

随着人工智能时代的到来,GPU成为了所有人关注的焦点。
但想要*化程度发挥出GPU的AI训练与推理功能,还要借助数据中心的力量,一座AI数据中心里往往装着数以万计的GPU,正是通过这种协同作用,才有了像 ChatGPT 这样功能强大的聊天机器人。
但AI数据中心的价格并不低,动辄数十亿美元的造价,不止是科技巨头们的专属,也让很多实力并不雄厚的国家地区望而却步。
随着使用人工智能所能做的事情越来越多,高端芯片的地缘政治重要性也与日俱增,越来越多的国家和地区正在竞相囤积芯片,甚至还颁布了阻止部分国家地区购买最尖端芯片的制裁措施,但截至目前,关于全球人工智能芯片的确切位置的公开数据却出奇地缺乏。
来自牛津大学互联网研究所教授 Vili Lehdonvirta揭露了一个不可忽视的现实:GPU 高度集中在全球仅 30 个国家地区之中,其中,美国和中国遥遥*,而大部分地区都处于所谓的“计算荒漠”中:根本没有 GPU 可供租用。
如何调查分布
全球AI计算供应链大致可以分为四个部分:
设计和销售GPU及其他与AI相关芯片的公司
制造和封装芯片的公司
部署芯片提供计算能力的公司
消耗计算能力开发或部署AI系统的公司
在GPU设计和销售方面的市场*是总部位于美国的Nvidia公司,芯片制造由台湾的台积电(TSMC)主导,而荷兰的ASML目前是*生产光刻机的公司,这些机器对于制造*进的芯片至关重要(Miller 2022)。因此,计算供应链的这些部分在地理位置和所有权方面都高度集中。
这项研究关注的是供应链的第三步:全球哪些地区部署了芯片来提供AI计算以用于AI开发和部署,也就是用于训练AI模型和运行现有模型的推理。大致上,有三类大规模的计算提供者:科学超级计算设施、私人计算集群和所谓的公共云计算提供者。
科学超级计算设施自20世纪60年代初以来就已存在,通常由政府资助,主要用于学术和军事目的。OECD(2023)的一项研究对科学超级计算设施进行了简单的地理分析。根据TOP500数据库,中国的超级计算机数量最多,占32%;其次是美国,占25%;欧盟占21%。然而,大多数科学超级计算机并非为AI模型训练设计(OECD 2023)。当前生成式AI发展的繁荣主要依赖于私人计算集群和公共云计算。之前的研究并未详细分析它们的地理分布。
私人计算集群由营利性公司拥有,如Meta、HP以及许多小型公司。这些集群由部署在数据中心的GPU互连计算机组成。一个私人集群既可以用于该公司的AI开发,也可以租给其他公司使用。公共云计算提供者同样是营利性公司。它们之所以被称为“公共”,并不是因为与政府有关,而是因为它们的服务是按需提供的,并由多个客户共享(即类似于酒馆中“公共”的含义,而不是公共部门的“公共”)。公共云计算市场的*包括AWS、Microsoft Azure和Google Cloud;中国的公共云提供者阿里巴巴和腾讯也提供大规模AI计算。这些大型提供者通常被称为“超大规模计算提供者”。
其中该研究主要关注了公共云AI计算的地理分布。私人计算集群曾用于训练一些标志性模型,如Meta的Llama和Llama 2。但大量前沿AI模型的训练和开发集中在公共云的超大规模提供者Google、Microsoft和Amazon,以及它们与*AI公司的“计算合作伙伴关系”中,如Anthropic、Cohere、Google DeepMind、Hugging Face、OpenAI和Stability AI。公共云还很重要,因为它对许多不同类型的开发人员开放,包括学术研究人员。因此,我们的主要研究问题是:全球公共云AI计算的地理分布情况如何?我们还将探讨这些地理分布的潜在原因,讨论它们对计算治理和地缘政治的影响,最后简要讨论私人集群和政府拥有的国家AI计算。
该研究的普查涵盖了六大超大规模公共云提供商:AWS、Microsoft、Google、阿里巴巴、华为和腾讯。虽然也有一些较小的提供商,但这六家占据了全球公共云市场的大部分份额,并且在各区域市场中也处于*地位。在普查进行时,训练常见AI模型的最强大GPU是Nvidia于2023年推出的H100,之前的旗舰型号A100于2020年推出,V100更早于2017年推出。2023年,Nvidia引入了H800和A800以规避美国对中国的出口限制,但这些限制很快扩展到了这些新型号。数据收集的重点放在这五种与AI最相关的GPU类型上。
从普查数据库中,该研究构建了一个国家级的数据集,以便进行地理分析。对于每个国家,其计算了其领土内的公共云区域总数,还计算了至少支持一种GPU的区域(“支持GPU的区域”)的子集,以及支持特定GPU类型的区域子集。
为了补充云普查数据,研究进行了定性和半结构化的专家访谈。我们总共采访了10位信息提供者,分别代表了两位政策专家、三位超大规模公共云提供商专家和五位在AI计算方面具有专业知识的研究专家。这些信息提供者通过我们自身的专业网络采用滚雪球采样方式招募。这些访谈的主要目标是改进并验证普查方法,生成关于公共云AI计算地理分布的补充或替代信息,并帮助解释观察到的地理模式。
AI GPU在哪里?
