun的定义,一个世界模型应该包含以下元素:
1)观察(x(t)):这是你在给定时刻对世界的看法或感知。想象你在玩视频游戏,看到你的角色站在一个平台上。那就是你的观测。
2)状态估计(s(t)):模型对当前世界状态的估计。就像你在游戏中有一个关于一切所在位置的心理地图,即使你现在看不到全部。
3)动作建议(a(t)):模型可能提出的行动方案。这是对下一步要做什么的建议,比如决定跳跃到另外一个台阶上。
4)潜在变量建议(z(t)):用于表示当前观察不能完全解释的未知信息。这就有点棘手了。它代表所有未知因素,这些因素可能影响你行动的结果。想象游戏中有风,当跳跃时风可能会把你的角色吹偏。你看不到风(它是未知的),但你知道它可能影响你的跳跃。

Yann LeCun认为,世界模型有两个组成部分:编码器(这个函数接受你的观测并将其转换成模型可以更有效工作的格式或表示),和隐藏状态预测器(利用编码后的观测、当前的世界状态、你正在考虑的行动和未知因素(潜在变量)来猜测接下来会发生什么,以此来预测世界的未来状态)
Yann LeCun定义下的世界模型之所以强大,是因为它试图模仿智能生物与世界的互动方式:观察、理解、预测和行动,同时也考虑未知的事物和因素。它是一个综合框架,可以应用于从玩视频游戏到导航现实世界环境的各种问题,目标是创建能够学习以对未知因素具有适应性和鲁棒性(在异常和危险情况下系统生存的能力)的方式导航和与复杂环境交互的模型。
是不是觉得以上的解释非常复杂很难懂?没关系,AI生成视频公司runway在去年年底出了一个还挺有趣的视频,更简单易懂的解释了世界模型。

也就是说,世界模型就像狗狗一样,对所有的视觉,听觉和一切数据的关系,这个模型能弄清楚如何预测结果,以及调整它的行为。而更重要的是,世界模型要能和狗狗一样,对新的、没有见过的数据也能形成泛化的理解,也根据它对世界的理解,从而对未来做出预测。
也就是说,我家狗不仅会对它爱吃的零食流口水也会拽我去它*的狗公园,同时,它会对它从来没吃过的东西流口水,或者,去拽着我去一家它从来没去过的宠物零食店。

所以,在理想状态下,训练出的世界模型不仅能够复制它看到的数据,更能够理解数据背后的因果关系,并在新的情况下做出有效的预测。如果把世界模型的概念套用到视频生成领域则可以理解为,这个模型能够让机器像人类一样,对世界产生一个全面而准确的认知,从而生成更流畅、更符合逻辑、时间更长的视频。
所以,就在此前GPT和diffusion等模型路线无法达到能让业界商用的标准时,很多行业人士是对“世界模型”抱有极大期待的,包括了好莱坞等影视*团队。
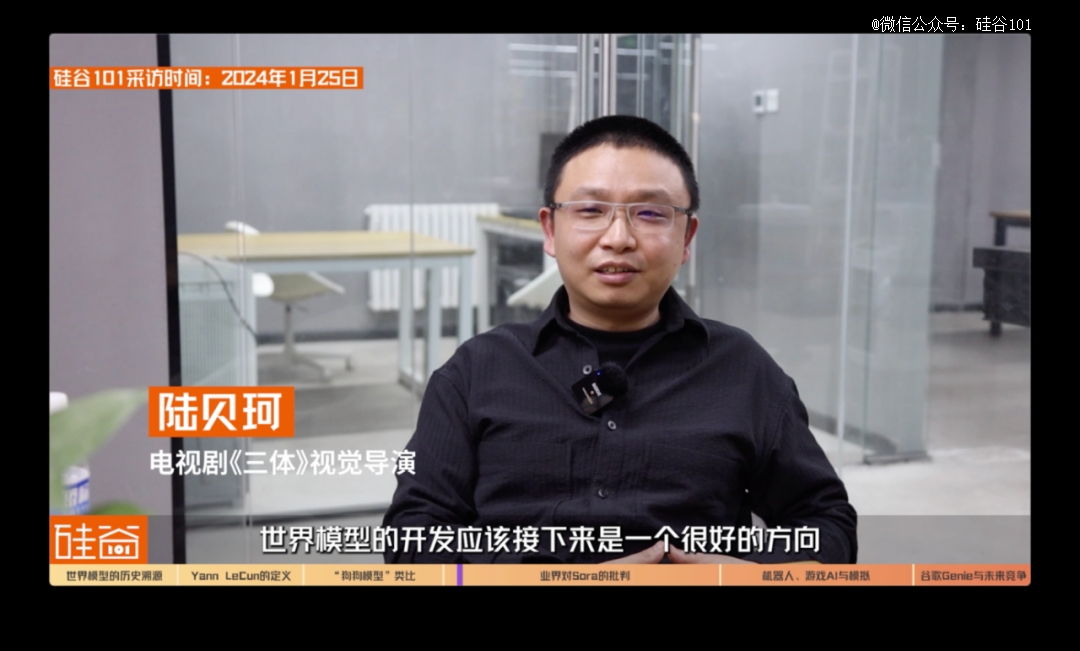
陆贝珂,电视剧《三体》视觉导演:
世界模型的开发应该接下来是一个很好的方向,因为世界模型*的一个核心其实是,让它真正地认识到那些不可约化的东西,还有你认识到自身的边界在哪。因为你做任何的事情它是有一种框架性,对吧?你真实的世界就是这样的,真实世界它的框架来自于,大量的物理事实和人际关系的情绪事实,这个世界运转时候的一种这种政治逻辑,对吧?
