

由于处理器与存储器的工艺、封装、需求的不同,从1980年开始至今二者之间的性能差距越来越大。有数据显示,处理器和存储器的速度失配以每年50%的速率增加。
存储器数据访问速度跟不上处理器的数据处理速度,数据传输就像处在一个巨大的漏斗之中,不管处理器灌进去多少,存储器都只能“细水长流”。两者之间数据交换通路窄以及由此引发的高能耗两大难题,在存储与运算之间筑起了一道“内存墙”。
随着数据的爆炸势增长,内存墙对于计算速度的影响愈发显现。为了减小内存墙的影响,提升内存带宽一直是存储芯片聚焦的关键问题。
长期以来,内存行业的价值主张在很大程度上始终以系统级需求为导向,已经突破了系统性能的当前极限。很明显的一点是,内存性能的提升将出现拐点,因为越来越多人开始质疑是否能一直通过内存级的取舍(如功耗、散热、占板空间等)来提高系统性能。
基于对先进技术和解决方案开展的研究,内存行业在新领域进行了更深入的探索。作为存储器市场的重要组成部分,DRAM技术不断地升级衍生。DRAM从2D向3D技术发展,其中HBM是主要代表产品。
HBM(High Bandwidth Memory,高带宽内存)是一款新型的CPU/GPU 内存芯片,其实就是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量,高位宽的DDR组合阵列。
通过增加带宽,扩展内存容量,让更大的模型,更多的参数留在离核心计算更近的地方,从而减少内存和存储解决方案带来的延迟。
从技术角度看,HBM使DRAM从传统2D转变为立体3D,充分利用空间、缩小面积,契合半导体行业小型化、集成化的发展趋势。HBM突破了内存容量与带宽瓶颈,被视为新一代DRAM解决方案,业界认为这是DRAM通过存储器层次结构的多样化开辟一条新的道路,革命性提升DRAM的性能。
在内存领域,一场关于HBM的竞赛已悄然打响。
01 巨头领跑,HBM时代来临
据了解,HBM主要是通过硅通孔(Through Silicon Via, 简称“TSV”)技术进行芯片堆叠,以增加吞吐量并克服单一封装内带宽的限制,将数个DRAM裸片像楼层一样垂直堆叠。
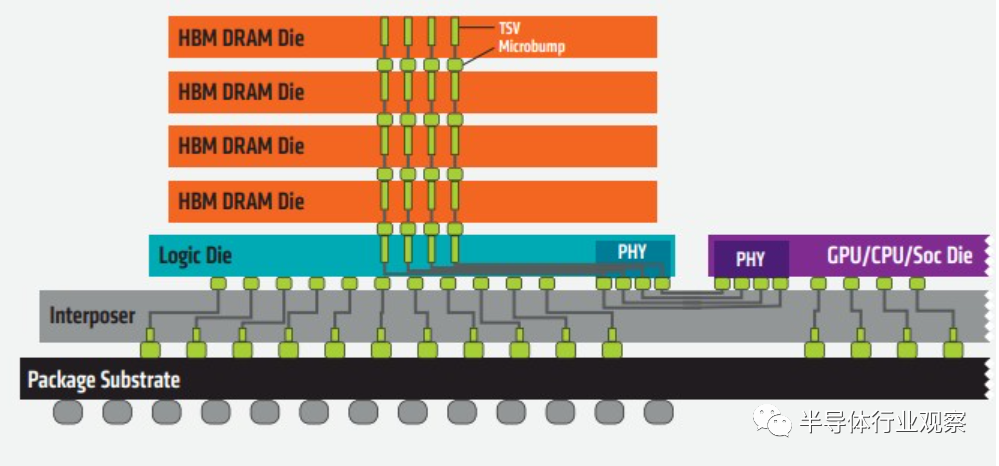
裸片之间用TSV技术连接
SK海力士表示,TSV是在DRAM芯片上搭上数千个细微孔并通过垂直贯通的电极连接上下芯片的技术。该技术在缓冲芯片上将数个DRAM芯片堆叠起来,并通过贯通所有芯片层的柱状通道传输信号、指令、电流。相较传统封装方式,该技术能够缩减30%体积,并降低50%能耗。
凭借TSV方式,HBM大幅提高了容量和数据传输速率。与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸。随着存储数据量激增,市场对于HBM的需求将有望大幅提升。
HBM的高带宽离不开各种基础技术和先进设计工艺的支持。由于HBM是在3D结构中将一个逻辑die与4-16个DRAM die堆叠在一起,因此开发过程极为复杂。鉴于技术上的复杂性,HBM是公认最能够展示厂商技术实力的旗舰产品。