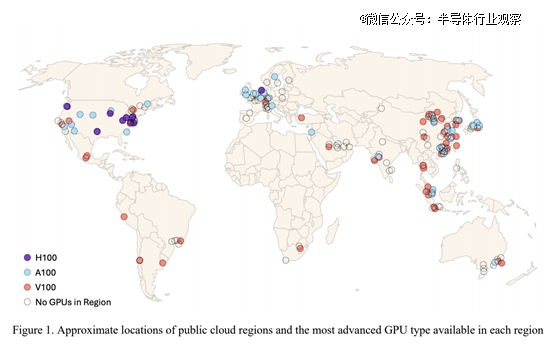
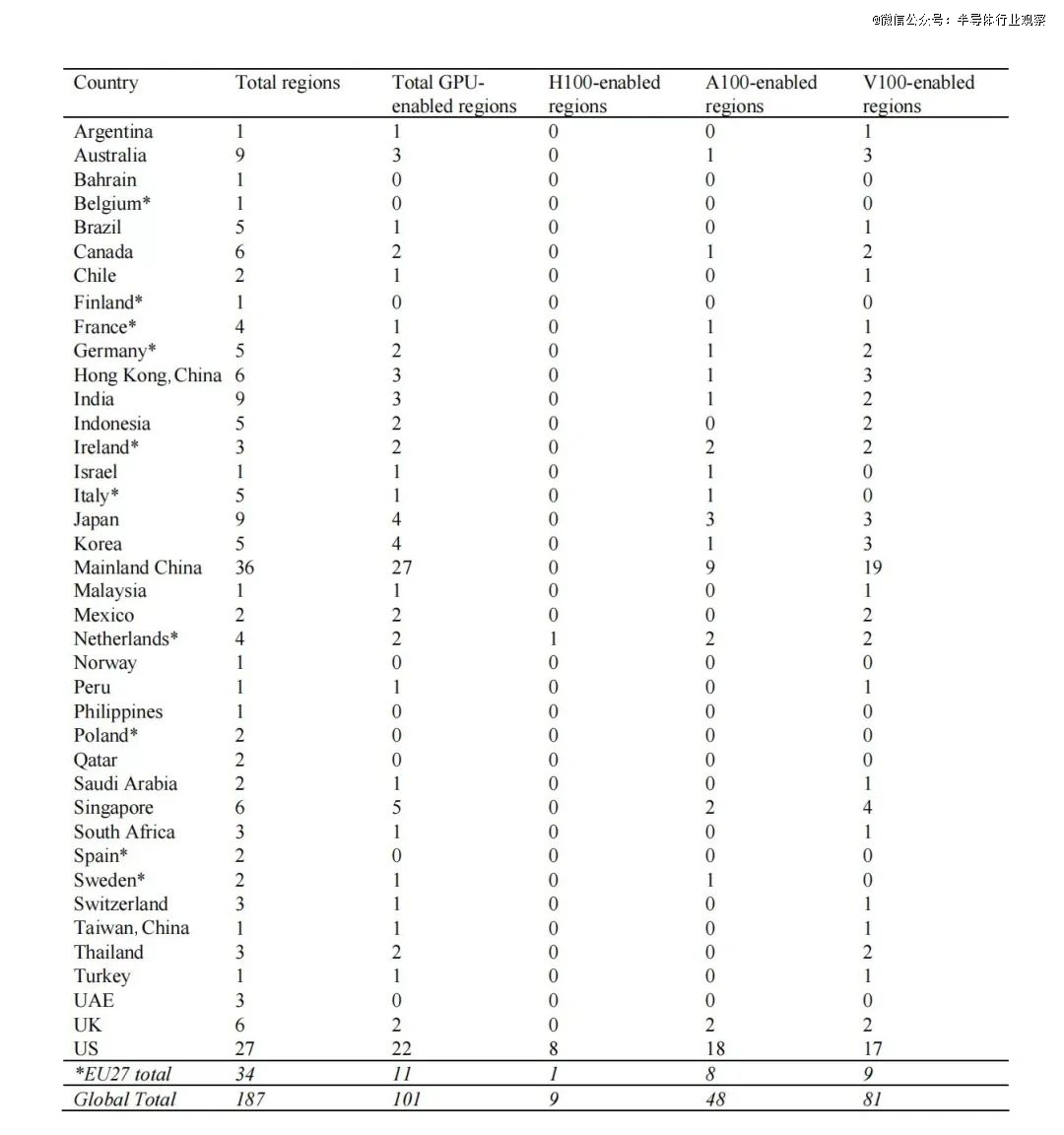
图1展示了普查中发现的公共云区域的大致位置。表4则显示了每个国家有多少个云区域,以及这些区域中有多少提供GPU实例。从计算治理的角度来看,数据中最重要的特征之一是,世界上绝大多数国家根本没有公共云区域。在拥有一个或多个云区域的39个国家中,有30个国家的云区域支持GPU。
另一个显著特征是,即使在那些拥有支持GPU的云区域的国家内,区域的地理分布也是高度极化的:中国和美国合计拥有的区域数(49个)几乎与世界其他国家的总和(52个)相当。在这两者中,中国的GPU支持区域总数略高(27个)于美国(22个)。
进一步的分析可以通过考察每个国家所提供的GPU实例类型来进行。最明显的模式是,美国不仅在不同类型实例的可用比例上拥有世界上最新和最强大的GPU,在*数量上也是如此。美国是*一个提供2020年Nvidia A100 GPU的区域多于2017年V100 GPU的国家。美国还拥有多个提供2023年Nvidia H100 GPU的区域。中国的云区域主要基于V100,少数区域提供A100实例。中国没有任何区域提供H100。全球其他地区仅有15个国家提供A100,只有一个国家提供H100,其余的区域纯粹基于V100。
此分析没有考虑自定义加速芯片(如TPU),也没有考虑不同区域内可用的GPU数量的差异。访谈信息提供者指出,不同区域内可用的同类型GPU数量可能在不同区域和提供商之间差异显著。一位信息提供者指出:“超大规模云服务提供商在计算或存储方面几乎给人一种无所不能的印象,似乎可以处理你带来的任何问题。但这并不完全是现实。”在某些情况下,某一区域内可用的GPU数量可能非常有限,导致只有有限数量的客户可以在该区域运行GPU实例,或者只能在合理的时间内训练较小规模的模型。
目前认为AWS和Microsoft拥有*规模的云GPU集群,但“在这方面,区域之间*不相同”。不过,GPU数量及其在提供商区域内的分布被超大规模云提供商视为高度机密的信息。我们的信息提供者中没有人愿意或能够提供具体的数据,也无法指出如何公开获取这些信息。但普遍认为,美国地区的GPU数量可能比世界其他拥有同类GPU的区域要大得多。中国的区域可能也会有更多的V100芯片,以弥补其相对较低的性能。我们的访谈表明,即使可以在此分析中纳入每个区域的GPU数量,这可能也不会挑战上述的主要模式,反而更可能强化这些模式。
为何集中在美国?
美国在先进的公共云AI计算方面的*优势相较于中国和其他国家,背后有什么原因?一个显而易见的解释是美国政府的出口管制,禁止向中国出口A100和H100芯片。中国的云提供商在2023年出口管制生效前,能够进口一些A100芯片,但H100自产品发布以来就一直受到出口管制。同样,H800和A800芯片在推出后不久也被纳入出口管制。性能远不如这些芯片的V100是中国最常见的Nvidia GPU实例类型,因为它不受出口管制的限制。