这是几种很多东西,这是你的世界的框架,你如果只是从语言的角度去理解世界的时候,你就发现不了这个世界真实的那一个框架。这部分现在我觉得在GPT4的这个级别上,因为它是属于语言模型,它还没有达到说后面的开放式的世界模型的这种级别,那看起来OpenAI一直在这方面努力。
以Yann Lecun的定义,Sora目前是远不能达到世界模型的标准,而更多的学界大佬对则认为OpenAI有夸大宣传的嫌疑。Yann LeCun本人就曾多次公开“狠批”Sora,表示“生成视频的过程与基于世界模型的因果预测完全不同”。
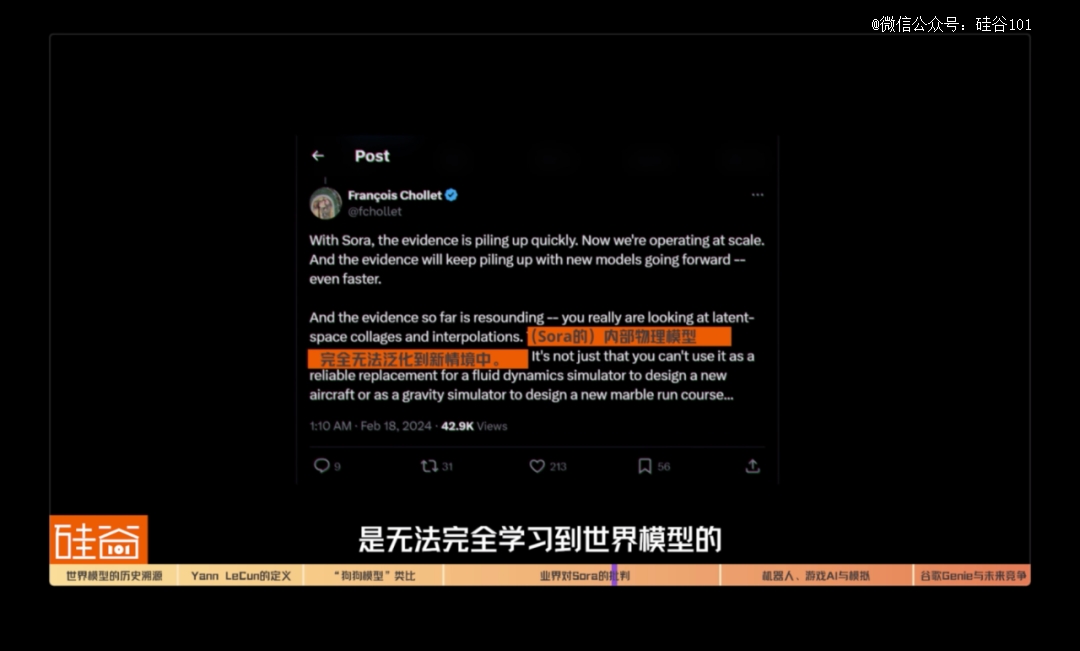
Keras之父François Chollet也持有相似观点。他认为仅仅通过让AI观看视频是无法完全学习到世界模型的。尽管像Sora这样的视频生成模型确实融入了物理模型,问题在于这些模型的准确性及其泛化能力——即它们是否能够适应新的、非训练数据插值的情况。而目前,因为完全不清楚Sora的demo视频与训练数据的差异有多大,Sora的泛化能力到底有多强尚不可知。而在已经发布的demo里,已经有人指出了不符合物理规律之处,这就表明,不论如何Sora物理模型的生成能力还未达到令人信服的可靠水平。
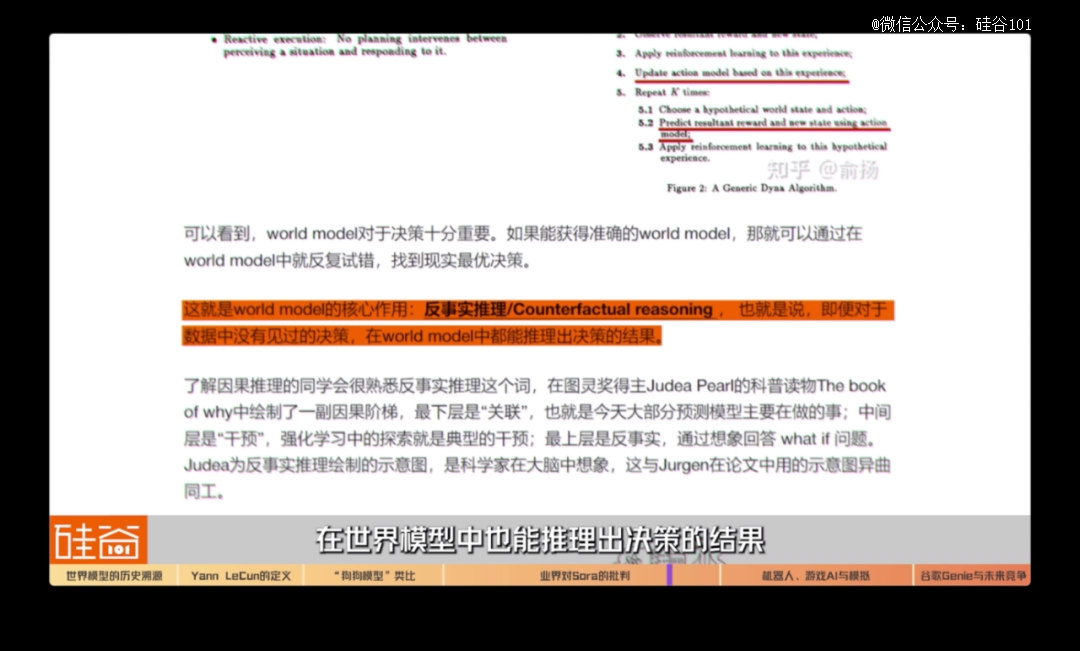
南京大学人工智能学院教授俞扬也反对将Sora归类于世界模型。他提出,世界模型的核心在于反事实推理(Counterfactual reasoning),即便对于数据中没有见过的决策,在世界模型中都能推理出决策的结果。Sora生成的视频,仅能通过模糊的提示词引导,而难以进行准确的操控。因此Sora就是一个视频工具,难以作为反事实推理的工具去准确的回答what if问题。
