

GPT-5.5,刚刚降临。
官方定位,“一种面向实际工作和智能体的新型智能。
这次奥特曼没有自己站出来说“初体验被吓到眩晕瘫坐,那一刻就像看到原子弹爆炸”了,而是请了一群嘴替(早期测试用户)。
其中有一位英伟达工程师,他在早期测试结束后短暂的失去了GPT-5.5的访问权限,然后说了这样一句话:

失去GPT-5.5,就像被截肢。
说归说,闹归闹。
OpenAI与英伟达这次的合作是前所未有的。
第 一,GPT-5.5和英伟达GB200、GB300 NVL72系统是联合设计的,训练到部署,模型和硬件之间从诞生开始就双向奔赴。
第二,推广Codex到英伟达全公司,奥特曼还晒出了与老黄的邮件。
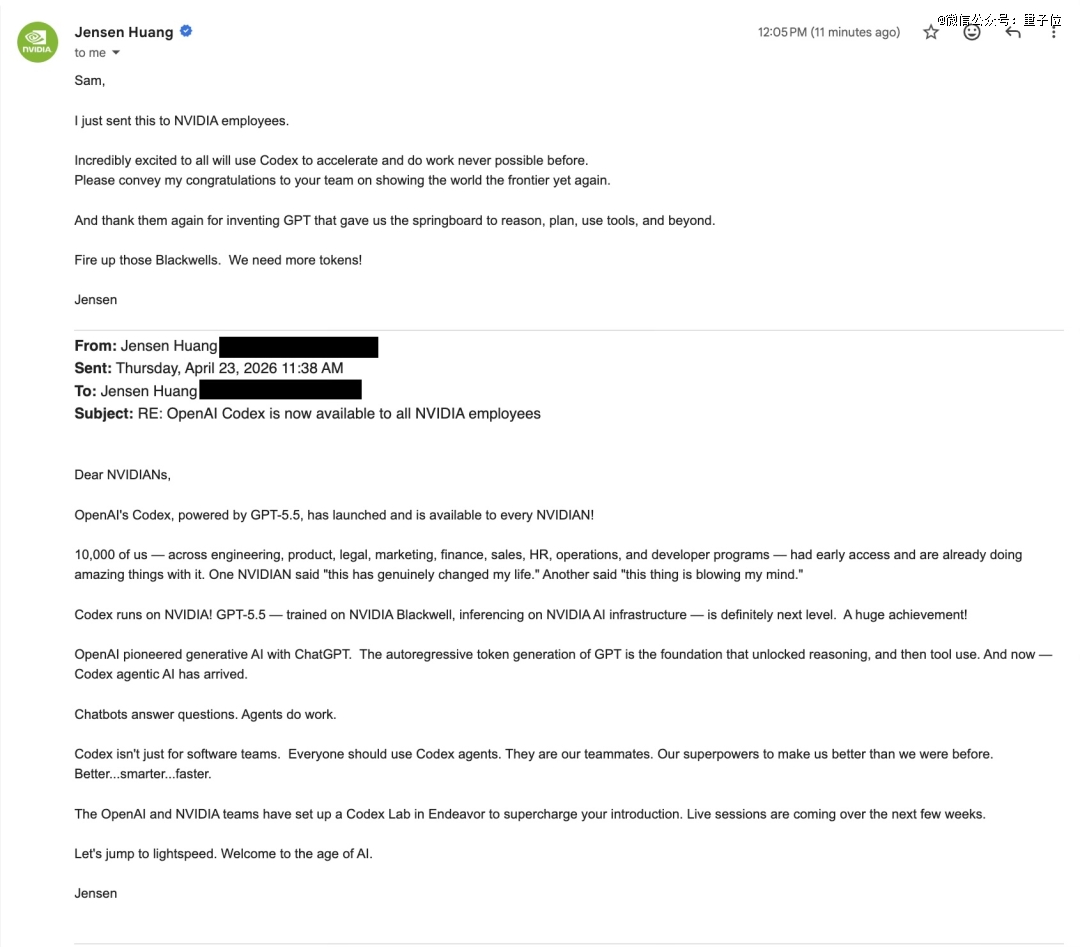
合作的成果,先来看数据。
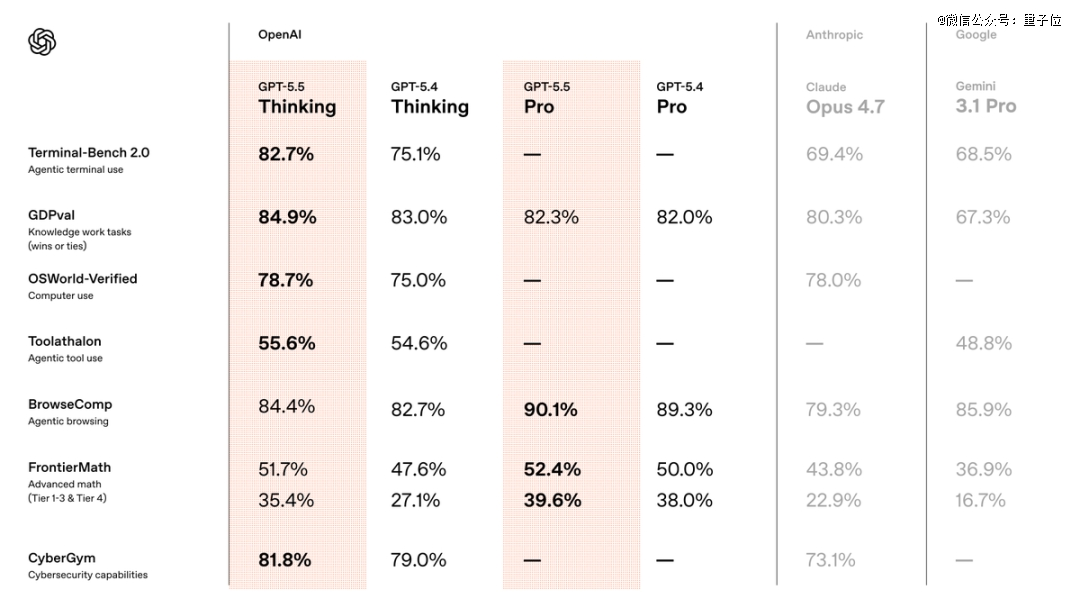
与上个版本GPT5.4相比,新模型在代码、知识工作、科学研究三个领域全部拉开身位。