然而,出口管制无法解释为什么除了中国之外的其他国家也主要部署了旧款GPU。几种解释是可能的。一个简单的解释是创新扩散的摩擦,指的是GPU在市场上扩散的过程。较新的GPU可能首先被安装在美国,因为Nvidia总部位于美国,因此在美国的分销网络最为强大。随着时间的推移,先进的GPU应该逐步扩散到相对较远的市场。“我假设几乎所有的GPU最初都进入了北美区域,但现在欧洲应该也有了相当规模的集群,”一位信息提供者推测。
美国云计算*的另一个潜在解释来自于初始需求结构上的地理差异,这与规模经济相结合,形成了一种“路径依赖”,从而维持了AI计算集中在某些地理区域的状况。一位信息提供者解释道:“很少有云计算买家真正从事开创性的AI开发......所以没有必要在各地分散能力......你需要几个超级集群,形成某些地点的计算能力临界质量,没必要在每个地方复制这种能力。”
最早集中进行大规模AI模型训练的公司和研究人员出现在美国,因此云提供商将最强大的训练计算能力集中在那里。但即便全球其他地方对计算的需求在增加,这并不必然转化为本地计算基础设施的相应增长,因为开发人员通常可以将训练任务发送到美国的云区域,而不会遭遇显著的性能损失。于是,美国最初的计算*地位得以持续。
信息提供者认为,用于部署AI的计算能力的情况有所不同。在许多AI用例中,例如语音助手,如果用户与服务器之间的距离过大,用户体验可能会受到延迟的影响。数据传输成本也可能成为一个业务问题。因此,这类应用*部署在离用户更近的计算基础设施上。这也解释了为什么性能不足以用于训练的V100芯片——尽管速度较慢但仍适用于推理任务——在全球范围内的分布比更先进的芯片更加均匀。
然而,也有一些例外情况与美国拥有*进GPU的普遍模式不符。日本、英国和法国每个国家都有与V100支持区域数量相同的A100支持区域。这些国家都有显著的本地AI开发活动。可能存在使本地开发者无法将数据发送到美国进行训练的法规或政治障碍。一位信息提供者指出:“目前,有些公共部门或重要的欧洲参与者需要用无法离开欧洲的数据训练GPT-4级别的模型......如果超大规模云提供商没有响应这一需求,我会感到惊讶。”
在这一背景下,信息提供者提到了有关“数字主权”、“数据主权”和“计算主权”的政策讨论,这可能会创造对本地训练计算需求的增加。荷兰和爱尔兰也拥有小而相对先进的GPU阵容。这可能与这些国家作为一些超大规模云提供商基础设施枢纽的战略地位有关。值得注意的是,荷兰是美国之外*一个拥有H100 GPU的云区域的国家。
私有和政府计算的全球分布
本研究的重点是公有云计算,这是一种重要但并非*的计算来源。在公有云计算中,我们的数据收集集中于Nvidia的GPU和六大*的超大规模云服务提供商。
