

引言
2024年的开年震撼同样来自OpenAI。节后还没开工,Altman就带着继ChatGPT的第二个杀手级应用Sora大杀四方。适道看完那条长达60s的演示视频后,脑中只有一句话:大家谁都别想玩了。快速回归理智,Sora统治之下,是否还有其他机会?我们从a16z发布的展望——“Why 2023 Was AI Video’s Breakout Year, and What to Expect in 2024”入手,盘一盘这条赛道留给其他玩家哪些空间。
用好巨头“歼灭战”窗口期
OpenAI推出Sora不让人意外,让人意外的是Sora之强大难以想象。
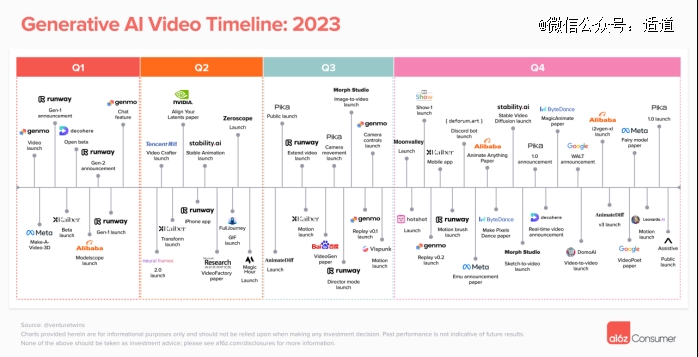
细数2023年AI视频赛道,有两条非常清晰的逻辑。
一是AI生成视频发展之迅猛。2023年初还出现公开的文生视频模型。仅仅12个月后,就有Runway、Pika、Genmo和Stable Video Diffusion等数十种视频生成产品投入使用。
a16z认为,如此巨大的进展说明我们正处于大规模变革的起步阶段——这与图像生成技术的发展存在相似之处。文本—视频模型正在不断演化进步,而图像—视频和视频—视频等分支也在蓬勃发展。
二是巨头入场只是时间问题。2024年注定是多模态AI爆发之年。然而,细数2023年21个公开AI视频模型,大多数来自初创公司。
表面上,Google、Meta等科技巨头如湖水般平静,但水面之下暗流涌动。巨头们没有停止发表视频生成的相关论文;同时,他们还在不声明模型发布时间的前提下对外发布演示版本的视频,比如OpenAI发布Sora。
明明演示作品已经成熟,为何巨头们不着急发布呢?a16z认为,出于法律、安全以及版权等方面的考虑,巨头很难将科研成果转化成产品,因此需要推迟产品发布,这就让新玩家获得了先发优势。
适道认为,最关键因素是“网络效应”并不重要——首发玩家不是赢家,技术*才是赢家。有了能生成60s视频的Sora,你还会执着于生成4s视频的Pika吗?
但这不代表初创公司彻底没戏。因为在该规律下,巨头们的动作不会太快,初创公司需要抓住“窗口期”,尽量快速发布产品,圈一波新用户,赚一波快钱,尤其是在国内市场。
补充前阿里技术副总裁、目前正在从事AI架构创业的贾扬清的观点:1.对标OpenAI的公司有一波被其他大厂fomo收购的机会。2. 从算法小厂的角度,要不就算法上媲美OpenAI,要不就垂直领域深耕应用,要不就选择开源。(创业邦)
“学霸”Sora强在哪里?
目前,绝大部分AI视频产品还未解决核心难题:可控性、时间连贯性、时长。
可控性:用文本“描述”控制画面中人物的运动轨迹。
当然,一些公司可以为用户提供视频生成前的可控性。例如,Runway的Motion Brush让用户高亮图像的特定区域,并决定它们的动作。
时间连贯性:人物、物体、背景在不同帧之间保持一致,不发生扭曲。
时长:能够制作超过几秒的视频?
视频的时长和时间连贯性息息相关。许多产品都限制视频时长,因为在时长超过几秒后就无法保证任何形式的一致性。如果你看到一个较长的视频,很可能是由很多简短片段构成,而且往往需要输入几十甚至上百条指令。
而Sora的强大在于突破了以上难题。
1、时间连贯性——前景人来人往,但主体始终保持一致

