

I.引言
自 1959 年 MOSFET 和 1963 年 CMOS 发明以来,CMOS 电路成为低功耗电池供电应用(如数字手表和便携式仪器)的*技术。随后,光刻技术(lithography scaling) 使CMOS踏入高性能计算的竞争行列中。Dennard 1974年对CMOS 缩放(CMOS scaling)原理的总结根据摩尔定律进一步为微电子行业提供了科学的缩放(scaling)方向。然而,到 2005 年,平面 MOSFET的亚阈值泄漏阻止了 Vth、Vdd 和频率按比例缩放,这很大程度上打破了Dennard 缩放原理(scaling principle)。双栅极 (SOI) 和三栅极 (FinFET) 的发明使通道得到了更好的控制,从而载流子不会逃逸到衬底。环栅(例如:纳米线和纳米片)MOSFET 的沟道被栅电极包围,具有更好的静电控制,从而减少了泄漏并提高了载流子迁移率。使用多纳米片,单位面积内的有效宽度W (W_eff) 也得到改善,与 FinFet 器件相比,允许适度的密度缩放。业界即将对 CMOS 缩放(CMOS scaling)进行更多改进。ForkFET 在 PMOS 和 NMOS 之间使用了阻挡层,可以让 PMOS 和 NMOS 彼此靠近放置,从而提高晶体管密度并降低 PMOS 和 NMOS 之间的互连 RC。PMOS 和 NMOS 相互堆叠的互补FET (CFET) 显着减少了 PMOS 和 NMOS 之间的互连,这是因为垂直堆叠上的互连比水平布线短得多。当可以更好地解决热和可测试性挑战时,未来的技术进步可能允许单片制造更多层的 MOSFET(单片 3D 集成)。
总体趋势是 CMOS 缩放速度已经放缓,根据IRDS(国际设备和系统路线图)预计将在 2034 年达到极限。随着晶体管尺寸越来越小,栅极间距的减小使得源极/漏极更加难以形成良好接触,从而对良率和性能调整提出了更多挑战。对于数字处理器来说,持续的器件缩放(device scaling)可能有好处,而对于模拟信号处理单元(例如 IO、无线电或高压电路)来说,保留在较旧的技术节点上更好。这就需要异构集成。已经表明,芯片分解可能有助于提高性能、外形尺寸、成本和上市时间。在最初成功将 HBM(高带宽内存)堆栈与处理器集成在同一封装中以满足 AI/ML 和超级计算中的数据密集型工作负载的需求之后,3D-IC 现在正在形成(taking shape for)主要的高性能计算产品。
在本文中,我们讨论了 3D-IC 时代的互连。第二部分回顾了器件缩放(device scaling)尤其是与器件互联相关的趋势和限制。第三部分讨论了各种应用的芯片到芯片互连,并提供了水平芯片到芯片连接和垂直芯片到芯片堆叠的设计解决方案。第 IV 节侧重于特别是与抖动、功率和通道优化有关的互连性能分析。最后在第五节,讨论了一些未来趋势。
II. 器件缩放趋势和 3D-IC
