

2024年2月16日,OpenAI发布自己的*AI视频生成模型Sora,继ChatGPT后再次展现了大模型强大的泛化能力。大模型的持续迭代升级催生了对算力基础设施的大量需求,二级市场英伟达市值也屡创新高。本文将从大模型发展趋势出发,分析大模型时代算力和存储产业的新机遇,并提出相应的投资意见。
大模型浪潮席卷
AI领域竞争焦点集中于算力
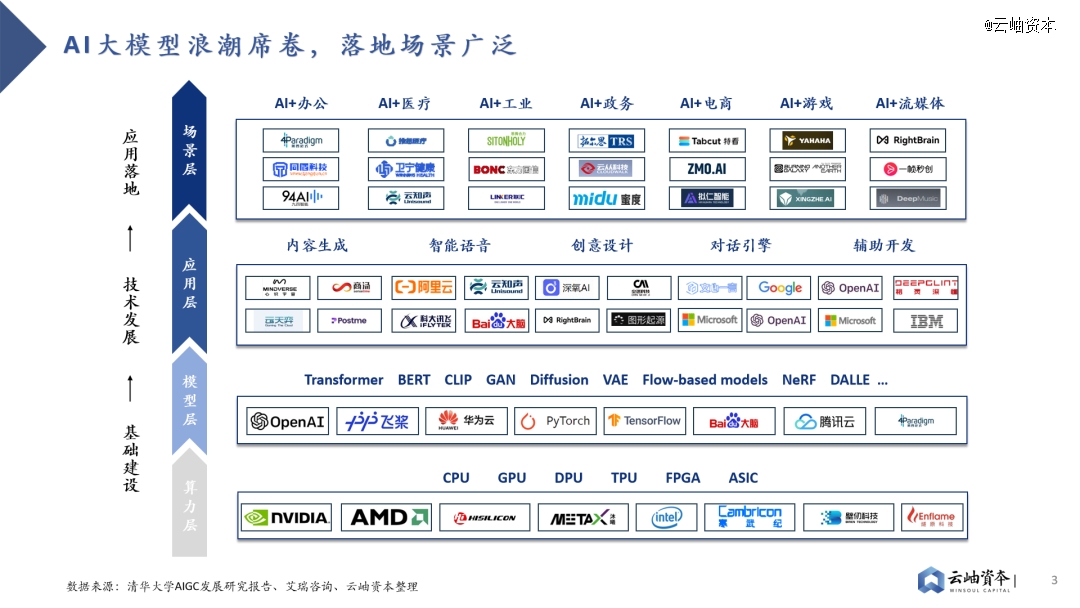
目前,AI大模型+的浪潮正在席卷各行各业,展现出无限可能。在各类算力模型的基础上,业界已开发出了内容生成、智能语音、创意设计、对话引擎和辅助开发等功能,并应用于办公、医疗、工业、政务、电商、游戏、流媒体等多元化场景。
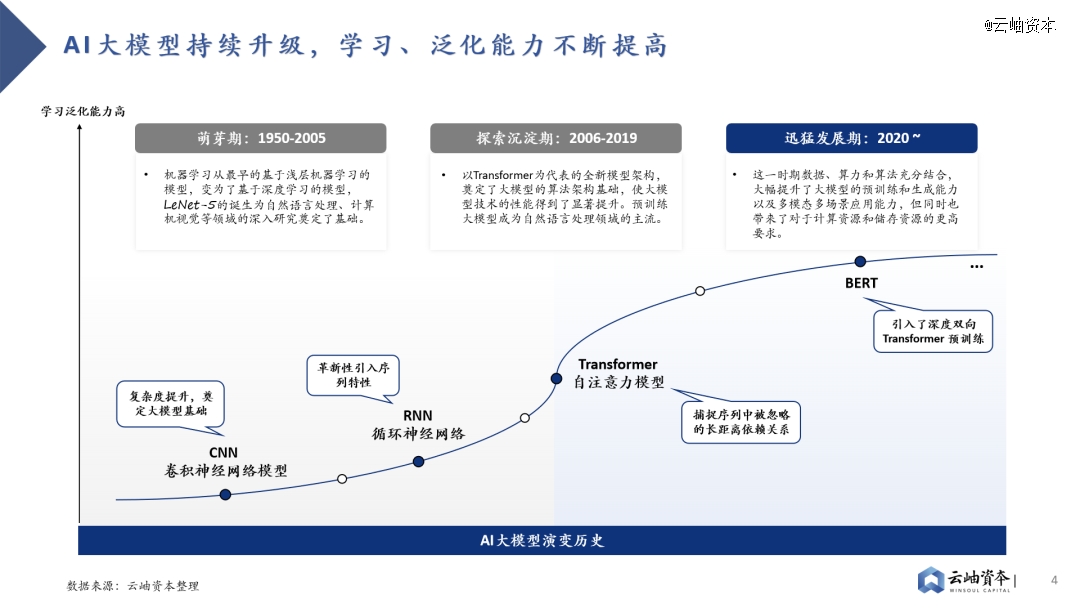
AI大模型的发展经历了萌芽期、探索沉淀期和迅猛发展期三个阶段。在萌芽阶段,浅层机器学习向深度学习转化,孕育出重要的CNN和RNN模型。2017年,Transformer的问世奠定了如今主流大模型的算法架构基础,预训练大模型开始登上历史舞台。随着Google发布BERT模型、OpenAI发布GPT模型,AI大模型彻底进入井喷时代,全球科技公司不断探索大模型的能力边界。
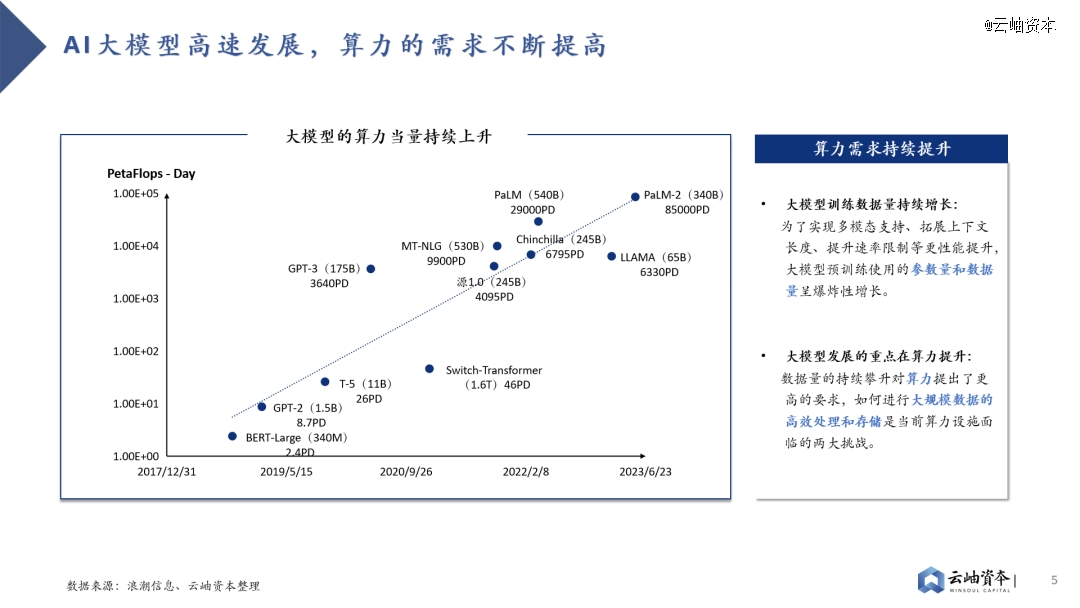