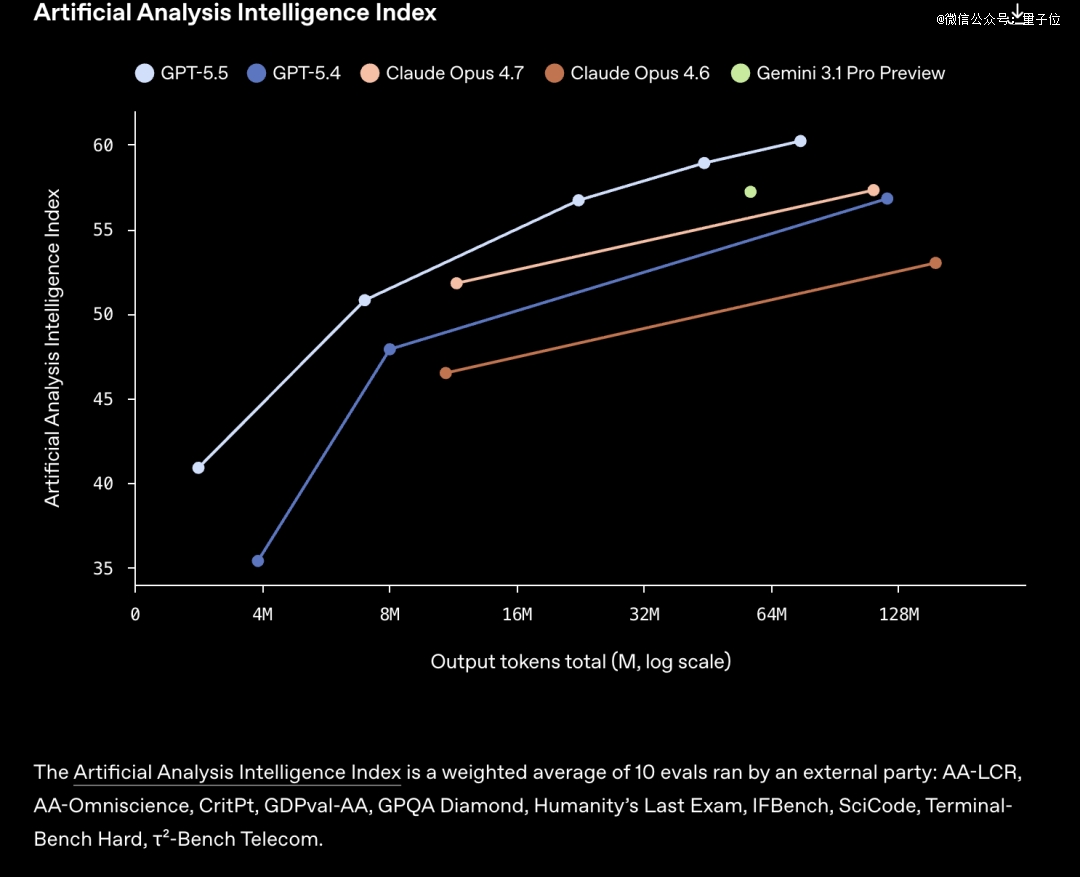
综合测试Artificial Analysis Intelligence Index结果,有两种解读方式:
GPT-5.5获得相同的分数比Claude Opus 4.7和其他模型消耗token更少。
或者消耗同样的token,GPT-5.5完成的任务更多。
但最让人意外的不是跑分。
过去每一次模型升级,“更强”和“更慢”几乎是打包出售的。
这是Scaling Law的代价,更大的模型,更多的参数,更长的思考时间。用户为智能买单的同时也在为延迟买单。
GPT-5.5打破了这条铁律。
在真实生产环境中,它的逐token延迟和GPT-5.4相当,完成相同任务需要的token还比GPT5.4少了。
效率更高,功能更强大。
(但价格翻倍)

截至发稿,Codex更新最新版已经能用上GPT-5.5。
上下文窗口也升级到400K

给编程开挂
编程是GPT-5.5提升最猛的领域。
上一代模型用起来,还是得小心翼翼地拆任务,一步步看着它走,随时准备纠偏。
