

近期,英伟达推出的一款计算光刻软件引起了广泛关注,这使得计算光刻这个领域受到了更多人的关注。计算光刻这个领域已经存在了30年之久,但现在为什么备受关注呢?因为这关乎摩尔定律的继续演进,芯片的继续微缩。
01 什么是计算光刻?
在讲计算光刻之前,让我们先从一个简单的相机开始谈起。数码相机我们都不陌生,一般而言,相机的光圈越大越好。那么如何分辨光圈的大小呢?在相机镜头周围的标记的看起来像比例的数字就是光圈的大小,1:XX,所以分母越小,光圈就越大,但是分母越小,也越昂贵。
芯片制造中的光刻与这一原理颇有相似之处。在芯片制造的过程中,有一道光刻的关键步骤,需要在衍射极限条件下使用世界上最复杂的“相机”将设计好的电路刻画到硅上,这个相机也就是现在大家熟知的光刻机。要给微型晶体管成像,就需要大的透镜。
在光刻技术中遵循瑞利准则(Rayleigh Criterion)——CD=k1*λ/NA。
其中,CD特征值是光刻系统能够放大的最小精度(也就是光学系统的分辨率),CD数值越小代表分辨率越高,我们现在所说的5nm、3nm制程就是这个参数;
λ代表光源波长,波长越小越好;
NA代表数值孔径,表示镜头质量的特征数,数值孔径是衡量透镜系统收集和聚焦光线能力的参数,NA越高越好。
过去30年以来,芯片沿着摩尔定律的准则不断向前发展,工艺的微缩起到了很大的作用,也就是上述CD特征数值越来越小。光刻机巨头ASML一直在通过光刻机的进步来降低入射光源的波长(λ),提高数值孔径,进而获得越来越小了CD值。ASML从g-line光刻机发展到DUV光刻机和现在的EUV光刻机。例如,在DUV光刻机中249nm和193nm是最常见的波长(λ),EUV光刻系统的光源波长为13.5nm。
但下图中可以看出,白色的直线表示芯片的尺寸,随着时间的推移,芯片的大小呈指数在缩小,金色的是用来成像的光的波长,可以看出,波长与要成像的晶体管的差距一直在扩大。当这种情况发生时,物理衍射就会使图像模糊。