不同类型的大规模计算提供商的相对地位是否会发生变化,挑战当前观察到的计算地理格局?GPU集群作为昂贵的资本品,需要高利用率才能实现合理的投资回报率,这解释了为什么大规模集群主要被构建为共享基础设施,不论是政府拥有的(如科学超级计算)还是近年来私有的(如公有云)。政府拥有的计算似乎正以“国家AI计算”计划的形式在全球范围内进行小规模回归。例如,美国的国家AI资源(NAIR)工作组旨在创建公有计算基础设施以“民主化AI研究”(。然而,许多情况下政府的投资规模似乎不足以真正挑战超大规模云服务提供商的主导地位。许多最近的政府努力也是在与这些超大规模云服务商的合作下进行的,实际上这些项目依赖于私有基础设施。
欧洲高性能计算联合体的新LUMI超级计算机提供了一个反例。LUMI位于芬兰Kajaani,由欧盟成员国政府合作建立,由Nvidia的竞争对手AMD设计的11,912个GPU组成集群。其规模可能会成为AI开发基础设施方面私有“公有”云计算基础设施的一个严肃替代方案。鉴于它位于欧盟,它并未挑战图2中显示的南北计算鸿沟。然而,它可能有助于打破美中两国作为*AI超级大国的两极形象。
新的私有计算集群也在增长。Google的TPU可能占据了相当大比例的AI计算。AWS和微软都计划生产自己的芯片。Meta宣布将大规模投资建设私有计算能力:首席执行官马克·扎克伯格声称将投资34万颗Nvidia H100和A100。2023年,微软声称花费数亿美元用于为OpenAI的ChatGPT聊天机器人提供动力的集群。大型科技公司可能仅凭其内部和合作伙伴的需求就能实现大规模集群的高利用率。但最初部署为私有的集群在内部需求减少后,可能会转变为共享的云基础设施。这模糊了私有和公有(如公共住房)云计算能力之间的区别。
一道AI计算的鸿沟
通过计算来治理AI是一个有力的理念,因为计算由大型、可观察的物质基础设施组成。这些基础设施必须物理地位于某个地方,因此容易受到领土管辖权的影响,而领土管辖权是所有国家——无论大小——*执行力的管辖形式。然而研究显示,计算基础设施并未均匀分布在全球各地,它们的地理分布很大程度上决定了不同国家将计算作为AI干预点的可能性。
研究重现了两个AI超级大国陷入计算“军备竞赛”的熟悉观点,其中,美国在芯片质量方面占据优势,而中国试图通过数量来弥补差距。美国对先进GPU的出口限制似乎起到了作用,因为没有任何公共云提供商在中国提供2023年的H100芯片,也没有提供为规避这些限制而开发的H800或A800。同样地,俄罗斯和伊朗这两个受西方制裁的国家在我们的样本中也没有任何公共云AI计算设施。
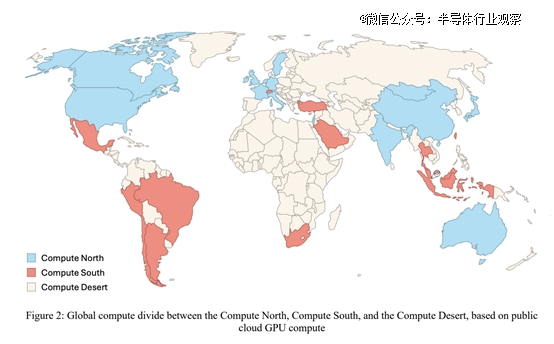
然而,除了地缘政治大国竞争的观点之外,研究还提出了与基于计算的AI治理相关的其他概念类别。除了美国和中国之外,还有另外15个国家也拥有对AI发展最为重要的GPU,即A100和H100。这些*梯队的国家,除了印度之外,均位于所谓的“全球北方”。类比而言,将它们称为“计算北方”。这些计算北方国家可以利用其领土管辖权来干预AI发展,特别是在模型被发送到其本地公共云区域进行训练时。例如,它们可以要求算法和数据集在训练开始之前通过审计并获得符合本地规则的认证,从而影响进入全球市场的AI系统的类型。