GPT-5.5不一样了。你把需求丢过去,它自己拆解、自己执行、自己检查。你只需要看结果。
OpenAI展示了Codex下GPT-5.5生成的3D动作游戏,在网页上直接运行。
包括用TypeScript/Three.js实现战斗系统、敌人遭遇、HUD反馈以及GPT生成的环境纹理。
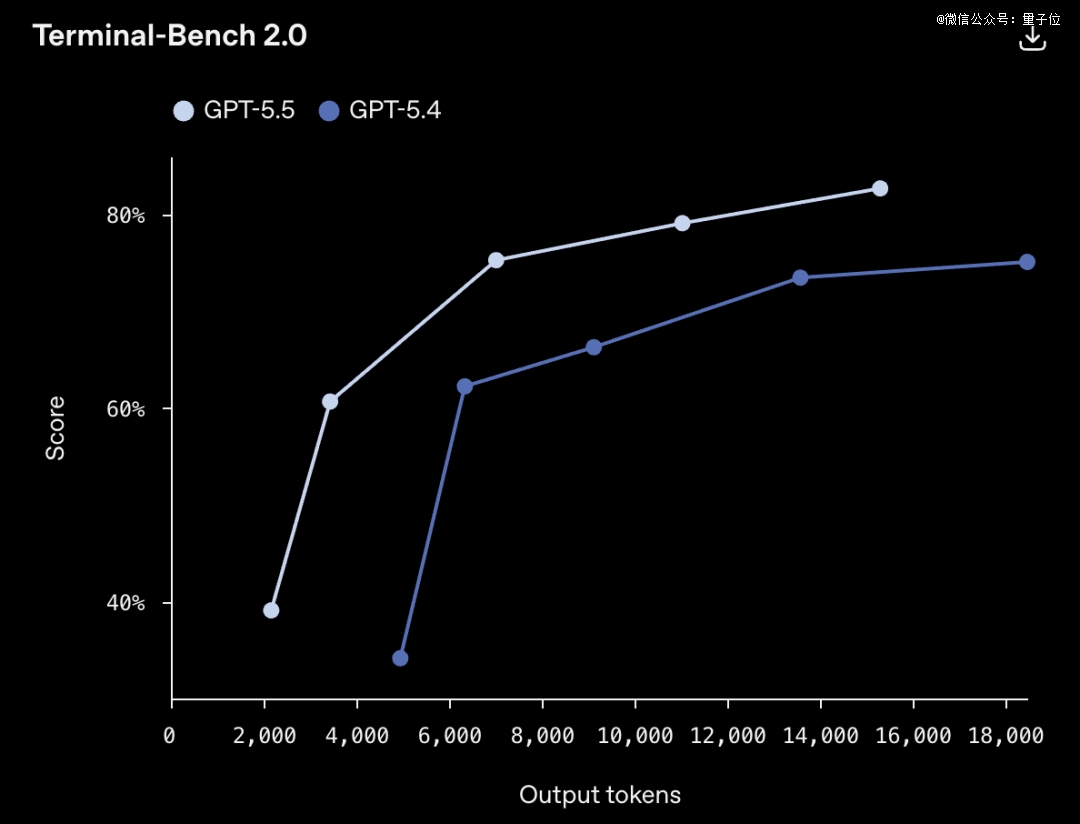
Terminal-Bench 2.0,衡量复杂命令行工作流的硬核测试,GPT-5.5拿到82.7%。
上一个版本本的GPT-5.4是75.1%,目前最强竞品Claude Opus 4.7是69.4%。
可以理解为:碰到这种级别的难题,上一代模型将近三分之一会卡住,现在这个比例压到了四分之一以下。
接下来请各路嘴替:
早期测试者Dan Shipper做了一个实验。他是初创公司CEO,同时也是一位活跃的AI产品开发者。
他的App上线后出了一个bug,请了一位顶 尖工程师来重构。工程师花了一番功夫,最终给出了一个解决方案。
然后Shipper把时钟拨回去:把那段有bug的代码丢给模型,看它能不能独立做出和那位工程师一样的决策。
GPT-5.4做不到。GPT-5.5做到了。
Shipper说,这是他第 一次在一个编程模型身上感受到真正的“概念清晰度”。
不是接话,是理解了问题之后自己想明白如何解决。

越来越多高级工程师在反馈同一件事:GPT-5.5在推理和自主性上明显强于GPT-5.4和Claude Opus 4.7。
它能够提前发现问题,并在无需明确提示的情况下预测测试和审查需求。

编程只是开始。同样的能力跃迁,正在向知识工作和科学研究两个方向扩散。
编程之外
GPT-5.5在Codex里干的事,远不止写程序。生成文档、整理表格、做PPT。
OpenAI多次强调,它比上一代更懂你想要什么。
更关键的是,它会自己用工具、自己检查输出对不对。你给一个模糊的想法,它能帮你补完剩下的。
这里有个数据很有意思,OpenAI自己超过85%的员工,每周都在用Codex干活。(另外15%是怎么回事?)