2013年,SK海力士将TSV技术应用于DRAM,在业界首次成功研发出HBM。
HBM1的工作频率约为1600 Mbps,漏极电源电压为1.2V,芯片密度为2Gb(4-hi)。HBM1的带宽高于DDR4和GDDR5产品,同时以较小的外形尺寸消耗较低的功率,更能满足GPU等带宽需求较高的处理器。
随后,SK海力士、三星、美光等存储巨头在HBM领域展开了升级竞赛。
2016年1月,三星宣布开始量产4GB HBM2 DRAM,并在同一年内生产8GB HBM2 DRAM;2017年下半年,被三星赶超的SK海力士开始量产HBM2;2018年1月,三星宣布开始量产第二代8GB HBM2“Aquabolt”。
2018年末,JEDEC推出HBM2E规范,以支持增加的带宽和容量。当传输速率上升到每管脚3.6Gbps时,HBM2E可以实现每堆栈461GB/s的内存带宽。此外,HBM2E支持最多12个DRAM的堆栈,内存容量高达每堆栈24GB。与HBM2相比,HBM2E具有技术更先进、应用范围更广泛、速度更快、容量更大等特点。
2019年8月,SK海力士宣布成功研发出新一代“HBM2E”;2020年2月,三星也正式宣布推出其16GB HBM2E产品“Flashbolt”,于2020年上半年开始量产。
据三星介绍,其16GB HBM2E Flashbolt通过垂直堆叠8层10纳米级16GB DRAM晶片,能够提供高达410GB/s的内存带宽级别和每引脚3.2 GB/s的数据传输速度。
SK海力士的HBM2E以每个引脚3.6Gbps的处理速度,每秒能处理超过460GB的数据,包含1024个数据I/O。通过TSV技术垂直堆叠8个16GB芯片,其HBM2E单颗容量16GB。

HBM技术线路图(图源:SK海力士)
2020年,另一家存储巨头美光宣布加入到这一赛场中来。
美光在当时的财报会议上表示,将开始提供HBM2内存/显存,用于高性能显卡,服务器处理器产品,并预计下一代HBMNext将在2022年底面世。但截止目前尚未看到美光相关产品动态。
2022年1月,JEDEC组织正式发布了新一代高带宽内存HBM3的标准规范,继续在存储密度、带宽、通道、可靠性、能效等各个层面进行扩充升级,具体包括:
主接口使用0.4V低摆幅调制,运行电压降低至1.1V,进一步提升能效表现。
传输数据率在HBM2基础上再次翻番,每个引脚的传输率为6.4Gbps,配合1024-bit位宽,单颗最高带宽可达819GB/s。
如果使用四颗,总带宽就是3.2TB/s,六颗则可达4.8TB/s。
独立通道数从8个翻番到16个,再加上虚拟通道,单颗支持32通道。
支持4层、8层和12层TSV堆栈,并为未来扩展至16层TSV堆栈做好准备。
每个存储层容量8/16/32Gb,单颗容量起步4GB(8Gb 4-high)、*容量64GB(32Gb 16-high)。
支持平台级RAS可靠性,集成ECC校验纠错,支持实时错误报告与透明度。
