

他在现场只是播放了一张的演讲内容。
竟引得众人不约而同,纷纷高举手机拍照,会场更是掌声不断。
他叫钱军,很多人熟知这个名字,是因为他曾在AMD担任高管一职长达近10年时间。
在此期间,钱军还带领团队设计量产了两个业界第 一:
第 一颗7nm图形处理器
第 一颗7nm GPGPU架构的AI芯片
而刚才现场之所以会有那般反响,正是因为钱军在2018年所成立的瀚博半导体,搞了一个“大动作”——
预览了国产7nm云端GPU芯片,SG100。

据了解,SG100是集渲染、AI和视频于一体的全功能GPU,在吞吐、延时等性能中具备世界*水平。
至于它所要发力的领域,正是云游戏、云手机、云桌面、云计算等元宇宙关键性应用场景。
例如在现场,钱军便演示了在SG100加持下视频渲染的效果对比:
不难看出,在色彩、帧率、细节、光照等方面,都是要优于世面主流GPU芯片。
并且随着SG100的预览,也就意味着国产GPU玩家队伍,又正式添加一位新成员。
但纵观整场发布会,“业界*”、“性能数倍”等标签显得格外醒目。
之前以“拥有18年以上高端芯片设计和量产经验”先声夺人的瀚博半导体,再次来到聚光灯下。
适应多样化计算需求:芯片、计算架构、软件平台
在钱军看来,芯片及其衍生的产品,从来不是“单打独斗”的存在。
相反,他认为芯片性能的强大,应当是源自底层计算架构。
为此,瀚博半导体在现场率先亮出的便是自研的统一计算架构——VUCA(Vastai Unified Compute Architecture)。钱军表示:
我们用了中台的概念。核心的IP就类似中台,然后上层有统一的开发平台。可以根据产品和规划和侧重点,设计和推出更符合市场需求的产品。
而这张全景图,可以说是贯穿了瀚博半导体的多项核心技术。
例如架构的底层整合了多款高性能计算引擎,包括高性能AI引擎、可编程的矢量计算引擎,还有硬件化视频解码、具备渲染能力的显示核心等。
在这些计算引擎之上,拥有一个高效统一的存储管理、一致性的接口和低延迟的链接。
之所以如此设计,是因为芯片及其产品单单有算力是不够的,接口、数据等因素依旧会成为制约算力效能的羁绊。
除此之外,要想让算力资源效能更大化,它还需要被池化、在云端被集中;因此,瀚博半导体的统一计算架构还设置了完整的虚拟化功能。
而配合的统一的底层软件设计、模块化的上层计算算子库和功能模块,则会让芯片及产品在面对不同客户的需求时,变得更加灵活。
整体而言:
瀚博统一架构让计算密集型的AI、视频、渲染任务性能得到*化硬件加速,同时端到端缩小延时,一体化助力云端实时图形渲染、AI增强处理、视频编解码等需求。
也正是基于这样的统一架构,钱军在现场发布了瀚博半导体的更多新品。
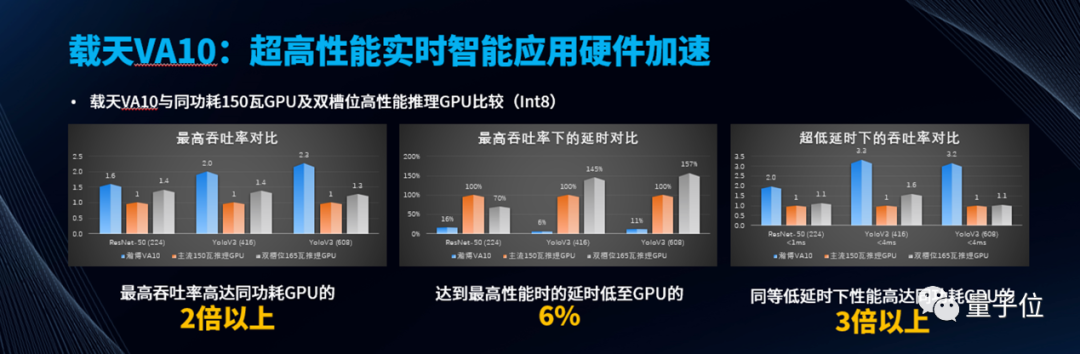
数据中心推理加速卡——载天VA10
载天VA10是一款用于数据中心的高性能AI计算、推理的加速卡。
从性能角度来看,载天VA10所拥有的*亮点,在于INT8峰值算力达400TOPS!