至于OpenAI未来究竟能不能推出真正的世界模型,Yann LeCun和Chollet都表达了质疑态度。Chollet提到,如果按照目前OpenAI所采用的“大数据、大模型、大算力”的暴力美学路线,是不可能构建出能广泛适用于现实世界所有情况的模型,因为现实世界的复杂度和多样性远远超出了任何模型通过有限数据所能学习到的范围。
然而,业界也有一些积极的声音。在英伟达研究院高级研究员Jim Fan看来,Sora已经是一个世界模型,包含了世界模型所需要的所有元素。Jim Fan在LinkedIn上转发了Yann LeCun对世界模型的定义,并评论说:
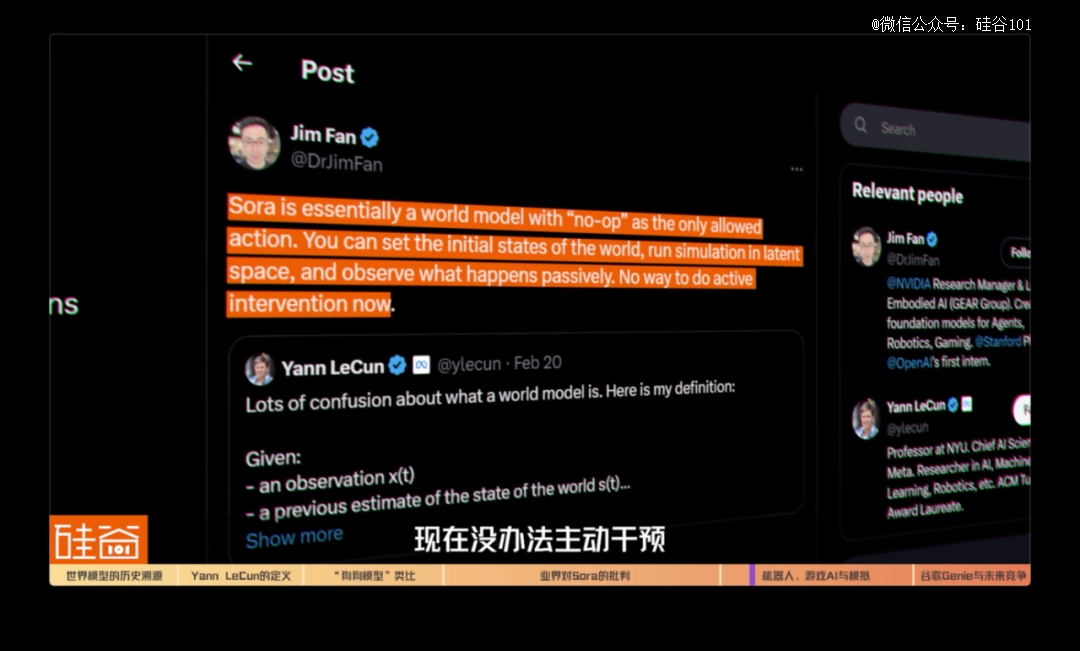
Sora本质上是一个世界模型,“无操作”是*允许的操作。您可以设置世界的初始状态,在潜在空间中运行模拟,并被动观察发生的情况。现在没办法主动干预。
但能否主动干预,OpenAI官方似乎是有一些不同的说法。但无论如何,Jim Fan对Sora能成为世界模型的乐观是可以理解的。AI视频生成的用途绝不仅仅在娱乐和艺术创作上,视频数据可以捕捉到难以用语言表达的物理世界中的重要信息和数据,这将在AI智能体,AI机器人,计算引擎,环境模拟器,生成游戏环境等等科学和工程研究中,极大程度推动相关科研的发展。
最近英伟达宣布,Jim Fan将在英伟达内部领导组建一个新研究小组,GEAR,是“Generalist Embodied Agent Research”的简称,中文是“通用具身智能体研究”。
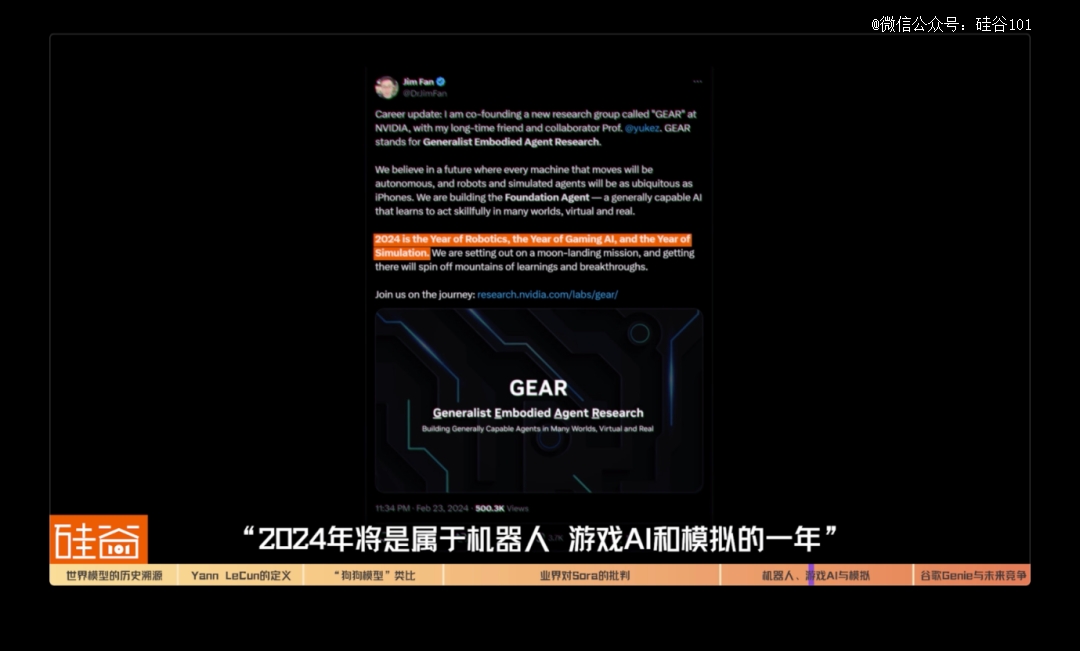