JEDEC表示,HBM3是一种创新的方法,是更高带宽、更低功耗和单位面积容量的解决方案,对于高数据处理速率要求的应用场景来说至关重要,比如图形处理和高性能计算的服务器。

HBM性能演进(图源:Rambus)
SK海力士早在2021年10月就开发出全球*HBM3,2022年6月量产了HBM3 DRAM芯片,并将供货英伟达,持续巩固其市场*地位。随着英伟达使用HBM3 DRAM,数据中心或将迎来新一轮的性能革命。
根据此前的资料介绍,SK海力士提供了两种容量产品,一个是12层硅通孔技术垂直堆叠的24GB(196Gb),另一个则是8层堆叠的16GB(128Gb),均提供819 GB/s的带宽,前者的芯片高度也仅为30微米。相比上一代HBM2E的460 GB/s带宽,HBM3的带宽提高了78%。此外,HBM3内存还内置了片上纠错技术,提高了产品的可靠性。
SK海力士对于HBM的研发一直非常积极,为了满足客户不断增加的期望,打破现有框架进行新技术开发势在必行。SK海力士还在与HBM生态系统中的参与者(客户、代工厂和IP公司等)通力合作,以提升生态系统等级。商业模式的转变同样是大势所趋。作为HBM领军企业,SK海力士将致力于在计算技术领域不断取得进步,全力实现HBM的长期发展。
三星也在积极跟进,在2022年技术发布会上发布的内存技术发展路线图中,三星展示了涵盖不同领域的内存接口演进的速度。首先,在云端高性能服务器领域,HBM已经成为了高端GPU的标配,这也是三星在重点投资的领域之一。HBM的特点是使用高级封装技术,使用多层堆叠实现超高IO接口宽度,同时配合较高速的接口传输速率,从而实现高能效比的超高带宽。
在三星发布的路线图中,2022年HBM3技术已经量产,其单芯片接口宽度可达1024bit,接口传输速率可达6.4Gbps,相比上一代提升1.8倍,从而实现单芯片接口带宽819GB/s,如果使用6层堆叠可以实现4.8TB/s的总带宽。
2024年预计将实现接口速度高达7.2Gbps的HBM3p,从而将数据传输率相比这一代进一步提升10%,从而将堆叠的总带宽提升到5TB/s以上。另外,这里的计算还没有考虑到高级封装技术带来的高多层堆叠和内存宽度提升,预计2024年HBM3p单芯片和堆叠芯片都将实现更多的总带宽提升。而这也将会成为人工智能应用的重要推动力,预计在2025年之后的新一代云端旗舰GPU中看到HBM3p的使用,从而进一步加强云端人工智能的算力。
从HBM1到HBM3,SK海力士和三星一直是HBM行业的领军企业。
02 HBM未来潜力与演进方向
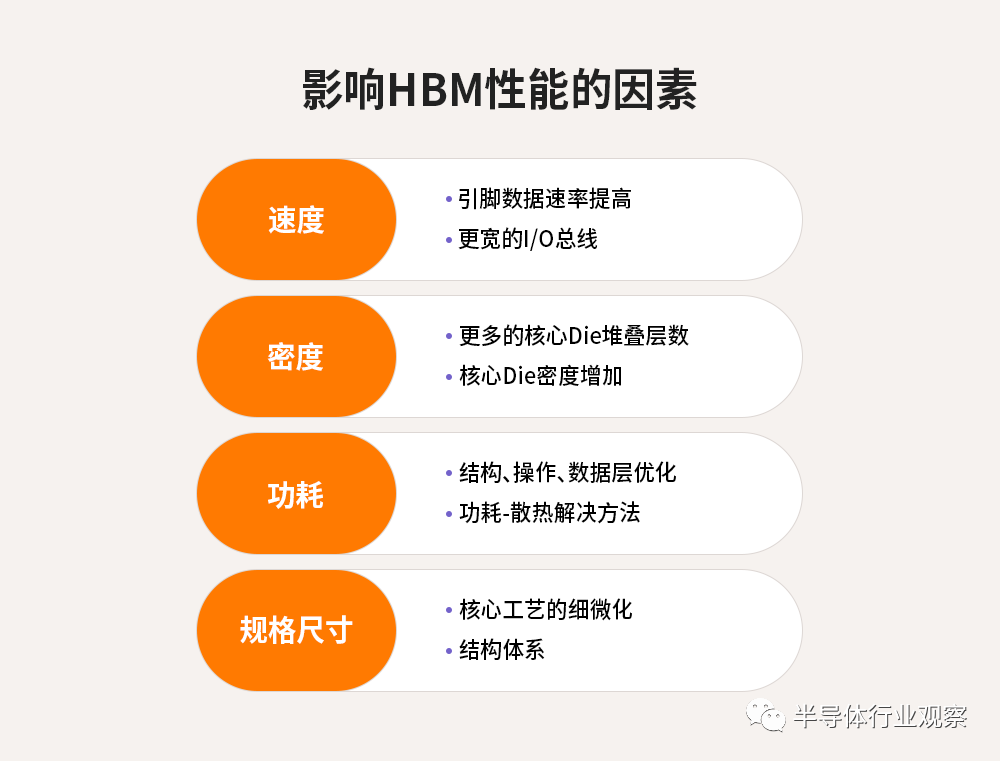
对于接下来的规划策略和技术进步,业界旨在突破目前HBM在速度、密度、功耗、占板空间等方面的极限。
影响HBM性能的因素
首先,为了打破速度极限,SK海力士正在评估提高引脚数据速率的传统方法的利弊,以及超过1024个数据的I/O总线位宽,以实现更好的数据并行性和向后设计兼容性。简单来讲,即用最少的取舍获得更高的带宽性能。