于是,行业给出的解决方法是采用逆向光刻的思维,先给定一个图像,即晶圆上的电路设计,逆向推测出所需要的掩膜和光源,这就是所谓的计算光刻。
据新思的科普,在尺寸非常小时,特征彼此距离更近,通常无法清晰准确地将掩模图案刻到晶圆上。光漫射会影响分辨率,导致图案模糊或失真。计算光刻的作用就是补偿因衍射或光学、抗蚀剂和蚀刻邻近效应而导致的任何图像误差。
计算光刻通常包括光学邻近效应修正(OPC)、光源-掩膜协同优化技术(SMO)、多重图形技术(MPT)、反演光刻技术(ILT)等四大技术。在这其中,OPC(光学邻近校正)和 ILT(逆光刻技术)是主要的两种。
计算光刻其实属于软件的范畴,ASML对计算光刻的释义是,利用计算机建模、仿真和数据分析等手段,来预测、校正、优化和验证光刻工艺在一系列图案、工艺和系统条件下的成像性能。计算光刻被ASML称为是“铁三角”软件部分的中坚力量,可见其重要性。(顺便一提,ASML目前有计算光刻研发实习的职位招聘)
02 问题来了,计算光刻越来越难
但是现在问题来了,据NVIDIA先进技术集团副总裁Vivek K Singh的说法:“我在1993年加入光刻工作时,如果你想在晶圆上印一个十字,你只需要在掩模上印一个十字就行。但是很快情况就变了,光的扩散会影响分辨率,导致模糊或失真 ,这意味着可能会遗漏芯片的重要元素。如下图所示,一些可爱的狗耳朵和双髻鲨开始出现在掩膜上,以此来弥补光学衍射。但这还远远不够,我们不得不采用完全成熟的基于光学接近校正(OPC)的模型,后来又开始通过基于规则的辅助功能来增强它。从最简单的一些粉饰到逐渐扭曲的掩膜,最终的结果还是要在晶圆上印下那个十字,只不过是在很小的晶圆尺寸上。”
由此可以看出,当芯片的关键尺寸小于光源波长的时候,所需要的掩模版越来越复杂。几十年来,为芯片在制造过程中制作掩膜一直是半导体制造中的关键环节。
