

1946年2月24日,美国宾夕法尼亚大学研发出了世界上*台通用计算机ENIAC,美国国防部如获至宝,靠着这个18000个电子管、占地170平方米、重达30吨、耗电功率达150千瓦的庞然大物,每秒钟可以进行足足5000次运算,精准地计算出弹道轨迹。
当时的计算机科学家们,怎么都不会想到,在数十年后,一台小小的手机,其中所容纳的A16芯片,每秒运算速度是16万亿次。
科技的迸发往往会催生出人类基因内那种原始的震撼感,震撼,是一种对巨大可怖的超能力的费解,人类*次看到火焰、*次听到雷声、陨石摧毁山巅、见证蒸汽列车驶过大清帝国,以及现如今,看到ChatGPT,以一种极其巨大又微乎其微的悖论形态垄断了互联网大部分的关注。
ChatGPT的巨大,和世界上*台计算机比有过之而无不及。
ChatGPT的诞生基于8000亿个单词的语料库(45TB),包含了1750亿个参数。而ChatGPT商业化后,要维持运转,一共需要至少3万个以上高性能GPU,搭配数千台服务器,以及相应用来容纳的500个标准机柜。这样一共估算,需要Open AI花上8亿美元。
萨摩亚作为一个美丽的太平洋岛国,其2022年的GDP,就是8.32亿美元。
等于说萨摩亚的21.88万岛民,捕鱼、种地、当导游、卖手工艺品、给游客跳舞表演才艺,做上整整一年,恰好等于一个ChatGPT的费用。
ChatGPT同样十分渺小,世界各地上只要能接入GPT官网的用户,用一台很普通的电脑,都可以和ChatGPT进行交流,并且获得较为精准的答案。目前,一共有超过一亿的ChatGPT用户,每个月有18亿的访问量。
就像冯·诺依曼所说的:“我们曾经熟悉的一切,都开始变得陌生。”
AI几年前原本无人问津的山芋,在加温之下,逐渐炙手可热,为了争夺AI的金杯,全中国的大厂,群起而攻之。
1、火种涌现
“人工智能是我们人类正在从事的最为深刻的研究方向之一,甚至要比火与电还更加深刻。”——桑德尔·皮猜(Sundar Pichai), 2020
ChatGPT并不是一个*无瑕的AI,但在社会层面上,ChatGPT的革命意义在于,它完成了一轮全球级别的AI普及,并且告诉从业人员,做AI是有前途的。
视角回到中国,其实在前几年,AI从业者特别苦。
前几年的至暗时刻里,从业者一出去拉投资,就会说这么一句话:“比尔盖茨曾说过:‘语言理解是人工智能皇冠上的明珠’”
但其实,这句名言是澜舟科技创始人周明替比尔盖兹编的。
在2022年之前,AI的投资氛围一直处于冰点,没人投资、没有科研经费、没有科研人员;周明为了拉拢投资,就特意在饭桌上编了这么一句话,但觉得自己说出来没什么可信度,于是他加了个“比尔盖茨说过”
“在过去几年,AI投资基本为0,在大家觉得满眼雾霾的时候,突然ChatGPT出来了,给人带来了光”周明在ChatGPT及大模型专题研讨会上,感慨了起来。
似乎在在2022年11月之后,AI的行业格局似乎一瞬间都变了,各大高校的大模型人才遭到疯抢。背靠清华的大模型创业公司智谱AI,因为人才丰富,所以在几轮哄抢之后,估值已经超过了30亿元。