CMOS 光刻现在处于亚 10nm级(sub 10nm space),发展向 3nm 及以下。总体趋势是接触多晶硅间距 (CPP)、物理栅极长度 (Lg)、鳍片间距、最小金属间距 (MP) 和接触 CD(临界尺寸)继续缩小,但速度较慢。一个限制因素是源极/漏极间距。如图 1 所示,由于finFET 或纳米片 3D 结构 的接触面积/间距减小,MOSFET 的源极/漏极的外部电阻以及栅极和源极/漏极之间的侧壁耦合电容和边缘电容会随着特征尺寸的缩小而降低,导致带宽和功率的改进微不足道。对于模拟应用,过大的栅极、源极和漏极电阻会降低 gm、ft 和 fmax。由于米勒效应,栅极/漏极之间的侧壁电容效应更为明显,它会影响高速电路的上升/下降时间,从而对功耗和抖动产生不利影响。考虑到逻辑设计的密度缩放和高速电路的性能要求,可以提供多个间距,宽间距器件适用于更低的寄生 RC从而使ft更高。还进行了器件和技术的协同优化,以通过金属栅极的双带来降低栅极电阻。先进节点后道工艺(back end of line,BEOL)的电阻效应并没有变得更好。为了解决因积极缩放(aggressive scaling)而导致生产线中端(MEOL)和后道工艺(BEOL)互连电阻率和可靠性的关键和紧急问题,该行业加快步伐在新材料和新工艺方面寻求突破。
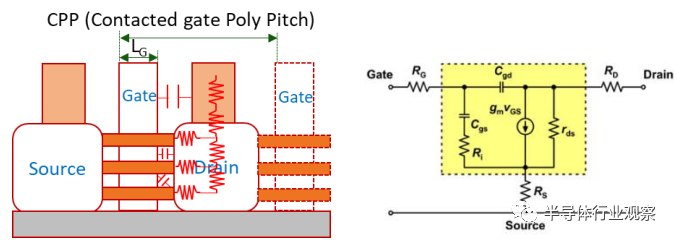
图1.MOSFET中的寄生R&C
简而言之,器件缩放会产生成本,尤其是在模拟、高速 IO 或 RF 电路方面。设计成本和制造成本使做单片 SoC 的效率降低。通过多个小芯片的封装集成来进行芯片分解是自然路径(the natural path)。
由于3D-IC的优势,主要处理器设计供应商现在正朝着 3D 芯片集成的方向发展。3D-IC采用水平连接和垂直堆叠的形式,通过不同工艺和封装技术在较小芯片上制造的计算核心、加速器、内存、缓存、IO、电源管理功能(function)可以像乐高积木一样拼凑在一起。每个功能都针对功率、性能和面积进行了优化。我们即将迎来标准化小芯片接口和 3D 集成流程(flow)。短期内,专有解决方案仍然流行。
可以预见,不同于MOSFET的新技术将逐渐出现。例如,隧道 FET (TFET) 或电阻式 RAM (RRAM) 等新技术可能共存或替代现有 DRAM,以降低功耗和泄漏。技术迁移会采用进化路径(evolutionary path)演变成另一种功率、热、带宽或缩放效率更高的技术,而不会突然脱离历史上非常成功的 MOSFET 技术。3D-IC加速了RRAM、TFET、碳纳米管、光子学等新技术的采用。
3D-IC 集成的主要优势是更好的互连能效,减少访问延迟。3D堆叠允许显着减少块间布线距离。在计算核心附近放置更多内存可以让 CPU 提高性能,因为总布线长度减少了,内存访问带宽和延迟也因此大大提高。例如,片外存储器访问能量约为 10+pJ/bit,访问延迟约为 100ns。由于更高的封装内(in-package)数据带宽,延迟降低了。