尤其是芯片逐渐来到3nm及以下,不仅需要更加精准的光刻计算,光刻计算所需的时间也越来越长。计算光刻是涉及电磁物理、光化学、计算几何、迭代优化和分布式计算的复杂计算,没有更强大的计算光刻很难实现这样复杂的掩模版设计。
像台积电这样的代工厂需要有大量的数据中心来处理相关计算和仿真运行,代工厂的数据中心通常是以CPU为核心。下图是Vivek Singh估算的每年CPU工作的小时数,左侧y轴显示了随着工艺节点不断微缩,光学邻近修正(OPC)在2nm、1nm差不多需要CPU来计算几百万小时。右侧Y轴上是不同工艺节点所用的数据中心的数量,5nm节点差不多需要3个大的数据中心,每个数据中心需要处理10个掩膜。3nm节点的时候需要6个数据中心,如果继续这样下去,到1nm则很有可能需要100个数据中心。“你不能一直增加数据中心,有些东西必须舍弃,洛杉矶已经开始下雪了。”Vivek Singh如是说道。再者,现在的计算能力在未来很可能不够。
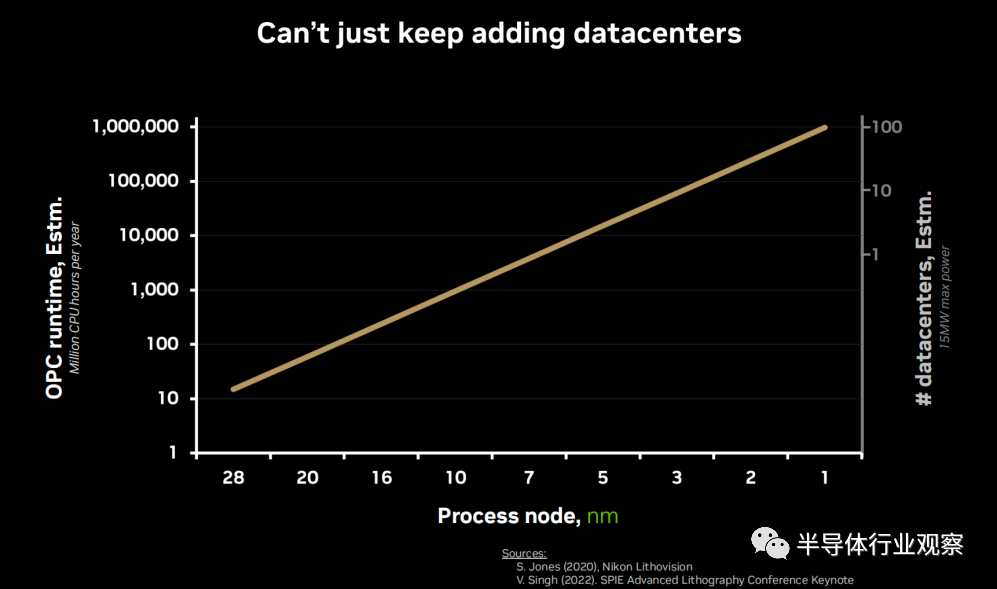
所以,在半导体制造中的超大型工作负载所需的计算时间成本,已经使得摩尔定律不再具有经济性。计算光刻这一步骤也成为将新的纳米技术节点和计算机架构推向市场的瓶颈。
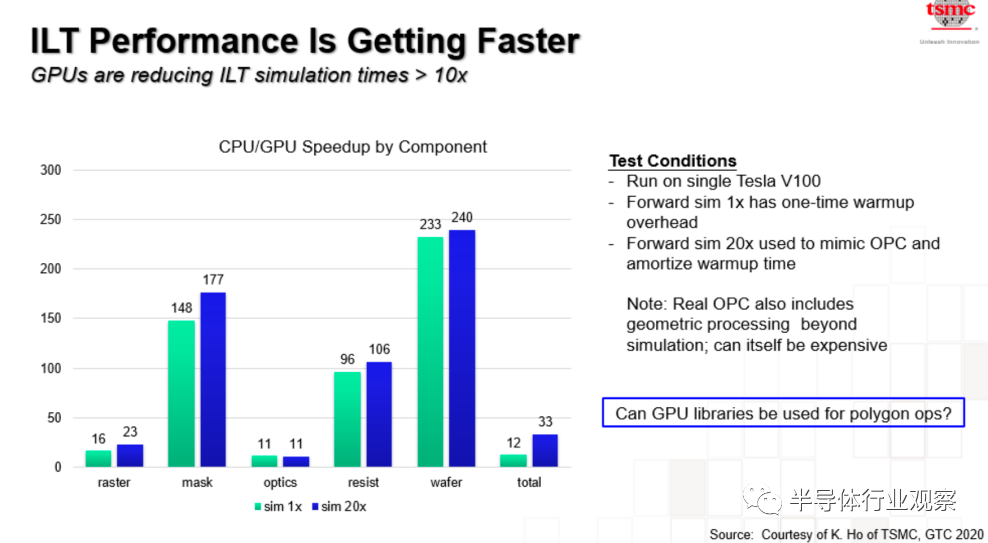
2020年台积电在一次会议上提到,采用GPU可以将反向光刻(ILT)仿真时间减少10倍以上。ppt的最后台积电提了一个很重要的问题,GPU库可以用于多边形操作吗?
03 英伟达改变了游戏规则
今天英伟达证明了,可以。为什么GPU可以用于计算光刻,因为计算光刻技术中至少一半的OPC和ILT是由前成像组成的,而且它几乎完全是由卷积运算组成的,这些正是GPU擅长的。
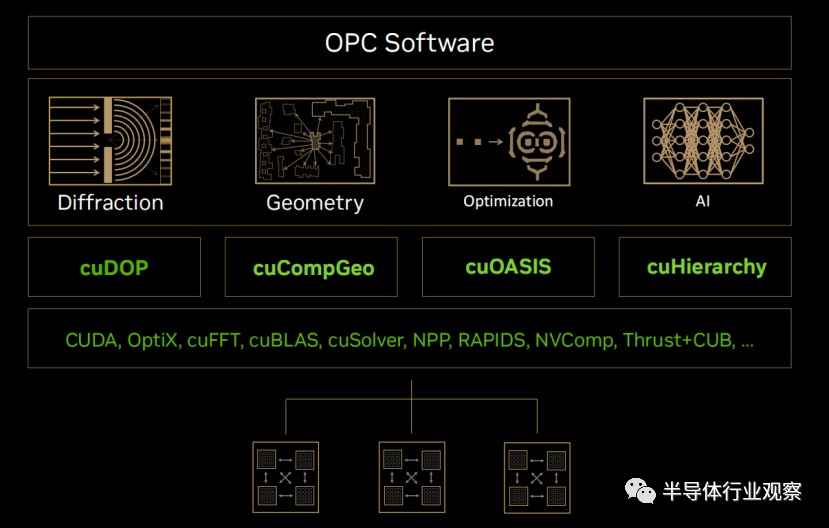