近年来,伴随着各个大模型的涌现,模型运算量的增长速度已经将摩尔定律远远甩在身后。目前,大模型正在往多模态、拓宽上下文长度等方向深层次发展,这对模型的参数量和训练数据量提出了更高要求。数据量的持续攀升催生了对于算力的强需求,同时,如何进行大规模数据的高效处理和存储是当前算力设施面临的两大挑战。
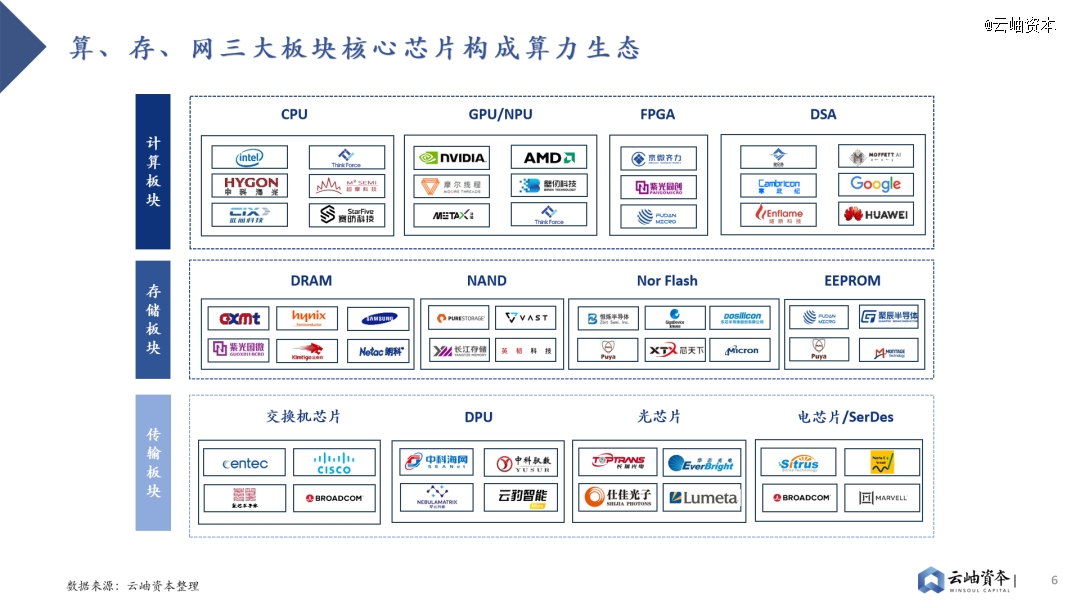
因此,算、存、网三大板块核心芯片共同构成算力生态,未来将持续受益于算力的旺盛需求。其中,算力芯片最为紧缺,目前仍以GPU为主,CUDA生态在短期内难以被突破。存储则日渐成为大模型训推的瓶颈,HBM、高速PCIe等新技术快速渗透和迭代,持续提高计算效率。传输上,高性能的网络通信芯片能够提升数据传输的效率,降低延迟,有效提升客户集群训练能力。
算力生态市场前景广阔,规模持续增长。据Gartner预测,到2027年,全球AI算力芯片市场规模预计将达到1194亿美元,2022年至2027年复合增长率达22%。全球HBM市场规模增长迅速,2026年市场规模预计将达127亿美元,2022年至2026年复合增长率达37%。全球企业级SSD市场规模稳步增长,预计将从2022年的207亿美元增长至2026年的273亿美元。