3D 集成技术中有一些成分(ingredients) 可以在各种应用中排列形成各种各样的 2.5D 或 3D 结构。从根本上说,这些技术变体可以分为两类:一是垂直连接,例如晶片上芯片、晶片上晶片,使用 uBump、键合或绝缘/硅通孔 (TIV/TSV) 将两个不同的芯片连接在一起。水平连接依靠通过基板或中介层的布线来连接两个芯片。不同的产品采用有机中介层、硅中介层、硅桥、RDL(重新布线层)over Molding或衬底路线等各种布线介质(wiring media)。关键设计考虑因素是密度、损耗、串扰、成本和可制造性。中介层介电常数、凸块间距/尺寸、线宽/间距和 TIV/TSV 直径/高度会影响互连密度和电气性能。有机内插器(organic interposer)可实现更高的带宽。有源内插器(active interposer)可能会为性能提供额外的好处。
III.低功耗芯片到芯片互连的设计
在这里,我们专注于芯片到芯片 (D2D) 互连技术,以应对芯片间通信的挑战。D2D 互连设计有 3 个主要的 FOM(品质因数):线(或面积)带宽密度、能源效率和延迟。对于横向 D2D 连接电路,目前线带宽密度(shoreline bandwidth density)>1Tbps/mm,并且还在不断增加。带宽密度最终受限于芯片几何形状的物理约束(例如线宽度和凸块间距),以及通道插入损耗和串扰带来的性能约束。在水平情况下,我们的目标是 1.2-2.0 毫米的通道范围。更长的覆盖范围是可能的(例如:更低的数据速率、通道均衡、有源内插器(active interposer)或错误检测和纠正),但代价是更低的带宽密度、更长的处理延迟或更高的功率 。对于垂直 D2D 连接电路,F2F 互连的 D2D 互连长度几乎可以忽略不计,而 F2B 互连的 D2D 互连长度则低于 100um。下面我们展示了针对水平集成和垂直集成调整的两个 D2D 接口的设计,同时考虑了上述三个 D2D 互连 FOM。
水平 D2D 互连:图 2(左)是并行 PHY 接口的高级电路架构,在 TSMC 的 N7/N5/N3 工艺中实现了转发时钟,作为支持水平 D2D 连接的基础 IP。该设计以前是通过N7的测试芯片实现的。该系统已经过重新架构,以提高客户的能源效率和线带宽密度(shoreline bandwidth density)。硅中介层(silicon interposer)上支持的*通道长度可达 2mm。基本单元称为通道,由1个公共通道和4个子通道组成。公共通道包括共享功能,例如时钟生成、参考生成和驱动器含义校准(driver implication calibration)。每个子通道有 40 个 Tx 通道(lane)和 40 个 Rx 通道,以及一个时钟单元。PHY 支持 2.8-8Gbps 的数据速率。这使得每个通道每个方向的*总数据带宽为 1280 Gbps。每个子通道中的冗余有两个额外的通道(lane)。