Jim Fan在推特上写到,“2024年将是属于机器人、游戏AI和模拟的一年。”
如果大家去看看硅谷101之前推出的《AI机器人》那期节目,在结尾的时候就说到:具身智能机器人在现实世界训练太困难,采集数据太慢太昂贵,而在模拟器中训练将是重要的研究方向,包括斯坦福著名的人工智能学者李飞飞教授就是这一流派的倡导者,而Jim Fan当时在斯坦福时正是李飞飞的博士生。

顺便说一句,现在苹果的Vision Pro也出来了,业内人士认为这将是很好的采集现实空间数据的仪器。
因此,“模拟”Simulation对机器人和智能体行业都将有着重要的意义,而Sora,如果成为“现实世界模拟器”,将极大的助力这个行业的发展。这一点,我们也从斯坦福非常热门的炒菜机器人团队Aloha的创始团队那里得到了肯定。

Tony Z.Zhao,斯坦福大学开源机器人Mobile ALOHA项目联合负责人:
这肯定会很有帮助,或者说任何一种更大规模的pre-training(预训练)都会大有帮助。例如,在这种情况下,杯子就像是半透明的。在测试时,如果我扔一个蓝色的杯子,它就不会工作。但是,如果我们期待一个正确实施的互联网pre-training(预训练),与这个数据集相结合,或者在蓝色杯子上工作,也不是没有道理的。因为也许世界模型中捕捉到了一些常识,它会告诉你,无论杯子是蓝色、红色还是半透明的,处理它的方法都是一样的。因此,我会期待这样的世界模型能在泛化方面带来进展。
近期,来自Google DeepMind的研究科学家 Sherry Yang及其团队,联合业界资深研究员在一篇题为“Video as the New Language for Real-World Decision Making”的论文中,探索了视频生成技术在机器人,自动驾驶和各类科学领域研究的重大用途,并总结说:视频生成之于物理世界,就如同语言建模之于数字世界。