针对更大数据集、训练工作负载所需的更高内存密度要求,存储厂商开始着手研究扩展Die堆叠层数和物理堆叠高度,以及增加核心Die密度以优化堆叠密度。
另一方面也在致力于提高功耗效率,通过评估从*微结构级别到最高Die堆叠概念的内存结构和操作方案,*限度地降低每带宽扩展的*功耗。由于现有中介层光罩尺寸的物理限制以及支持处理单元和HBM Cube的其他相关技术,实现总内存Die尺寸最小化尤为重要。因此,行业厂商需要在不扩大现有物理尺寸的情况下增加存储单元数量和功能,从而实现整体性能的飞跃。
但从产业发展历程来看,完成上述任务的前提是:存储厂商要与上下游生态系统合作伙伴携手合作和开放协同,将HBM的使用范围从现有系统扩展到潜在的下一代应用。
此外,新型HBM-PIM(存内计算)芯片将AI引擎引入每个存储库,从而将处理操作转移到HBM。
在传统架构下,数据从内存单元传输到计算单元需要的功耗是计算本身的约200倍,数据的搬运耗费的功耗远大于计算,因此真正用于计算的能耗和时间占比很低,数据在存储器与处理器之间的频繁迁移带来严重的传输功耗问题,称为“功耗墙”。新型的内存旨在减轻在内存和处理器之间搬运数据的负担。
03 写在最后
过去几年来,HBM产品带宽增加了数倍,目前已接近或达到1TB/秒的里程碑节点。相较于同期内其他产品仅增加两三倍的带宽增速,HBM的快速发展归功于存储器制造商之间的竞争和比拼。
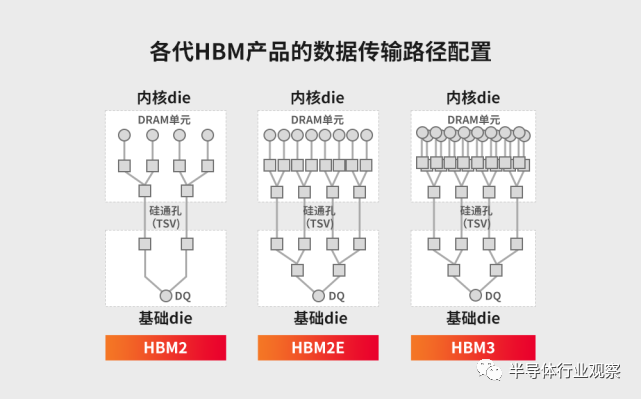
存储器带宽指单位时间内可以传输的数据量,要想增加带宽,最简单的方法是增加数据传输线路的数量。事实上,每个HBM由多达1024个数据引脚组成,HBM内部的数据传输路径随着每一代产品的发展而显著增长。
各代HBM产品的数据传输路径配置
回顾HBM的演进历程,*代HBM数据传输速率大概可达1Gbps;2016年推出的第二代产品HBM2,最高数据传输速率可达2Gbps;2018年,第三代产品HBM2E的最高数据传输速率已经可达3.6Gbps。如今,SK海力士和三星已研发出第四代产品HBM3,此后HBM3预计仍将持续发力,在数据传输速率上有更大的提升。
从性能来看,HBM无疑是出色的,其在数据传输的速率、带宽以及密度上都有着巨大的优势。不过,目前HBM仍主要应用于服务器、数据中心等应用领域,其*的限制条件在于成本,对成本比较敏感的消费领域而言,HBM的使用门槛仍较高。
尽管HBM已更迭到了第四代,但HBM现在依旧处于相对早期的阶段,其未来还有很长的一段路要走。
而可预见的是,随着人工智能、机器学习、高性能计算、数据中心等应用市场的兴起,内存产品设计的复杂性正在快速上升,并对带宽提出了更高的要求,不断上升的宽带需求持续驱动HBM发展。市场调研机构Omdia预测,2025年HBM市场的总收入将达到25亿美元。
在这个过程中,存储巨头持续发力、上下游厂商相继入局,HBM将受到越来越多的关注与青睐。