而引起各大科技公司疯狂招兵买马的本质原因,就是ChatGPT,并没那么强大,就像计算机科学家杨立昆(Yann LeCun)所说,ChatGPT并不特别,也没有什么革命意义的功能。
如果说中国是一个牌客,那么在光刻机、国产系统、人工智能,那么坐上AI这张牌桌,超越美国,并非难于登天。
AI领域,是中国和美国差距最小的高科技领域之一。
就像王小川所说:“用时间衡量的话,OpenAI比我们应该*三年时间是有的。之前我们说追上GPT-3.5,可能一年时间是有机会的。但人家已经到GPT4了,还有5在训练当中,所以我觉得有三年。”
而只要在AI领域追上美国,就可以在未来十年内吃尽国产AI的红利。
因为在AI领域里,不论是政客,还是商人,都想得十分清楚,这就是一个赢家通吃的战场,有点类似于绝地求生,不管你装备多好,只要没活到最后,你的努力就是0。
Open AI的GPT-4一个月收费20美元,用户们想付钱都得排队,谷歌的Bard虽然是免费的,但就是因为性能没GPT-4那么强劲,访问者廖廖。
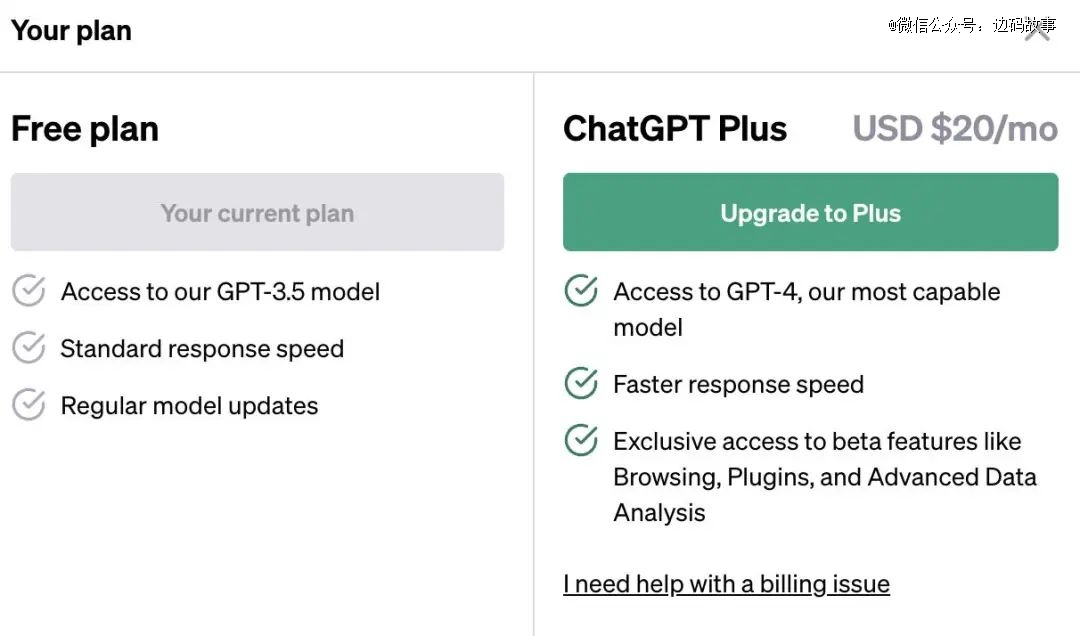
而中国这个市场,有足足14亿中文用户,趁着OpenAI还没有做足准备攻略大陆的时候,国内巨头们必须先发制人,甚至先消灭自己人。
首先是国家支持,科技部等六部门印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》
有了定心丸之后,伴随而来的,是国内高管们的纷纷入局。
2、群雄逐鹿
“要参与规则的制定,就要先上牌桌,才能拥有话语权,才有全球竞赛的入场券”,李彦宏在5月底举行的中关村论坛上,说了这么一段话。而百度确实算是较早入局大模型的玩家之一。
2023年3月中旬,文心一言开放用户申请体验,一经推出就引起了全社会的关注,但伴随而来的也是巨大的争议。有人认为文心一言的出现,是中国大模型发展的重要一步;亦有人觉得,文心一言很多功能尚不成熟,仍有发展空间。
李彦宏可能是最快的,但他*不是最为狂热的,因为AI而睡不着的老板比比皆是。
搜狗前CEO王小川直接说道:“这两个月都睡不着觉,太兴奋了”他自掏腰包,对外宣称自己投了5000万美金搞大模型,命名为“百川智能”。
然后也有人说,字节跳动的张一鸣最近在看OpenAI的一系列论文,常常读到深夜。
甚至3月23日的TikTok美国听证会下,也没看到张一鸣的身影,有人说张一鸣没看直播,而是在挖OpenAI的华人工程师,开出的价码是“一亿现金+股权”。
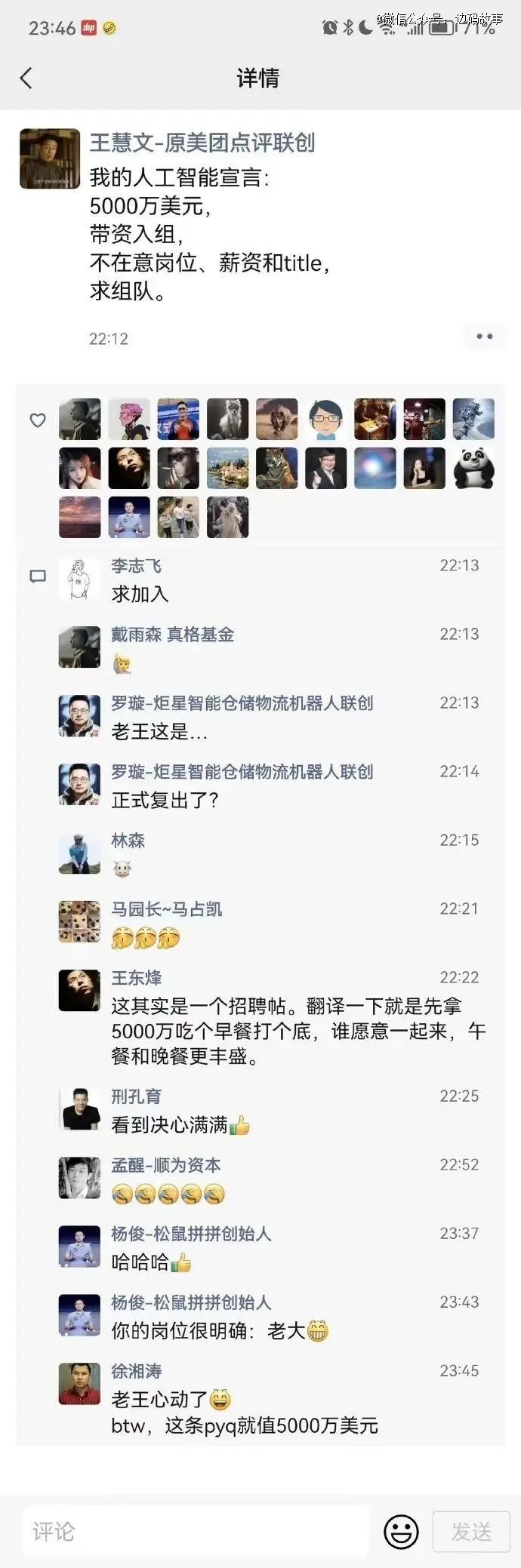
无独有偶,在今年2月,美团联合创始人王慧文也在朋友圈发表宣言,要出资5000万设立北京光年之外科技有限公司,扬言要打造出中国的Open AI。
马化腾性格较为内敛,不喜欢抛头露面,更喜欢稳扎稳打,马化腾曾在股东大会说过:“这是几百年不遇的、类似发明电的工业革命一样的机遇,腾讯并不急于把半成品拿出来展示。”
话虽如此,腾讯的AI投资动作也十分频繁。