GPU成为AI算力芯片主流架构
存在国产替代投资机会
从CNN发展至Transfomer,大模型仍在持续升级中,对AI芯片通用性提出更高要求。硬件端是否能持续兼容各类大模型的迭代升级成为重要标准,GPU架构将成为未来主流架构。相较性能更为优异的DSA架构,GPU架构在通用性上的突出优势使其能快速兼容各类模型、场景,通过大规模落地量产平摊研发成本。此外,GPU架构于性能端也存在软件优化空间,CUDA平台已形成软件生态壁垒,助力AI各类场景应用硬件加速。

GPU芯片英伟达一家独大,高性能硬件+CUDA生态强强绑定,软硬件结合构建行业壁垒。2023年英伟达在全球AI服务器市场占有率达到65%,在全球GPU芯片领域更是保持*的龙头地位,市占率达到80%以上。2023年英伟达数据中心板块营收达475亿美金,同比增长217%,最新市值已达到2.2万亿美金。英伟达稳固的龙头地位来自于软硬件结合形成的生态壁垒,硬件层面算力水平全球*的同时搭配软件平台CUDA,为客户带来1+1>2的大模型训推成效。
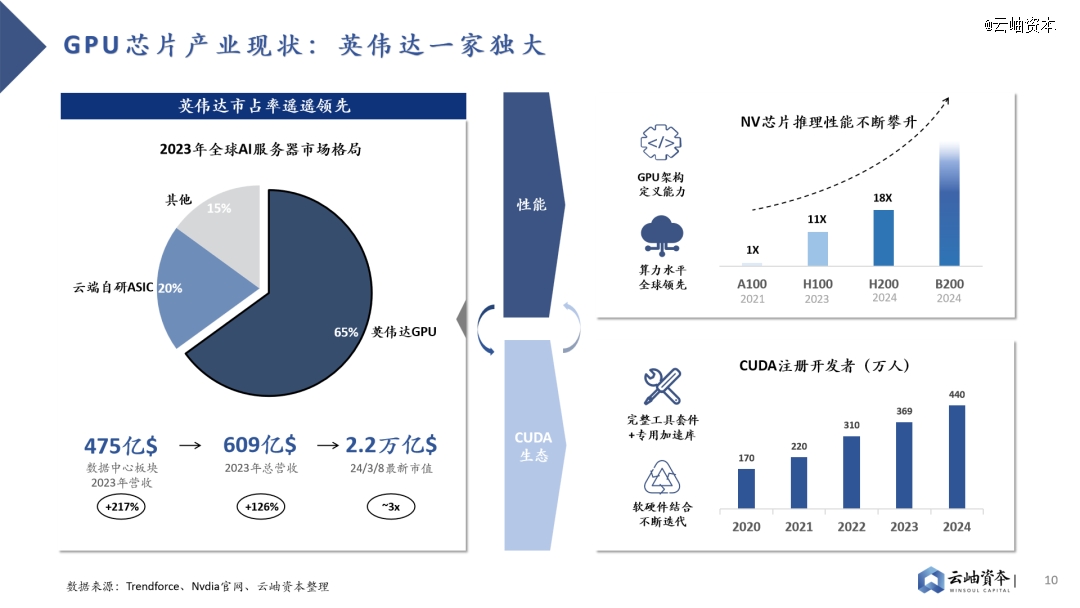