如果在 Tx 和 Rx 链路对之间的任何地方发生制造缺陷,则可以激活冗余通道来修复缺陷。为避免不必要的开销,每 20 个通道中只有 1 个缺陷是可修复的。可以禁用不可修复的子通道或通道,但同时要将部分降级支持更少的数据带宽。时钟单元在一个子通道中的 40 个 Rx 和 40 个 Tx 数据通道之间共享。在时钟单元中,在 Tx 时钟路径和 Rx 时钟路径中分别有一个 DCC(占空比校正)电路跟随一个去偏移环路(deskew loop)。发送去偏移环路(transmit deskew loop)用于将 SoC 时钟域与PHY 时钟域一致,接收去偏移环路用于将采样时钟与接收数据眼图中心一致。图 2(右)是两个小芯片之间 D2D 接口的物理实现,有 3 种可能的配置(4+1、2+1 和 1+1)。*使用情况是 4+1(4 个子通道和 1 个公共通道),这是最节能的,但也支持 2+1 和 1+1 以满足对数据带宽需求不太高的应用。凸块间距为 40 微米。本质上,每个 Tx 或 Rx 电路可以占据一个凸块下方的部分区域。凸块下方的其余区域用于时钟分配或去耦电容。PHY 的电源从两侧(图 2 右图所示的顶部和底部)提供。用来支持晶圆级 KGD(已知良好芯片)测试期间探针卡(probe card)的探针垫(probe-pad)更大。每列有 12 个信号凸块,每个凸块运行速度高达 8Gbps。除去用于边带握手(side bands handshaking)、通道冗余的一些凸起,每个通道实现的线带宽密度(shoreline bandwidth density)为 1.78Tbps/mm,能效为 0.36pJ/bit,面积为 1440x1010um²。
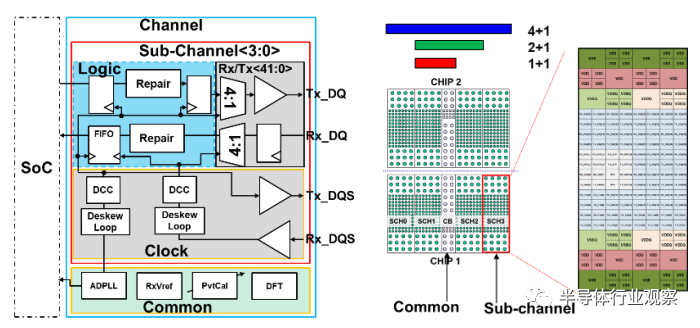
图 2. 水平 D2D 互连
(左:电路架构,右:通道平面图)
垂直 D2D 互连:各种 3D 芯片拓扑是可能的。图3显示了先进3D 集成中的多层芯片堆叠场景。外形尺寸(布线长度、键合间距和 TSV 直径)变得越来越紧凑和小。本设计中贴片间距为9um。由于减少了 D2D 互连长度 (<100um),与水平 D2D 互连相比,通道缺陷更少。每个通道的数据速率增加到 16Gbps。图 4(左)显示了 PHY 的架构图。与水平 D2D 互连不同,时钟单元现在跨 80 个数据通道共享,公共通道(lane)由两个通道(channel)共享。这有效地减少了来自 PLL 和时钟单元的电源开销。每个通道每个方向的总*数据带宽保持为 1280Gbps。由于 PHY 现在受到电路限制(在这种垂直情况下,bond 面积为 81um²,而在水平情况下 ubump 面积为 1600um²),PHY 的平面图更加紧凑,如图 4(右)所示,每个 Tx/Rx 通道 占用 6 个键 (6*81um²) 的面积。总体而言,实现的面积带宽密度为 17.9Tbps/mm2,能效为 0.3pJ/bit,每个通道的面积仅为 378x378um²(不包括 PLL)。