这一数值便一举刷新业界纪录。

但若是仅凭借算力峰值来判断加速卡的强弱,那还是有一些片面,需要的更多的综合性比较。
比如要考虑“算力密度”,算力密度可以从两个维度来讲。
*是按芯片单元面积将算力平均下来,比如一平方毫米芯片的算力如何。另外一个,是每单元瓦的算力,也即每瓦功耗能够提供多大的算力。
例如载天VA10的设计功耗为150W,而在同等条件之下:
最高吞吐率是主流GPU的2倍以上
最高性能延时是主流GPU的6%
不仅如此,在低延时场景(低于4毫秒的YoloV3检测算法场景)下,载天VA10的推理性能,更达到同功耗市场主流GPU的3倍以上。
也正是得益于载天VA10的如此性能,它便非常适合“上岗”一些需要高实时性的云端AI场景,例如直播视频增强、智慧交通管理、实时语义理解等。
以智能ROI优化为例,载天VA10的效果。
不难看出,无论是实时处理效率,亦或是色彩增强效果,载天VA10都是肉眼可见的更胜一筹。
边缘AI推理加速卡——载天VE1
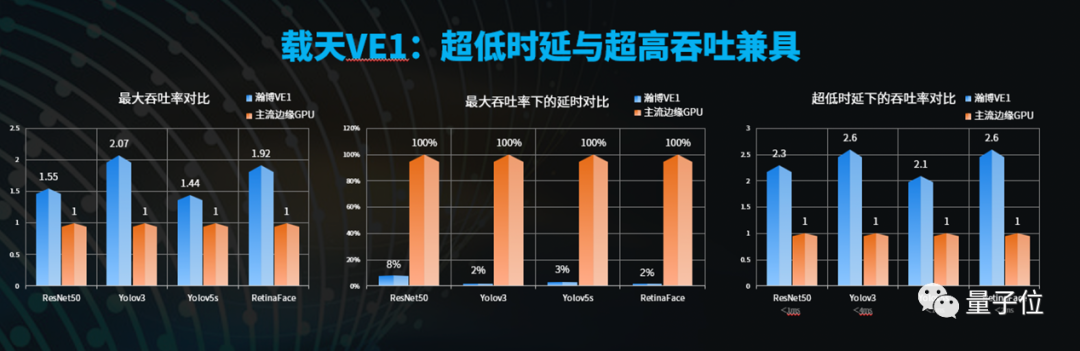
除了数据中心端,瀚博半导体聚焦在边缘端同样发布了新品,载天VE1。

不同于载天VA10,载天VE1更侧重的发力点,是在那些大算力的需求场景。
例如车路协同、低速自动驾驶(无人配送车、港口物流园区无人驾驶的车辆)等。
而载天VE1之所以能够“胜任”于这些场景,还是得益于它自身的性能:
在 40~65瓦功耗下,INT8峰值算力达100TOPS
吞吐率达到主流GPU的2倍,但延时不到主流GPU的5%
软件平台VastStream
但也诚如刚才所言,硬件性能上的“单打独斗”并不能将其功力全程发挥出来。
因此,瀚博半导体对此的破解之道,便是“软硬一体”——VastStream。
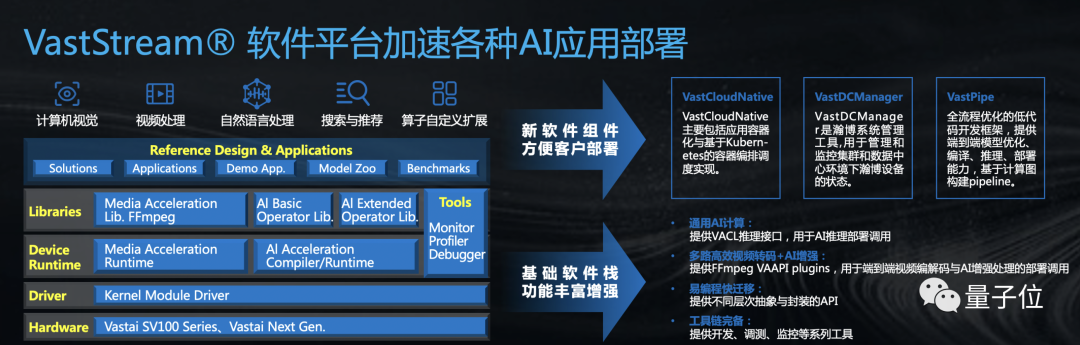
据了解,VastStream软件平台,可以加速各类AI应用的部署。
例如计算机视觉、视频处理、自然语言处理、搜索与推荐、算子自定义扩展等。
而其全新软件组件,还提供了系统管理等三大管理工具,方便客户部署。
与此同时,VastStream的基础软件栈功能也变得更加丰富。