还是先看评测结果。
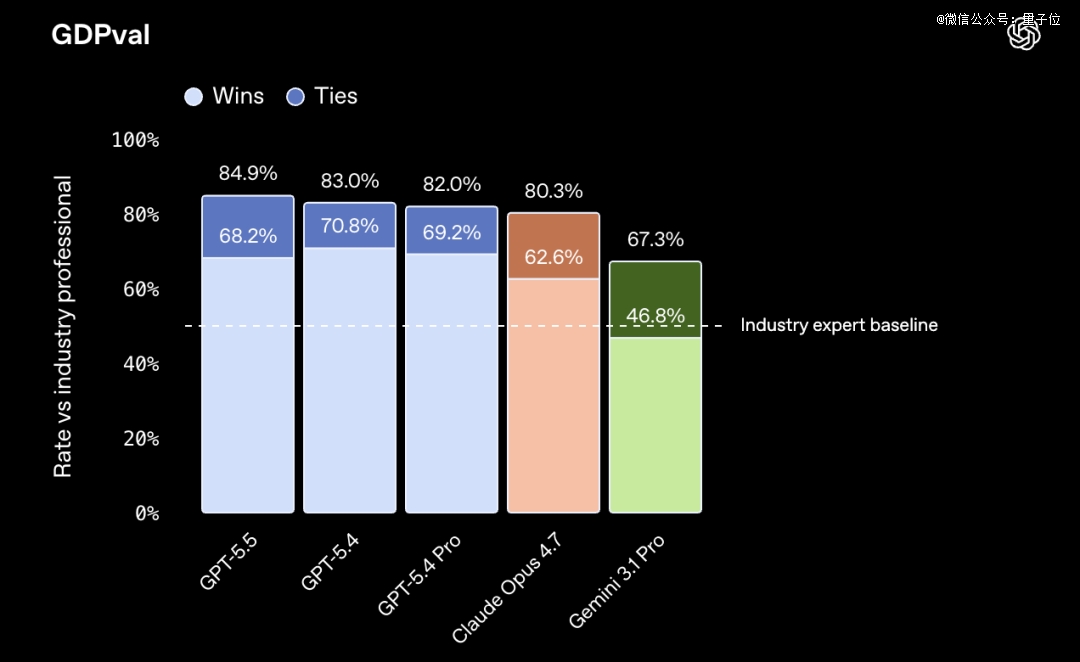
在知识工作基准测试GDPval上,GPT-5.5拿到84.9%,比Claude Opus 4.7高出4.6个百分点。
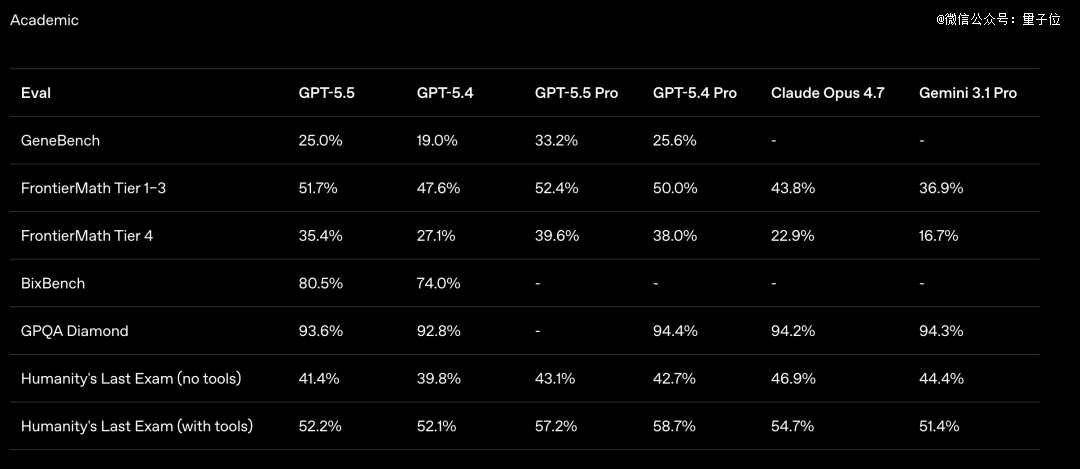
FrontierMath Tier 4,目前最难的数学基准之一,题目来自未发表的论文和顶 尖研究者的开放问题。
GPT-5.5 Pro在这个测试上拿下了39.6%。Claude Opus 4.7是22.9%,差距接近一倍了。
真正有意思的是科学家们怎么用它。
Bartosz Naskręcki是波兰亚当·密茨凯维奇大学的数学助理教授。他给Codex写了一句话,11分钟后,一个代数几何可视化应用就跑起来了。
这个应用能画出两个二次曲面的交线,标成红色,还能用Riemann-Roch定理把交线转成Weierstrass曲线的标准形式。后来他又扩展了更稳定的奇点可视化功能。
一句话,11分钟。搁以前,光是搭项目框架就得半天。
Derya Unutmaz是杰克逊基因组医学实验室的免疫学教授。他用GPT-5.5 Pro分析了一份基因表达数据集:62个样本,将近28000个基因。最后产出了一份完整的研究报告。
他说,这本来要花团队几个月的时间。
OpenAI对GPT-5.5在科研中的定位,有一句话概括得很准,它不再像一次性答案引擎,更像一个”研究伙伴”。
早期测试者拿它做的不只是查资料。多轮批改论文,逐条挑论证的漏洞,提出新的分析方案。它记住了你整个研究脉络,每一轮对话都建立在前一轮的基础上。
GPT-5.5在数学领域做了一件大事。
Ramsey数,组合数学里最核心的问题之一。
通俗地说,它研究的是:一个网络要大到什么程度,才能保证某种秩序必然出现?
比如,六个人里一定有三个人互相认识,或者三个人互相不认识,这就是最简单的Ramsey定理。
它是数学界几十年的硬骨头,off-diagonal Ramsey数的渐近性质,更是长期悬而未决。
