

所有人都在想办法摆脱英伟达的垄断,不管是因为贵还是因为买不到、抢不到,不管是通过自研还是收购还是寻找其他供应商,殊途同归。英伟达*的竞争对手和最重要的客户们,都作出了同样的选择。
OpenAI考虑自研芯片,考虑在英伟达之外拓展更多的算力供应商,不管是成本考虑还是有更大的野心。
微软将在下个月发布自研芯片,然而它已经是主流云厂商里动作最慢的一个,Google的 TPU 已经供应了自家(不算云客户)90% 的 AI 算力需求,亚马逊也通过数十亿级别的投资锁定了自家芯片的客户(不仅仅是 Anthropic)。
「苏妈」更不可能缺席,面对 CUDA 的垄断局面,AMD的 CEO 苏姿丰说:「我不相信护城河」。
连马斯克都抱怨难买的 A/H100 在大模型行业构成的独领风骚的局面,正在发生一些变化。
01、OpenAI 的下一步:自研 AI 芯片
路透社报道,至少从去年开始,OpenAI 就已讨论各种方案,以解决 AI 芯片短缺问题。OpenAI 已将获取更多 AI 芯片列为公司首要任务,讨论方案包括自研 AI 芯片,与包括英伟达在内的其他芯片制造商更密切地合作,以及在英伟达之外实现供应商多元化。
对于 OpenAI 来说,自研芯片不仅能解决 GPU 的短缺问题,同时也将有效降低硬件运行所需的成本,毕竟 GPT-4 的运行成本实在太高了。
当然,美国主要科技巨头多年来一直在试图打造属于自己的芯片,但实际成果有限。对于 OpenAI 来说,能不能另辟蹊径做出成果,尚可未知。
02、微软的自研 AI 芯片计划
The Information 报道,据知情人士透露,Microsoft 计划下个月在其年度开发者大会上推出*专为人工智能设计的芯片。此举是微软多年工作的结晶,旨在减少 Microsoft 对英伟达设计的 AI 芯片的依赖,随着需求激增,这些芯片一直供不应求。
Microsoft 的芯片类似于 Nvidia GPU,专为训练和运行大型语言模型的数据中心服务器而设计。
The Information 4 月份的新闻报道了代号名为 Athena 的芯片,目前尚不清楚它在 11 月 14 日开始的西雅图会议上宣布时的正式名称是什么。
知情人士表示,Microsoft 仍在争论是否会向 Azure 云客户提供该芯片。
该芯片只是 Microsoft 试图避免被锁定在 Nvidia GPU 的方式之一。据知情人士透露,Microsoft 还与 Advanced Micro Devices 就 AMD 即将推出的 AI 芯片 MI300X 密切合作。
03、亚马逊和 Google 的做法
先于微软一步,另外两家主流云厂商亚马逊和 Google 已经在自研 AI 芯片上积累了很多经验,甚至已经有经过市场验证的成熟产品。
亚马逊有两款自研 AI 芯片,名字都起得非常「露骨」——Inferentia 和 Trainium(推理和训练),完全针对机器学习。但这两款芯片追求的并不是*的性能,它们无法与英伟达*的产品相提并论。
在 2021 年产品发布时,亚马逊产品副总裁 Matt Wood 表示 Trainium 在性价比方面比当时 AWS 上的其他选择高 50%。今年春天亚马逊 CEO Andy Jassy 在股东信中表示,使用 Trainium 训练常见 AI 模型相比「类似 的 GPU 系统」快 140%,成本降低 70%。而推理芯片 Inferentia 自从 2019 年推出以来,「为亚马逊等公司节省了超过 1 亿美元的资本支出。」
成本效益是核心目标。