2022年10月,美国商务部工业与安全局(BIS)公布了《对向中国出口的先进计算和半导体制造物项实施新的出口管制》,禁售了英伟达的高性能H100、A100芯片。为了应对政策制裁,英伟达推出了中国*版H800、A800芯片,在单卡算力不变的基础上削弱了卡间互联能力,阻碍多机多卡算力集群的构建。2023年10月美国商务部宣布禁令升级,*版H800、A800芯片成为历史,英伟达只好再次推出性能更低的A20、L20芯片,算力遭到大幅削减。在英伟达高性能芯片获取困难的背景下,国内高性能GPU芯片预计将长期处于供不应求阶段,因此我们认为国产GPU应首先解决有无问题,国产替代的投资机会预计将集中于硬件性能接近A100/H100,软件兼容CUDA生态的GPU芯片创业公司。

存储成为GPU性能瓶颈
带来HBM、PCIe等产业新机遇
GPU迭代存在存储与计算的Trade-off,存储性能迭代已落后于算力迭代。GPU架构存在算力单元“小”而“多”的特点,在摩尔定律接近极限的情况下,为提升算力资源性价比,业界主要通过增加算力单元堆叠的方式提升计算性能;而在存储方面,片上存储空间被挤压的同时,SRAM密度却无法通过制程提升进行弥补,导致当前存储性能迭代已落后于算力。H100相对于A100在FP16算力水平上有2.42倍的提升,而SRAM存储容量提升仅有1.22倍。

存储子系统容量、带宽不足已成为GPU发展瓶颈。大模型训推需要对海量数据进行存储、处理,这对GPU存储系统容量、访存带宽提出了更高的要求。对于GPU架构而言,算力单元堆叠不是难事,当前计算任务主要耗时集中于等待数据从存储系统到达计算单元的过程,而非计算单元进行矩阵计算的过程。