在近日的GTC大会上,英伟达在GPU之上构建了cuLitho计算光刻技术软件库,这是英伟达四年秘密研发的成果。在cuLitho计算光刻软件库中有多项技术,如下图所示,cuDOP用于衍射光学,cuCompGeo用于计算几何,cuOASIS用于优化,cuHierarchy用于AI。
cuLitho已被EDA工具厂商新思采用,cuLitho已集成到新思科技Proteus全芯片掩模合成解决方案和Proteus ILT逆光刻技术。一般情况下,晶圆厂在改变工艺时需要修改OPC,因此会遇到瓶颈。cuLitho不仅可以帮助突破这些瓶颈,还可以提供曲线式光掩模、High-NA EUV光刻、亚原子光刻胶建模等新技术节点所需的新型解决方案和创新技术。
cuLitho的核心是一组并行算法,由英伟达科学家发明,计算光刻工艺的所有部分都可以并行运行,原来需要4万个CPU系统才能完成的工作,现在仅需用500个NVIDIA DGX H100系统即可完成,这不仅大大加速了目前每年消耗数百亿CPU小时的大规模计算工作负载,而且降低了耗电和对环境的影响。
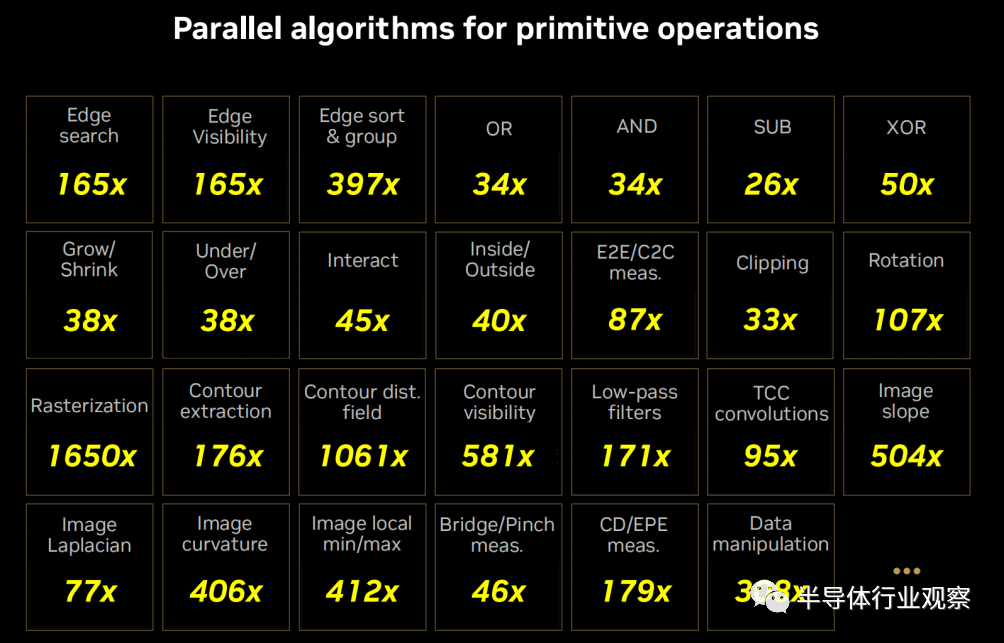
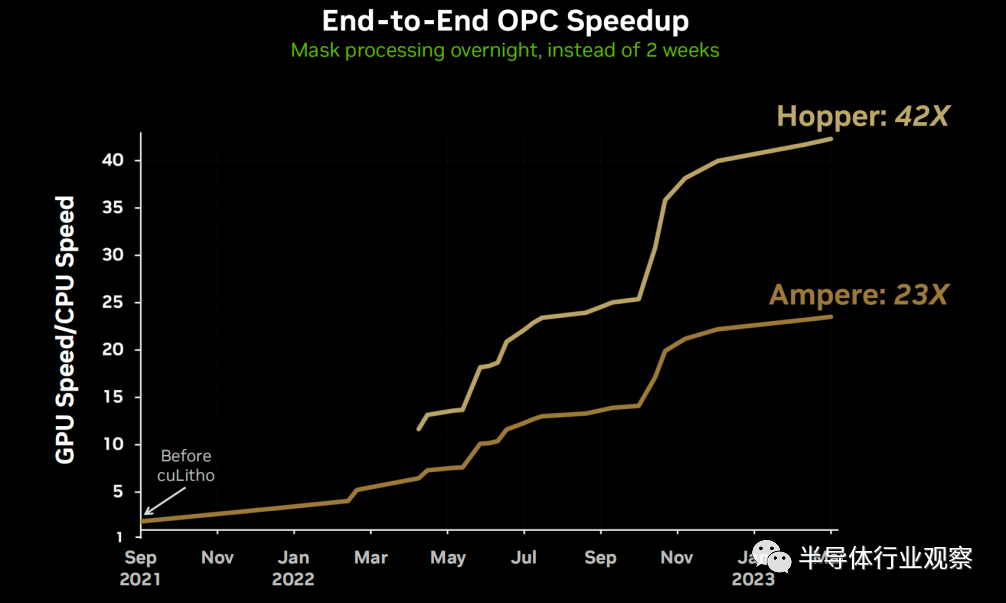
cuLitho在组件级别上平均加速了一次连续的CPU操作,基于Ampere组件上提升了138倍,在Hopper结构上提高了254倍。在端到端的OPC项目中,结合Ampere提升了23倍,在Hopper上提升了42倍。
使用cuLitho的晶圆厂每天的光掩模产量可增加3-5倍,而耗电量可以比当前配置降低9倍。英伟达表示,基于GPU的cuLitho计算光刻技术,其性能比当前光刻技术工艺提高了40倍,原本需要两周时间才能完成的光掩模现在可以在一夜之间完成。例如英伟达H100 GPU需要89块掩膜板,在CPU上运行时,处理单个掩膜板需要两周时间,而在GPU上运行cuLitho只需8小时。