主要特性包括统一接口、灵活调度、通用AI计算、多路高效视频转码+AI增强、易编程快迁移、工具链完备等。
至此,不难看出瀚博半导体已经出现一条清晰可见的业务线:
芯片、推理加速卡、一体机的硬件产品,再到软件整合的系统解决方案。
那么对于这位新晋的“GPU玩家”来说,如今也到了回答这个问题的时候:
瀚博要走怎样的一条“GPU之路”?
对于这个问题,钱军其实在现场已经给出了答案:
我们致力于做全球*的综合算力平台。
而这次预览的GPU,可以说仅是瀚博半导体完整拼图中的重要一块。
这一点,从瀚博半导体的发展路径中便可以了解一二。
钱军在创立瀚博半导体之初,虽然有着数十年深耕GPU的团队,但他们却没有直接切入到造GPU的赛道。
选择的切入点反倒是“AI+视频”,而且这其中的AI更多的是在推理应用侧。
之所以如此,是因为钱军认为视频就像一枚硬币,有着2个维度。
对于已经产生的视频,是一个计算机处理的问题,包括增强、分析等等。
而对于还未出现的视频,那就是一个像素生产的问题,包括渲染等工作。
虽然此前瀚博半导体从未官宣过类似SG100这样的GPU的消息,但与GPU相关的能力其实已经是嵌套在了此前的产品中,只是并未对外宣传。
此举背后的逻辑,就是让产品先用起来,然后再打造一颗独立的高性能GPU。
加之已有的推理卡、软硬件等,便可把“综合算力平台”的拼图拼完整了。
然而把“国产GPU”这条线铺开来看,在瀚博半导体之前,已然是一副势头凶猛的态势。
那么在这样的大环境之下,瀚博半导体正式进入“国产GPU玩家”之列,其所持的杀手锏又将是什么?
对此,钱军表示:
重要的不是只有一个芯片、一个“硬疙瘩”;更重要的是一个软件的生态和合作的生态。
唯有做到高性能、低成本,然后用起来才是硬道理。
One More Thing
瀚博半导体此次正式步入GPU市场,一个非常醒目的标签,便是团队拥有在AMD数年的造芯经验。
而在2020年成立的摩尔线程,其创始人也曾在GPU巨头英伟达任职长达15年。
两个GPU巨头之间长期的“对垒”,已然是人尽皆知的事情。
但现在,从英伟达和AMD出走的人,在国产GPU这条道路上再度“交锋”。
嗯,有点意思。