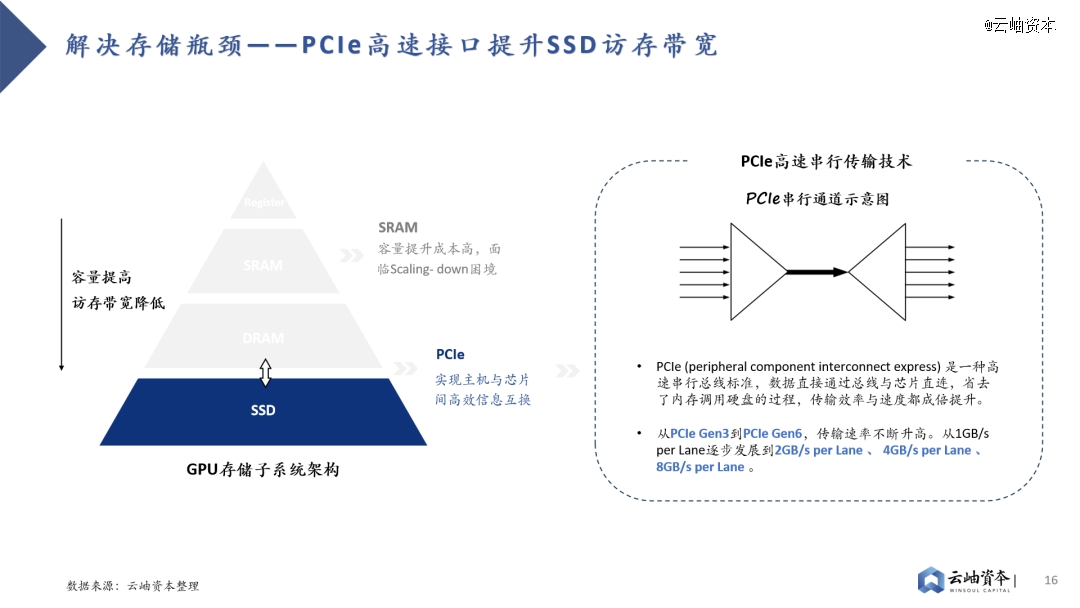
GPU主要采用多级Cache的分布式存储子系统,离计算单元越近的存储单元容量越小,访存带宽越高,因此性能提升方向有三:提高SRAM容量、提高DRAM带宽、提高SSD带宽。其中片上SRAM容量提升成本高,并非主流路径。
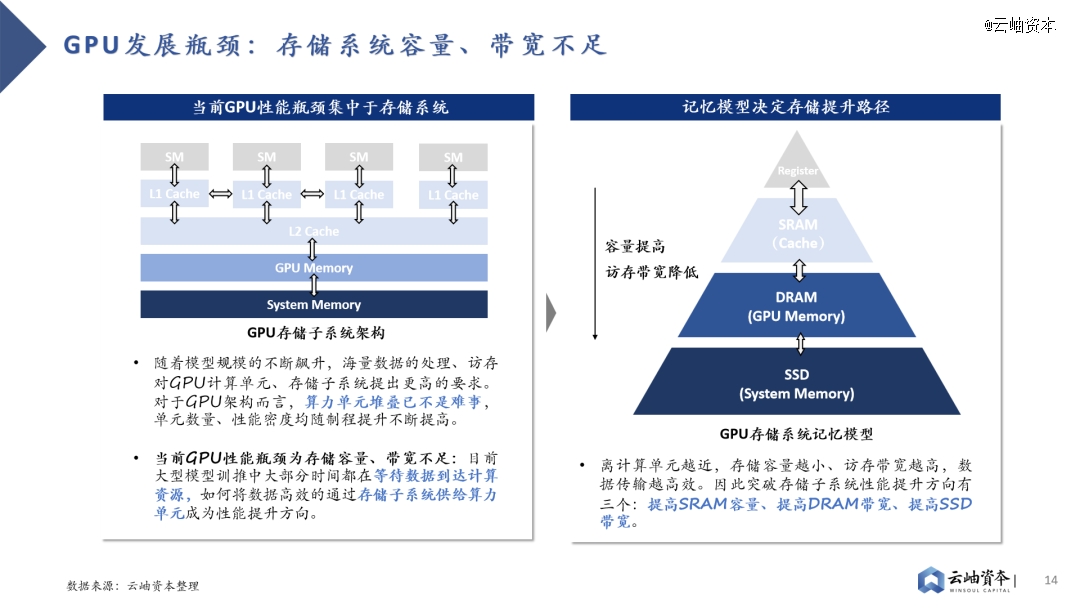
因此,业界主要采取两种路线解决存储瓶颈。其一是HBM(High Bandwidth Memory)技术,HBM技术解决了当前DRAM容量不足、带宽低的问题,已成为主流算力芯片“标配”。其通过硅通孔TSV技术垂直连接多个DRAM,缩短互联距离以提高传输带宽及容量。从HBM初代技术到目前最新的HBM3e,垂直堆叠的DRAM芯片数量从4个提高到12个,每个DRAM芯片的密度从2GB增加到24GB、36GB,带宽从128GB/s、256GB/s、307.2 GB/s、819 GB/s上升到约1.2TB/s。
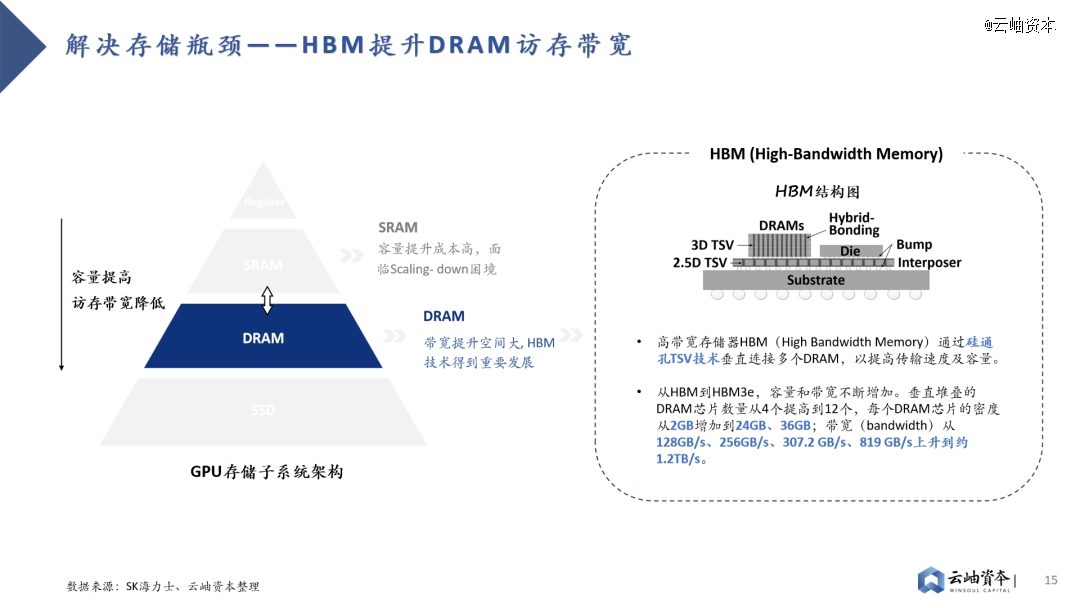