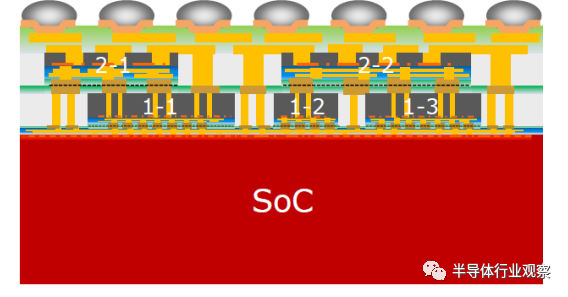
图 3. 垂直芯片堆叠
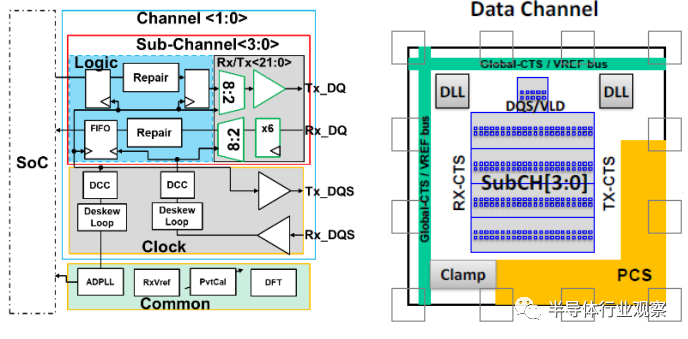
图 4. 垂直芯片到芯片互连
(左:电路架构,右:通道平面图)
IV.电路设计和性能优化
图 5 是 Rx、Tx电路和 Rx 参考生成电路。Rx 使用基于传统感应放大器的触发器进行数据采集,参考电压可通过 7 位电流 DAC 进行调节。Tx 驱动器是低压摆幅 NMOS 驱动器,VDDQ 低至 0.3Volt,以降低驱动器功率和串扰。
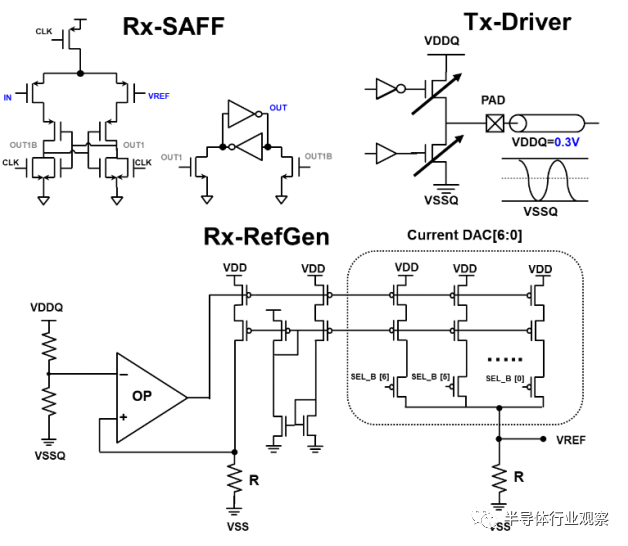
图 5. Rx 和 Tx 的电路实现
图 6 显示了去偏移环路(deskew loop),它由一个用于 8 相时钟生成的 DLL(延迟锁定环路)和一个用于时钟相位调整的 PI(相位内插器)组成。DLL 从用于 Tx 的 ADPLL 获取其输入时钟,并从 Rx_DQS(来自其他芯片的转发时钟)获取输入时钟,。来自 DLL 的 8 相时钟馈入 CMOS PI。PI 时钟分配给 Tx(或 Rx)的时钟树,时钟树的端点也反馈到 PI 控制回路中的 PD,强制时钟端点与时钟 Φx 相位对齐。发送去偏移 DLL 的 Φx 来自 SoC 时钟域,它可能来自 PHY 中的 ADPLL 或来自 SoC 中的不同 PLL。接收去偏斜环路的 Φx 来自 8 相时钟发生器的 Φ2,以创建与 Rx_DQS 的 90 度相移,从而允许接收时钟与 Rx 数据眼图中心对齐。PI 和 DLL 环路滤波器以数字方式实现。
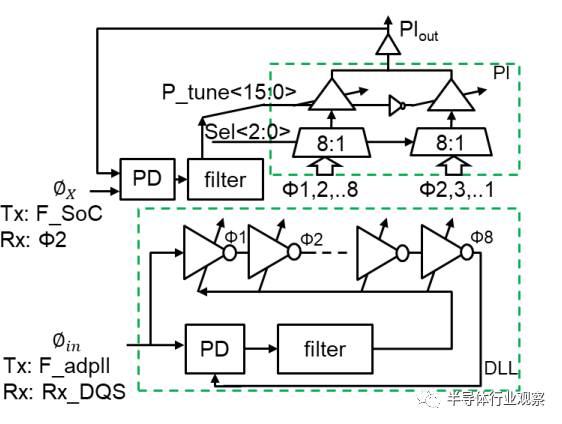
图 6. 去偏移环路(Deskew Loop)
具有延迟 T(T 是 DLL 输入时钟周期时间)的延迟元件的传递函数可以表示为 exp(-Ts)。图 7 (a) 是一个线性化的 DLL,其中明确显示了延迟元件。从噪声传输的角度来看,DLL 是输入时钟噪声的全通滤波器,在 DLL 带宽附近有轻微的抖动放大。在图 7 (b) 中,我们提供了一个更详细的 8 相 DLL 模型,其中延迟元件及其控制增益级分为 8 段。这更准确地建模了整体抖动传递函数。图 7 (c) 是 PI 控制回路。可以相应地分析整体抖动传递函数。图 8(左)显示了 8 个输出相位vs DLL 输入相位的抖动传递函数。图 8(右)显示了 DLL + PI 传递函数的整体抖动传递,取决于所选的 DLL 相位(Φ1...Φ8)。很明显,去偏移环路会放大抖动,从而导致转发时钟系统中的抖动跟踪不完整。理想情况下,如果我们忽略延迟元素(即 exp(-Ts) = 1),则去偏斜环路是一个全通滤波器。因此,到去偏移环路输入的转发时钟抖动(包括随机抖动和电源抖动)将完全由数据接收器端的数据路径上的抖动跟踪,正如转发时钟架构所期望的那样。