腾讯除了自研“混元大模型”外,6月1日,根据路透社报道,国内通用大模型初创企业MiniMax完成了超2.5亿美元新一轮融资,其中,与有腾讯有关联的实体参与,参投资金或为4000万美元。
之所以大家如此狂热,因为国内AI大模型的赢家只能有一个,要么*,要么无人问津。
3、战争*
2005年的时候,由尼古拉斯·凯奇主演的《战争*》在全球上映,就有这么一段故事,苏联解体之后,大量的军火流散在前苏联各成员国的军火库中,凯奇饰演的尤里,就作为一个军火商到处购买这些军火,然后卖给世界各地的军阀。
电影中,凯奇说了这么一句话:“你知道谁将继承地球吗?军火商,因为其他人都在忙于自相残杀。”
这句话放在如今中国AI领域的“百模大战”,也十分精准。
“你知道现在谁是AI竞赛的赢家吗?英伟达,因为其他人都在忙于卷模型”
训练大模型,是成本极其高昂的一个行为,对小公司来说,无异于用全部的存款买2元的大乐透,然后等待用户去*。
有多烧钱呢?据华为大模型负责人田奇称,大模型开发和训练一次,需要1200万美元。而这1200万美元里,有720万花费在了电力上。
所以电力这一块,做高压直流(HVDC)的供应商就成买金铲子的了,因为供电效率能提升到94%~95%,HVDC已经在BAT等大厂投入使用。
训练大模型的另一个大头,是显卡。
penAI在训练GPT-3时使用了1万块V100,训练GP3.5时,至少用了1万张英伟达A100高性能显卡。
1万张A100这种*显卡,一张至少10000美元,1个亿美元,只能算是踏入大模型领域的敲门砖。
英伟达生产多少A100显卡,各家公司就抢多少张A100显卡。但由于美国政府从中阻拦,中国的高科技公司想要购买A100之类的高端GPU,得拿到美国政府的出口许可。
但英伟达的CEO黄仁勋怎会放下中国这块巨大的市场,于是英伟达又炮制出了A800显卡。
A800显卡可以看作是A100的缩水版,规格基本相同,*的区别在于连接速率上,A100的连接速率是600GB/s,A800的连接速率被限制在400GB/s。
恰好规避了美国出口管制规定中“芯片数据传输速率不能超过600GB/s”的要求,成了一个折中之道。
黄仁勋自然不是向中国做慈善,但出于经商头脑,他却间接为中国的AI发展提供了大量高性能铲子。
据《金融时报》8月10日报道,今年英伟达将向百度、字节跳动、腾讯和阿里巴巴交付价值10亿美元的A800处理器,2024年还将交付价值40亿美元的GPU。
趁着诸侯争霸,黄仁勋卖显卡赚的盆满钵满,在各种讲座和会议上,你很难看到黄仁勋不笑的情景,因为截止9月,英伟达今年股价已经涨了超过200%。
但因为AMD在人工智能领域相较性能没那么强劲,AMD的CEO苏姿丰就没那么爱笑了,今年的涨幅,仅仅有约65%。
毕竟外行看来,AI是个体面的行业,但内行看来,只有残酷,四处可见的赢家通吃和大鱼吃小鱼的原始竞争法则,在这里展现的淋漓尽致。
想要打败强者,只能比强者更强,然后强者恒强。
4、四方之志
有人可能会问,为啥要这么烧钱去做全链路自研呢?直接把ChatGPT作为大模型底座,然后优化优化,推出各种应用端不就行了么?