其二则是PCIe技术的持续升级。目前SSD接口已从SATA逐步转向更高速的PCIe接口,这是一种高速串行总线标准,数据直接通过总线与芯片直连,省去了内存调用硬盘的过程,传输效率与速度都成倍提升。从PCIe Gen3到PCIe Gen6,传输速率不断升高,从1GB/s per Lane逐步发展到2GB/s per Lane 、 4GB/s per Lane 、 8GB/s per Lane 。
三大巨头垄断背景下HBM成本高昂、产能紧张,带来国内先进封装产业链投资机会。HBM芯片占据AI芯片近半数成本,售价为标准DRAM芯片的5-6倍,毛利高达42%-51%。同时受制于国际三大巨头SK、三星、美光垄断格局,HBM产能紧张,预定周期已达6-12月。先进封装作为HBM制造中附加值最高的环节,发展潜力巨大,存在国产产业链投资机会。
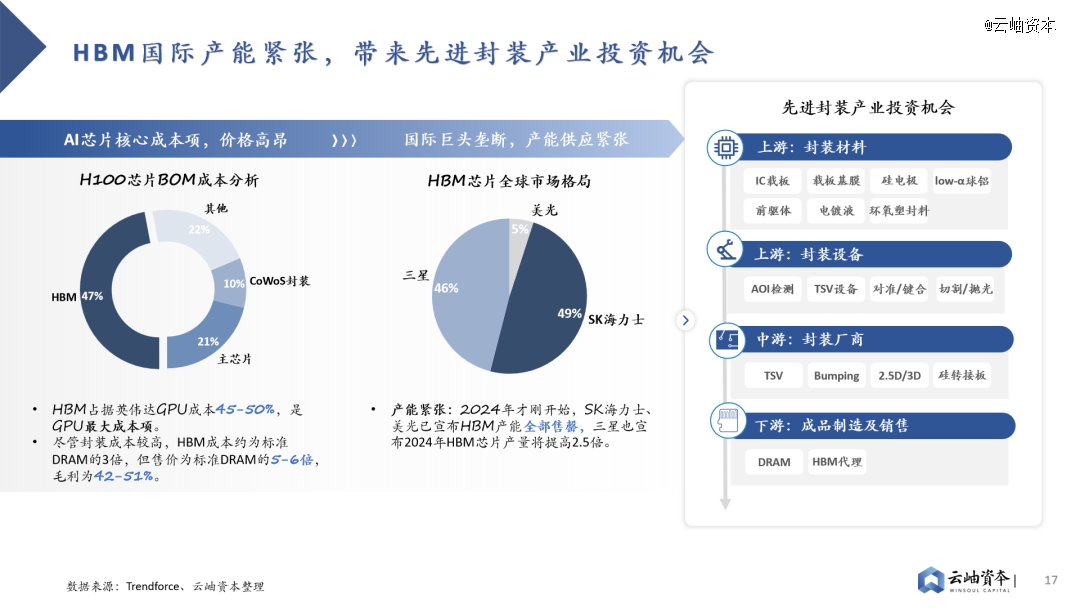
全球SSD市场保持增长态势,传输带宽不断增加,PCIe Gen4已逐步转向PCIe Gen5。2022年全球SSD出货量为3.63亿块,保持增长态势的同时加速替代HDD。细分市场中企业级SSD市场仍处于快速增长通道,2022年出货量为0.55亿块,2022-2028年CAGR达18%。消费级SSD市场追随企业级市场脚步保持稳步增长,2022年出货量为2.97亿块,2022-2028年CAGR达5%。