在 9 月底针对 Anthropic 的投资和战略合作中,亚马逊特别强调,会让 Anthropic 使用自家的两款芯片训练模型。Anthropic 当然有能力使用亚马逊的芯片(外加 AWS 上的 N 卡)训练出时下*竞争力的模型。可以想见当 Anthropic 下一款 SOTA 模型发布时,AWS 会铺天盖地地宣传背后如何使用了自研芯片。
同样主打效率的还有另一个云厂商,Google。
在 8 月底的 Google Cloud 发布会上,Google 发布特别针对大模型的第五代 TPU,号称相比上一代,每美元的训练性能提高两倍,推理性能提高 2.5 倍,而 v5e 的成本不到 TPU v4 的一半。「这是迄今为止*成本效益的云端 TPU。」
在 5 月,Google 发布了一篇论文解读自家的 AI 超级计算机,一台包括 4000 多个 TPUv4 的 AI 超算,并加入专为运行和训练 AI 模型定制的组件。Google 宣称这台超算比 NVIDIA A100 快 1.2 - 1.7 倍,功耗低 1.3 - 1.9 倍。(但并没有与 H100 比较,因为 H100 和 TPUv4 并不是同一代产品。)
Google 曾表示,自家 90% 的 AI 任务都是使用 TPU 在跑,但这并不包括大量采购 NVIDIA GPU 的 Google Cloud。
04
AMD,试图跨越 CUDA 护城河
英伟达在 AI 市场的风光,最不甘的可能就是 AMD 了。
最近 AMD 在大模型领域的动作不断,一是 MI300 GPU 芯片的发布,其次是跟 Lamini 合作,携手推出基于 AMD GPU 的企业级 LLM。
对于 MI300,他们的目标是对标英伟达的 H100,MI300 为推理,尤其是大型语言模型推理,进行了专门的优化。
此外,针对英伟达的护城河 CUDA 平台,在 The Verge 对苏姿丰的专访以及 HPCwire 的文章中均有专门的分析。
「在市场发展如此迅速的情况下,我不相信护城河。当你考虑护城河时,它更多的是成熟市场,人们并不真正想要改变很多东西。而生成式人工智能的发展速度令人难以置信。我们在常规开发环境中几个月取得的进展可能需要几年时间。尤其是软件,我们的方法是一种开放式软件方法。」苏姿丰回应道。
目前 CUDA 和大模型的中间层平台以主流的开源工具 PyTorch 为主,在 HuggingFace 上,92% 的可用模型是基于 PyTorch 进行开发的。而 PyTorch 本身是兼容 AMD 平台的,AMD 最新的芯片也针对 PyTorch 进行了优化。
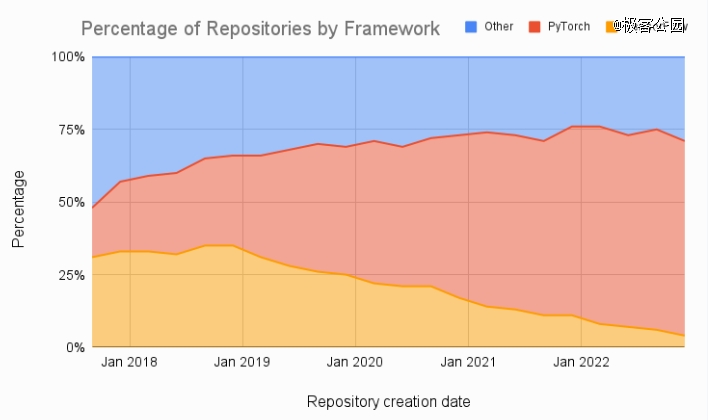
如图所示:机器学习论文的数量比较显示出 PyTorch 和 TensorFlow 的显着趋势。
在访谈中,苏姿丰宣称,「我们所取得的一个重要里程碑就是,在 PyTorch 2.0 上,AMD 在*天就获得了适配。这意味着,现在在 PyTorch 上运行 CUDA 的人,开箱就能在 AMD 上运行,因为我们在这方面做了大量工作。坦率地说,它也能在其他硬件上运行。」
而和 Lamini 的合作,AMD 也能借此寻求其在 LLM Finetune 方面的专业知识,针对企业用户做进一步的优化。Lamini 针对企业级 Finetune LLM 进行了优化,这些 LLM 拥有大数据并使用专门的数据、任务和软件接口,建立在基础模型——Llama 2、GPT-4 和 Claude 等基础模型通过在 CommonCrawl、the Pile 或教科书等通用数据集上进行训练,针对英语、自动完成、推理和编程等通用技能进行了优化。