请注意,DLL 和 PI 本身也会产生噪声,但噪声可以忽略不计,因为反相器缓冲区的深度仅为约 10 个反相器深度。DLL 延迟线的电源噪声由 DLL 高通,由 PI 环路低通。如果 DLL 和 PI 环路之间存在带宽失准,则 DLL 延迟线上的一些电源噪声频谱可能会泄漏到 PI 输出。PI 的电源噪声通过高通到输出端。抖动影响是相似的。基于上述分析,时钟抖动、PVT 偏移和电源下降将主要由去偏移环路跟踪。残余抖动,包括抖动放大部分、DLL 和 PI 自身产生的 Dj 和 Rj,以及时钟和数据路径不匹配导致的 Dj,会侵蚀眼图裕度,是系统预算的一部分,通过行为仿真建模。
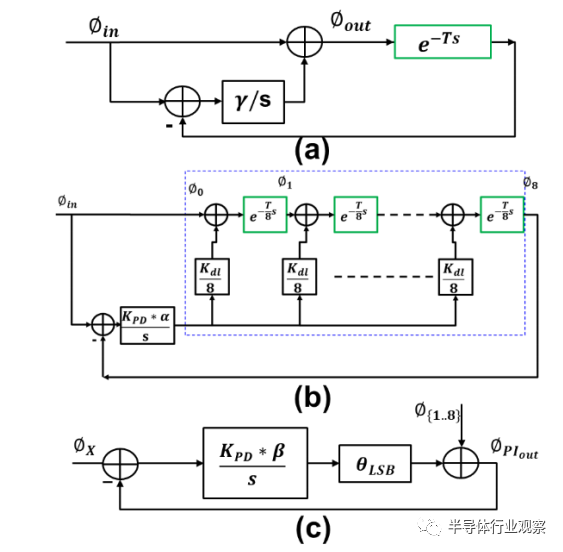
图 7. 线性模型 (a) 传统 DLL (b) 具有延迟元件的 8 相 DLL 模型 (c) PI 环路线性模型
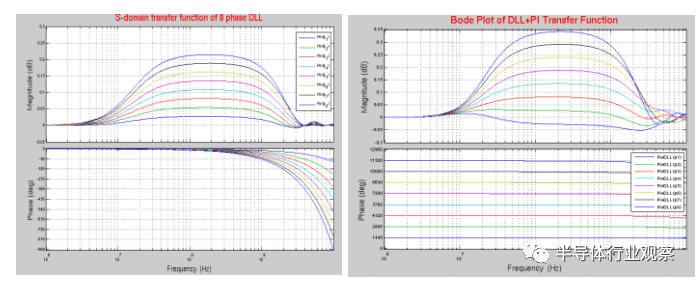
图 8. 去偏移环路的抖动传输(左:从 DLL 时钟输入到 8 相输出的抖动,右:整体去偏移环路抖动传输)
电源分配网络对电源完整性很重要。必须尽量减少电路板、基板、中介层和芯片上电源网络的 IR 压降。在上电/断电和电源管理期间,板载、封装、插入器上(on-interposer)和/或片上去耦电容是抑制电压纹波所必需的。图 9 显示了水平裸片到裸片互连的供电网络性能,具有各种去耦电容选项:无去耦电容、带有 TDC(顶部裸片电容)、eDTC(嵌入式深沟槽电容器)或 TDC 和 eDTC 的组合。基本上,包括片上 MOSCAP 和 MOM(金属氧化物金属)电容的 TDC 对高频噪声最有效。另一方面,eDTC 的电容密度大约比 MOM(金属氧化物金属)电容高 30 倍,但由于更高的 ESR(有效串联电阻),可能不具有良好的高频特性。为了实现 20mVpp 的目标电压噪声,eDTC 在此特定设计中效率最高。这让使用更少的片上decap来缩小 PHY面积成为可能。值得注意的是,如果使用的片上去耦电容不足,则通过片上 P/G 网络的动态 IR 压降可能会加剧串扰。图中未显示的 MIM(金属绝缘体金属)也是不错的decap选择。其电容密度是 MOM 电容的 3 倍至 10 倍,ESR 位于 TDC 和 eDTC 之间。
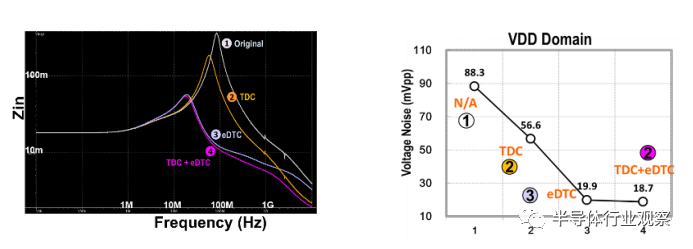
图 9. 不同去耦电容的功率传输特性和电源噪声
通道优化是 3D-IC DTCO(设计和技术协同优化)的一部分。用于水平 D2D 互连的封装(设计 1 图 10)具有高达 11mVrms ICN(集成串扰噪声),FEXT/NEXT 为 -27dB,尽管中介层中有电源/接地屏蔽,如剖面图所示图 10。这不是 8Gbps 数据速率的问题。然而,为了将线带宽密度(shoreline bandwidth density)提高到 16Gbps 或 32Gbps(眼高和眼宽更加压缩),需要改善串扰噪声。