GPT-5.5找到了一个新的证明路径。不是复现已知方法,而是发现了一条新路。随后,这个证明被数学界最严格的形式化验证工具之一Lean确认无误。

一个AI,在纯数学的核心领域,做出了被形式化工具验证的原创贡献。
一年前,这还不可想象。
更强却不更快的秘密
“更强却更快”是怎么做到的?
答案不是在某一个环节上做了优化。OpenAI把整个推理系统推倒重来了。
前面提到GPT-5.5和英伟达GB200、GB300 NVL72系统是联合设计的,结果在同等延迟下,智能水平大幅跃升。
但还有另一个故事。
GPT-5.5驱动的Codex系统,分析了数周的生产流量数据,然后写出了一个负载均衡的分区启发式算法。
之前,请求被切分成固定数量的块,分发给加速器处理。但固定的分块策略在不同流量模式下并不总是*。有时候块分得太粗,有时候太细,资源利用率忽高忽低。
Codex看了几周的真实流量数据,自己写了一套自适应的分区算法。根据实际流量形态动态调整分块策略。
token生成速度提升了超过20%。
模型优化了运行自己的基础设施,AI在让自己跑得更快。
推理系统的整体重构,加上模型参与自身的优化,两件事叠在一起,带来了这样的结果。

OpenAI说,这是“迈向用计算机完成工作的新方式的一步”。
但当模型已经开始优化自己运行的基础设施——
这一步,到底迈了多远?
One More Thing
有了GPT-5.5,OpenAI预计接下来模型发布数据将加快。
我们看到短期内有相当显著的进步,中期有极其显著的进步。
我认为过去几年进展出乎意料地缓慢。
说这话的是首席科学家Jakub Pachocki ,场合是与记者的电话会议上。
参考链接:[1]https://openai.com/index/introducing-gpt-5-5/
[2]https://x.com/firstadopter/status/2047378435555651856?s=20