从长远来看,cuLitho将带来更好的设计规则、更高的密度和产量以及AI驱动的光刻技术,使晶圆厂能够提高产量、减少碳足迹并为2纳米及更高工艺奠定基础。
cuLitho计算光刻技术软件库,目前已得到了台积电、ASML的合作。cuLitho将于6月在台积电开始使用,台积电用其来部署反演光刻技术、深度学习等;ASML计划在所有计算光刻软件产品中加入对GPU的支持,cuLitho的优势在High-NA EUV光刻时代将变得尤为明显;EDA工具供应商Synopsys OPC软件将在cuLitho平台上运行。
下图是一个chromeless face shift掩膜,如果把它放进ASML最新的光刻机中,会出来怎样一个图案呢?
答案是,NVIDIA cuLitho。

目前的cuLitho计算光刻技术还只是一个于麦克斯韦方程组的数学工具,但英伟达表示,基于人工智能的计算光刻技术“正在开发中”。想象一些如果AI技术引入计算光刻又将如何?
04 写在最后
没有计算光刻技术的支撑,芯片制造商就不可能制造出最新的技术节点。cuLitho计算光刻库软件的发布,不仅为芯片的继续演进提供了一项革新技术,也再次发挥了GPU的潜力——从最初的图形处理到AI芯片、再到数据中心、乃至芯片的未来,老黄赢麻了。
借用《软硬件融合》图书和公众号作者,上海矩向科技创始人兼CEO黄朝波对该发布的点评:“老黄是非常成功的,但其实本质上老黄就只做了一件事情(并行计算)和两个方面(GPU是并行计算平台,CUDA是为了更好的并行计算编程)。”
每次当芯片演变出现瓶颈,总会有新技术出现,例如FinFET晶体管技术的发明给摩尔定律续命了十几年。现在,为了让芯片继续微缩下去,各种新材料、新架构、新封装、新互联等技术层出不穷。