高速串行接口PCIe与SSD绑定加深,逐渐替代SATA成为主流接口,并不断向更高速协议发展。PCIe Gen4已替代PCIe Gen 3成为主流接口,PCIe Gen5已切入市场,成为未来发展趋势。
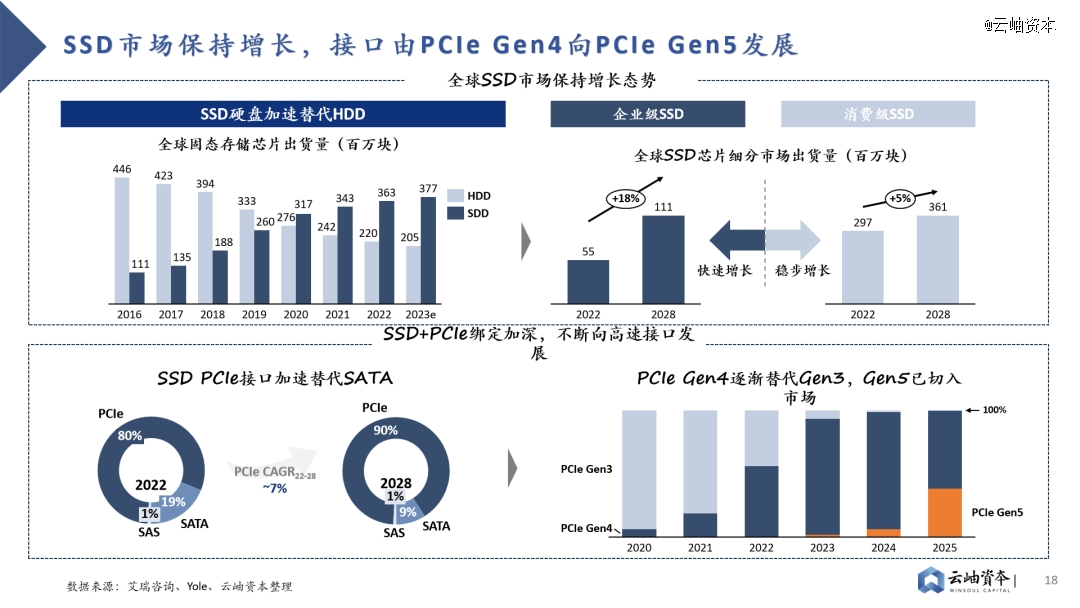
此外,信创市场将提供400亿元SSD国产替代需求,PCIe Gen5能力成为重要考量因素。金融、电信、教育等八大行业存在信创服务器国产替代需求,总需求可达527万台。以单台服务器SSD数量3.8片、SSD单价2000元计算,行业信创将带来400亿元SSD市场规模。其中电信行业服务器需求最高,也是国产替代进程最快的行业之一,对于SSD高容量、高带宽存在高要求。目前PCIe Gen5已加速切入企业级SSD市场,预计2028年渗透率将达69%。消费级市场也将追随企业级市场步伐,预计2028年PCIe Gen5渗透率达12%。
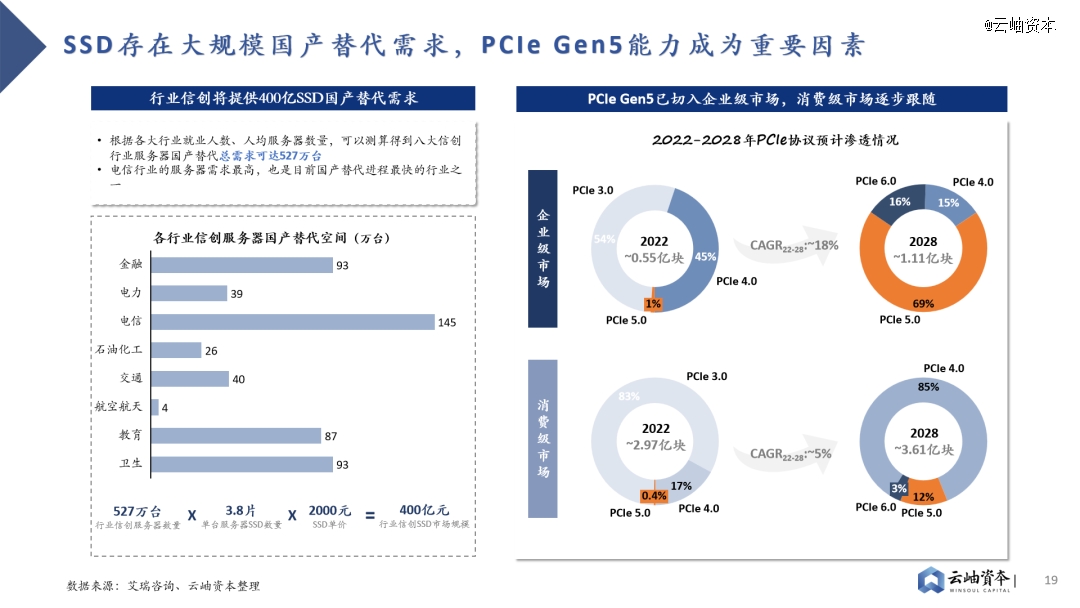
全闪存阵列性能优势突出,已成为高性能数据中心的必然趋势。AI数据中心、云计算等新兴技术领域的不断发展,对高性能存储系统提出了更高的需求。随着SDD替代HDD的进程,SDD低延迟、高吞吐与传统SCSI协议低吞吐、高延迟形成矛盾,这就出现了NVMe高速协议。