图 11 显示了 Design2。添加电源/接地屏蔽凸块可将串扰改善 8dB 以上。随着我们增加每通道数据速率,线带宽密度(shoreline bandwidth density)将增加,我们能够在 28Gbps 通道速率下实现 7Tbps/mm 的峰值带宽密度(图 12)。然而,由于插入损耗和串扰恶化,高通道速率 (32Gbps) 下的带宽密度变得更差。在更高的数据速率下,我们必须减少通道(lane)深度,这会降低线吞吐量(shoreline throughput)。

图 10. D2D 互连串扰减少(凸块顶视图和中介层剖面图)
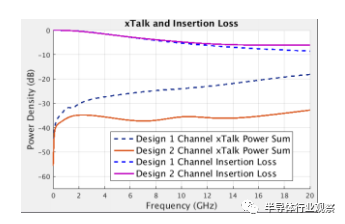
图 11. 串扰和插入损耗
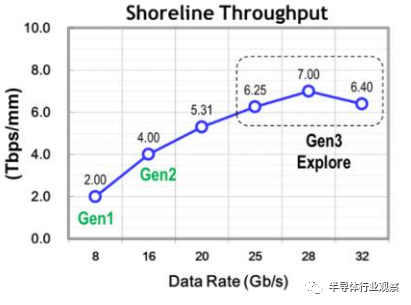
图 12.线吞吐量(Shoreline throughput)
由于间距小(水平互连为 40um,垂直互连为 9um),因此无法直接探测芯片到芯片互连。内置自检电路是检查电路质量的必备工具,包括良率筛选和运行裕度。图 13 显示了 8Gbps 互连的基于误码率的眼图扫描。在与其他小芯片集成之前用于筛选 KGD(已知良好芯片)的晶圆级测试,以及用于筛选 KGS(已知良好系统)的封装部件测试是用于硅后验证的 DFT 基础设施的一部分。来自 KGD/GDS 的有缺陷的零件通过前面提到的冗余通道进行修复。
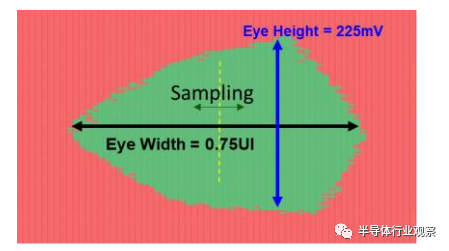
图 13.片内眼裕量测试(On die eye margin test)(在 VDD=0.75 和 VDDQ=0.3 时测量)
V.讨论与结论
图14是水平互连和垂直互连的芯片显微图。8Gbps 版本是独立 IP 验证工具中具有生产价值的设计(相对于其中的测试芯片),主要关注电源和信号完整性以及通道设计协同优化。垂直 D2D 互连设计用于复杂的 3D 堆叠,用于 3D 封装和工艺 DTCO。
图 14. 芯片到芯片互连的显微照片
(左:水平,右:垂直)
图 15 是上述 8Gbps 水平 D2D 互连的晶圆级 KGD 测试的电压和频率 schmoo 图。最初,需要将 Vcc_mim 提高到 0.82Volt 才能无错误。这是由探针卡针上的电源下降和 IR 下降以及内部电源下降(仅影响测试逻辑)造成的电压纹波的根本原因。当数据传输活动被顺序触发时,Vcc_mim 降低到 0.7V。通过调整采样时钟位置,可以在 Vcc_min 为 0.64V时进一步提高裕量。实验室分析表明,探针的 IR 压降会消耗 30mV 的电压裕度。对 16Gbps 垂直 D2D 互连进行了类似的裕量测试(图 16)。
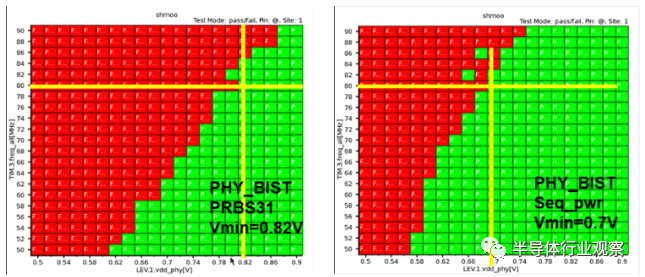
图 15. 电压和频率 Schmoo 图 (8Gbps)
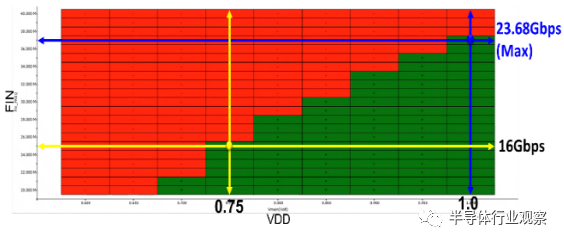