所以,到这里我们总结一下,Sora可能并不是一个成熟的产品,它还没有到ChatGPT时刻,现在可能算得上是GPT3时刻,但OpenAI对Sora的官宣让我们看到了生成式AI视频最前沿的技术流派进步,以及用高算力和大参数也能达到“涌现”的技术突破。同时,在AI机器人和具身智能等学术和研究领域,大家很期待Sora能助力更多更高效的研发,而至于Sora距离商用还有多愿,我们得先等Sora正式发布,大家都用起来,才能知道了。
但同时,生成式AI视频大模型的竞争才刚刚开始,虽然OpenAI目前展示了*的*地位,远超runway和pika等一众创业公司,但谷歌也紧追其后。就在2月28日,谷歌Deepmind发布了新的可交互视频生成模型Genie。

这款名为 Genie 的新模型可以接受简短的文字描述、手绘草图或图片,并将其变成一款可玩的电子游戏,游戏风格类似于超级马里奥等经典的 2D 平台游戏。虽然Genie只是一个内部研究项目也暂时不会对外界发布,但业内人士认为,我们可能很快会看到Genie的3D版本,也会有基于视频生成的游戏引擎,而这也清楚的向外界透露,和OpenAI一样,谷歌等一众科技巨头在生成式AI视频上的野心绝不仅限于视频用于娱乐,而在虚拟环境中训练机器人,才是更重要的星辰大海。
以上就是我们硅谷101对Sora以及生成式AI视频大模型发展的简单梳理,为了更简明的解释技术,我们将很多技术细节稍有省略和简化,如果有描述不准确、类比不适合的地方,欢迎大家多多指正和探讨。