NVMe高速协议缩短和优化了数据路径,加快了服务器内、服务器与存储阵列间的信息传输,配合SSD高速介质,突显了全闪存阵列的性能优势。2020年,全闪存阵列(AFA)市场占比已达到18.9%,增速为24.0%,高于整体市场平均增长率17.5%。
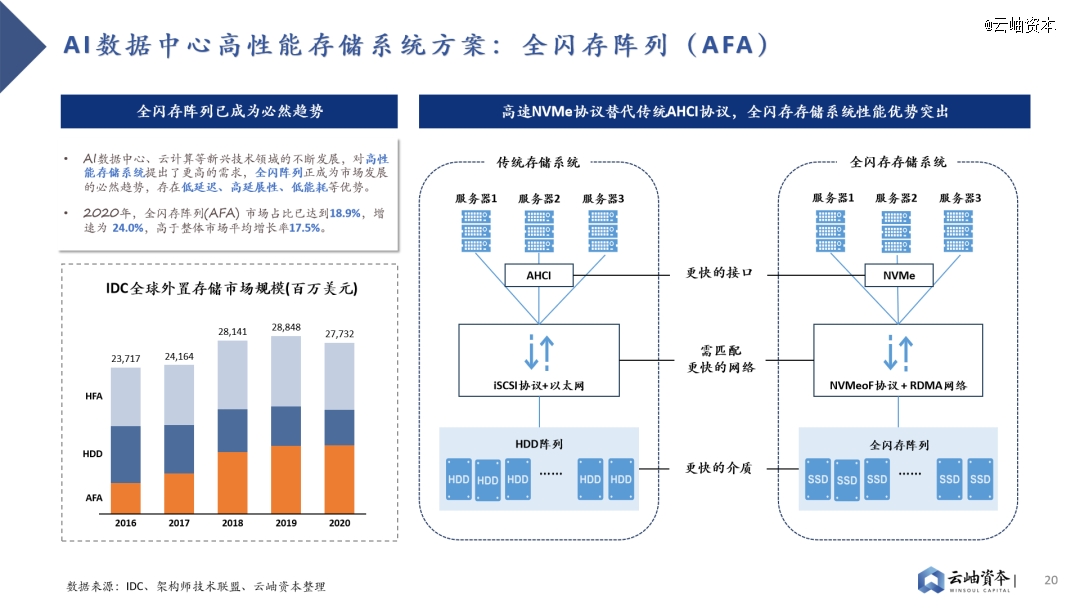
全闪存阵列方案提出两大核心技术要求:系统管理能力及NVMeoF网络能力。
1)相较于HDD,SSD存在闪存的有限写操作周期、损耗均衡、纠错编码、坏数据块等问题,传统SSD控制器已无法满足全闪存系统管理需求,如何进行全闪存存储的管理、组合、优化成为核心技术要求,国际龙头PureStorage、VAST Data均通过自研软件技术方案以增强全闪存系统管理。
2)主机内本地盘存储通信以NVMe协议作为上层协议,建立在PCIe协议之上,*化释放了SSD介质的能力。然而存储系统仍在呼吁更快的网络,以满足主机访问节点外NVMe SSD系统的需求,NVMe-oF (NVMe over Fabrics)应运而生。NVMe-oF通过Fabrics (如RDMA或光纤通道)代替PCle,将NVMe低延时、高吞吐等性能优势从服务器级别,扩展到整个数据中心级别。