2、时长——轻轻松松生成60s
3、可控性——画家的手部动作非常逼真

不仅如此,Sora还能更好地理解物理世界。养猫的人应该明白这个视频的含金量,居然模拟出了猫咪“踩奶”!
Sora能够实现如此突破,在于OpenAI走上了一条与众不同的道路。
假设Sora是一个足不出户的小朋友,他理解外部世界的方式是观看五花八门的视频和图片。
但Sora小朋友只能看懂简单的信息,OpenAI就为其量身打造了一套启蒙学习课程——通过“视频压缩网络”技术,将所有“复杂”的视频和图片压缩成一个更低维度的表示形式,转换成Sora更容易理解的“儿童”格式。
举个不那么恰当的例子。“视频压缩网络”技术就是将一部成人能看懂的电影内核转换为一集Sora更容易理解的“小猪佩奇”。
在理解“学习信息”阶段,Sora进一步将压缩后的信息数据分解为一块块“小拼图”——“时空补丁”(Spacetime Patches)。
一方面,这些“小拼图”是视觉内容的基本构建块,无论原始视频风格如何,Sora都可以将它们处理成一致的格式,就像每一张照片都能分解为包含独特景观、颜色和纹理的“小拼图”;另一方面,因为这些“拼图”足够小,且包含时空信息,Sora能够更细致地处理视频的每一个小片段,并考虑和预测时空变化。
在生成“学习成果”阶段,Sora要根据文本提示生成视频内容。这个过程依赖于Sora的大脑——扩散变换器模型(Diffusion Transformer Model)。
通过预先训练好的转换器(Transformer),Sora能够识别每块“小拼图”的内容,并根据文本提示快速找到自己学习过的“小拼图”,把它们拼在一起,生成与文本匹配的视频内容。
通过扩散模型(Diffusion Models),Sora可以消除不必要的“噪音”,将混乱的视频信息变得逐步清晰。例如,涂鸦本上有很多无意义的线条,Sora通过文本指令,将这些无意义的线条优化为一幅带有明确主题的图画。
而此前的AI视频模型大多是通过循环网络、生成对抗网络、自回归Transformer和扩散模型等技术对视频数据建模。
结果就是“学霸”Sora明白了物理世界动态变化的原理,实现一通百通。而其他选手在学习每一道题解法后,只会照葫芦画瓢,被“吊打”也是在情理之中。
未来AI视频产品如何发展?
根据a16z的展望,AI视频产品还存在一些待解决空间。
首先,高质量训练数据从何而来?
和其他内容模态相比,视频模型的训练难度更大,主要是没有那么多高质量、标签化的训练数据。语言模型通常在公共数据集(如 Common Crawl)上进行训练,而图像模型则在标签化数据集(文本-图像对)(如 LAION 和 ImageNet)上进行训练。
视频数据则较难获得。虽然 YouTube 和 TikTok 等平台不乏可公开观看的视频,但这些视频都没有标签,而且可能不够多样化(例如猫咪视频和网红道歉等内容在数据集中比例可能过高)。
基于此,a16z认为视频数据的“圣杯”可能来自工作室或制作公司,它们拥有从多个角度拍摄的长视频,并附有脚本和说明。不过,他们是否愿意将这些数据授权用于训练,目前还不得而知。
适道认为,除了科技巨头,长期来看,以国外Netflix、Disney;国内“爱优腾”为代表的行业大佬也不容忽视。这些公司积攒了数十亿条会员评价,熟知观众的习惯和需求,拥有数据壁垒和应用场景。去年1月,Netflix就发布了一支AI动画短片《犬与少年(Dog and Boy)》。其中动画场景的绘制工作由AI完成。对标到国内,AI视频赛道大概率依然是互联网大厂的天下。
其次,用例如何在平台/模型间细分?
a16z认为,一种模型不能“胜任”所有用例。例如,Midjourney、Ideogram和DALL-E都具有独特的风格,擅长生成不同类型的图像。预计视频模型也会有类似的动态变化。围绕这些模式开发的产品可能会在工作流程方面进一步分化,并服务于不同的终端市场。例如,动画人物头像(HeyGen)、视觉*(Wonder Dynamics)和视频到视频( DomoAI)。
适道认为,这些问题最终都会被Sora一举解决。但对于国内玩家而言,或许也是一个“中间商赚差价”的机会。
第三,谁将支配工作流程?
目前大多数产品只专注于一种类型的内容,且功能有限。我们经常可以看到这样的视频:先由 Midjourney 做图,再放进Pika制作动画,接着在Topaz上放大。然后,创作者将视频导入 Capcut 或 Kapwing 等编辑平台,并添加配乐和画外音(由Suno和ElevenLabs或其他产品生成)。
这个过程显然不够“智能”,对于用户而言,非常希望出现“一键生成”式平台。
据a16z展望,一些新兴的生成产品将增加更多的工作流程功能,并扩展到其他类型的内容生成——可以通过训练自己的模型、利用开源模型或与其他厂商合作来实现。
其一,视频生成平台会开始添加一些功能。例如,Pika允许用户在其网站上对视频进行放大处理。此外,目前Sora也可以创建*循环视频、动画静态图像、向前或向后扩展视频等等,具备了视频编辑的能力。但编辑效果具体如何,我们还要等开放后的测试。
其二,AI原生编辑平台已经出现,能够让用户 “插入”不同模型,并将这些内容拼凑在一起。
可以预见的是,未来大批内容制作者将同时采用AI和人工生成内容。因此,能够“丝滑”编辑这两类内容的产品将大受欢迎。这或许是玩家们的最新机会。