图 16. 电压和频率 Schmoo 图 (16Gbps)
如果 PDN 网络不健壮(robust),供应下降可能是一个严重的性能问题,如先前 shmoo 图中的边际损失所示。图 17 显示了主电压域上的测量电流逐渐上升并稳定地达到稳定状态,没有明显的扰动。
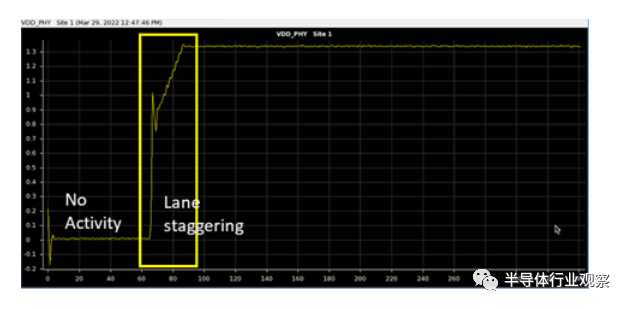
图 17. 通道交错通过顺序激活数据通道来减少电压纹波
在我们的实现中,我们对发送数据接口使用去偏移循环来避免额外的 Tx FIFO 延迟。我们能够实现 4ns 的总链路延迟。除非我们同步两个互连小芯片的时钟域,否则我们无法避免 Rx FIFO。其他类型的时钟架构可用于最小化时钟/数据路径失配,同时减少偏斜和抖动影响。
如上所述,垂直芯片到芯片互连不受凸块限制,不同于水平芯片到芯片互连。随着晶圆键合技术向更紧密的键合间距发展,更简单的互连拓扑可能比第 III 节中介绍的架构更加节能和具有更低延迟。通过更紧密的键合间距和更小的键合电容,每条通道(lane)的数据速率可以降低到 2Gbps 或更低,从而允许对芯片到芯片交叉电路使用简单的反相器缓冲器,而时钟域交叉则使用常规触发器。可以消除包括时钟单元和去偏移环路在内的所有开销。仍然需要降低额定值的 ESD 结构。、尽管每条通道的数据速率较低,但由于更高的键密度,可以实现更高的面积带宽密度和更好的能源效率。在适当的时序预算和跨芯片时序仿真的帮助下,整个 PHY 接口可以由 CAD 工具自动处理。图 18 显示了未来 3DIC 互连的前景。使用的品质因数是带宽/能量效率比。串行 IO 将覆盖 2.5D 互连,通道可达约 2mm。当凸块间距约为 25um 时,串行 IO 有利于垂直芯片堆叠方案。通过减小间距和通道范围 (~100um),数字 Lite-IO(即 CMOS 反相器)实现了 100 倍的带宽/能效比。
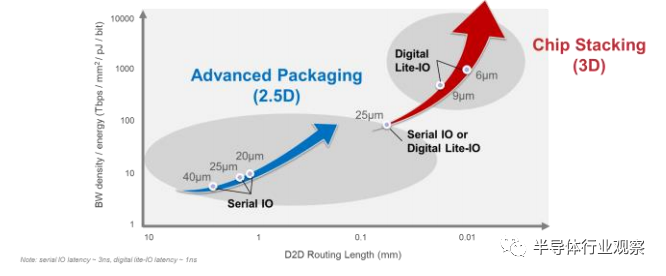
图 18. 3DIC 互连的前景
总之,我们提出了 3DIC 时代的设计挑战。CMOS 缩放正在接近其物理极限。3D-IC 是一种使计算系统能够分解为不同技术节点中的许多小芯片的使能技术,并且由于减少了互连距离和增加了互连带宽,还提供了更好的功率、性能、面积和成本方面的好处。我们展示了两种用于水平和垂直 D2D 集成的互连技术,具有世界一流的能效和带宽密度。我们展示了水平 D2D 互连的峰值带宽密度可以达到 7Tbps/mm。垂直 D2D 互连的带宽密度将随着键距的缩小而继续增长。
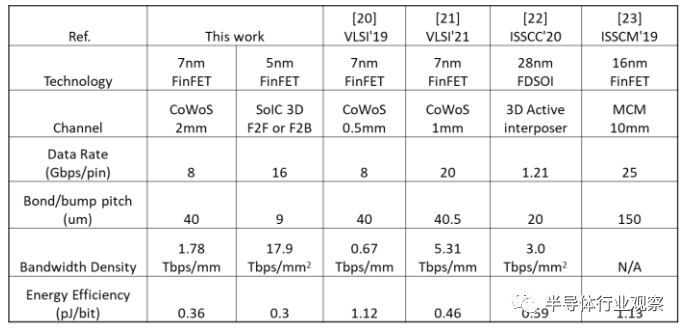
与现有技术状态的比较如表 1 所示。
表1. 性能比较
作者
Shenggao Li, Mu-shan Lin, Wei-Chih Chen, Chien-Chun Tsai, Cheng-Hsiang Hsieh
TSMC Inc.