其实,大部分人作为消费者,对AI付费的认识,可以类比于电费、水费、网费、燃气费。我们平时在家里打开电灯,烧开水喝,然后用手机刷短视频、用电脑打游戏,最后晚上再在厨房给自己烧一顿饭,这些水电站之类的基础设施所提供的能源都在不断消耗,而消费者只需要付费就行了,并不需要知道电和网络是怎么来的。
通用大模型所追求的*奥义也是如此。让AI变得跟水电燃气一样成为生活的基础。
譬如说,一个公司老板想要在腾讯会议或者之类的智能会议软件开会,他于是打开了AI小助手,告诉助手:“我需要你等等帮我做会议纪要,并且总结重点。”随之,在2个小时的会议之后,AI助手很*地解决了这一个问题,老板也并不知道AI小助手是怎么和腾讯的混元大模型底座互通的。
只要让消费者简单用上AI,并解决生活中的一部分具体问题,它就会彻底离不开AI。
在90年代,车马很慢、书信很远,想要远程交友还有“书信笔友”这么一个玩意儿,你跟90年代的人说你们没网络怎么活?他们会反问这网络有什么用呢?
同样的,假设一个来自于2040年的未来人来到2023年,他会问老百姓们,你们生活没有AI咋活啊?老百姓们可能会噗嗤一笑,AI除了帮我点歌、给我脑筋急转弯、范范地回答我的问题,还能干嘛?
这个市场,正因为有巨大的空白,所以先行者更不能拱手相让。
一旦ChatGPT变得足够强大,让所有的用户都只用ChatGPT,那么他们就离开不ChatGPT了。如果消费者建立起问答习惯,则所有的数据都回进入ChatGPT的飞轮,不断地运转、庞大,直到大而不倒,那么中国的高科技产业,就将失去未来10年的机遇。就业岗位流失、购买力流失、想象力流失……不论于公于私,这正是政府和公司为啥一定要在名为AI的绞肉机里浴血奋战、不断奔跑的原因。
因为,AI就是未来的“新能源”。
就像周润发说的:“我要争一口气,不是证明我有多了不起,我是要告诉人家我失去的东西我一定要拿回来!我发誓以后再也不会让人用枪指着我的头”
除了有钱可烧、政府支持之外,大厂们在训练数据上也有着巨大优势。
百度有百科类的资料,阿里巴巴更聚焦于电商,字节有抖音和今日头条两大国民应用。而腾讯更是有海量应用和微信公号等内容生态。让他们更有底气,进可做通用大模型底座,退可做更加垂直的行业大模型。
以腾讯混元大模型为例,这个全链路自研技术下的通用大模型,靠着2万亿Token的预训练语料,在中文的理科、高考题和数学等子项超过了GPT3.5。而且更可怕的是,它还在以天为单位加速迭代。
因为对大厂来说,业界开源大模型已经无法满足高并发业务的要求,如果已经训练好的模型有违法错误信息,从使用方角度来说很难更改,会严重影响产品体验以及技术迭代。
等于说是家里电器越来越多,光靠手摇发电机不仅效率低,还有可能把手摇废了。
所以,退一步来说,不论是国家,还是公司,我们有且仅有“全链路自研”这一条路可走。这不仅是为利益而战,也是为未来而战。AI是人类的未来,但是要手握未来,没有神仙皇帝,只有我们自己。
像是论语里说的:“人生则有四方之志,岂鹿豕也哉,而常聚乎?”
人生要有远大志向,不可像猪狗一样,等待喂食。
AI的时代里,就算是烧干筹码,我们也不能做*个退出牌桌的。