第二梯队包括13个国家,它们的计算能力更适合AI系统的部署而非开发。除了瑞士之外,这些国家都位于全球南方,因此将它们称为“计算南方”。例如,拉丁美洲共有五个GPU支持的云区域,但它们没有一个配备了比2017年发布的V100更强大的GPU。这些国家能够利用其对计算的领土管辖权来把关哪些AI系统可以在本地部署,但对于AI系统开发的影响较小。
除了“计算北方”和“计算南方”,还有一个“计算沙漠”,用此术语指代世界上所有不具备任何公共云AI计算(无论是用于训练还是部署)的国家。对于这些国家而言,转向基于云的AI服务意味着依赖于在外国司法管辖区内开发和部署的基础设施。计算沙漠包括一些富裕国家,但也包括国际货币基金组织(IMF)分类的所有中低收入国家和低收入国家。计算沙漠国家的影响可能因其富裕程度而有所不同。沙漠中的富裕国家可能能够利用其其他优势——例如对计算北方国家的外交影响力以及足以建设政府拥有的计算能力的财富——来抵消其缺乏本地公共云AI计算的劣势,但计算沙漠中的贫穷国家几乎没有前景可以通过计算治理来影响AI。
类似于研究人员观察到学术界和工业界之间存在“计算鸿沟”,研究也观察到了全球计算鸿沟,公共云AI计算的地理分布似乎在重现全球不平等的熟悉模式。从1990年代中期开始,有关数字化的讨论提出,成功进入新的全球“知识经济”将基于知识和创造力等非物质资产,而不再依赖于工业经济时代所需的物质资产和资源。这意味着发展中国家可以跳过昂贵的基础设施投资,直接进入基于知识的经济模式。然而,今天关于AI的讨论再次强调了芯片制造厂、数据中心和电力网络等物质基础设施对于国家竞争力的关键作用。如果计算成为一个关键的治理节点,那么这些物质基础设施可能也会被证明对于保持独立的监管权力至关重要(Lehdonvirta 2023)。因此,一个国家的计算能力在某种程度上也等同于其政治权力。
这种情况会发生变化吗?如果高端AI计算集中在美国和“计算北方”只是由于创新扩散过程中的摩擦所致,那么随着时间的推移,全球可能会逐渐充满计算能力,缩小这种差距。Nvidia的竞争对手,如AMD和英特尔,正在芯片性能方面追赶。中国厂商也在开发AI处理芯片,并且由于美国的出口控制,中国国内对其需求巨大,再加上政府的支持,这种差距可能会逐步
但是,如果观察到的地理模式更多是由先行者优势和规模经济导致的路径依赖解释的,那么地理集中、区域专业化以及国际劳动分工可能将成为计算生产的持久特征,正如在许多其他行业中一样。
写在最后
谁拥有了最多的GPU?这个问题的答案似乎早已呼之欲出,但在这一问题的背后,本质上是算力的不均匀分布。而如何改善算力的不平衡,让处于计算荒漠的更多人享受到AI所带来的便利,恐怕短时间内是很难解决的了。










