

2022年11月30日,ChatGPT发布,全世界对这一全新AI技术充满好奇的人,开始闯入ChatGPT世界。
不过,在使用ChatGPT时,*步要先交出数据使用权。
即允许ChatGPT将我们与它对话过程中产生的数据,用于它自己今后的模型优化过程中。
或许你会觉得这没什么所谓,毕竟在互联网世界里,我们已经习惯了交出数据,换取服务。
然而,相较于之前基于关键词匹配的互联网搜索技术,基于语料库生成式的大模型技术天然拥有更高的“智慧”,这当然也包括在构建用户画像上。
何积丰院士最近就用这样一个例子解释了大模型可能出现的隐私安全问题:
在大模型收集到一个人足够多的个人数据后,当一位黑客提示大模型为这个人作出用户画像时,它甚至可以写出一本小说,详细地描绘出这个人所有的静态和动态信息。
基于大模型的黑客技术,细思极恐。
实际上,这并不是玩笑,在一些西方投资机构中,不少人已经开始通过这类技术,分析初创公司的创始团队,以评估相应的项目是否值得投资。
正是有了以上种种神乎其神的超能力,我们更应该关注由之带来的两个问题:
1、大模型究竟为我们带来了什么?
2、大模型对产业有怎样的意义?
01 AI的致命缺陷
2023年9月7日,美国《时代》周刊首次发布了全球百大AI人物(TIME100 AI),这将人工智能和大模型在全球关注度再次推向高潮。
而早在今年1月,美国另一本颇具影响力的商业杂志《财富》,更是旗帜鲜明地指出,大模型是人工智能的iPhone时刻。
毫无疑问,大模型的出现,让人工智能技术在2023年迎来拐点。
那么,大模型究竟为AI带来了哪些关键改变?
这里我们需要引入一个作为比较对象的参照物,知识图谱。
知识图谱是过去十几年构建人工智能推理能力、认知能力的基础,也是传统人工智能技术的重要范式。
在国内,复旦大学肖仰华教授是最早从事知识图谱研究的人工智能专家之一,他指出:
知识图谱是一种符号化的专业知识表达,大模型则是一种参数化的通用知识容器。
二者差别在哪里?
差别在于,后者可以提供对于「常识」的理解能力。
「常识」能力是人类定义的,也是人类擅长的一种经验知识,以往的人工智能并不擅长处理「常识」问题,他们遇到「常识」问题,往往会变“笨”。
例如,当你问出如下问题:
如果你在炉子里放入木头,然后再把引火物扔到炉子里,一般来说,你是在做什么?
答案显然是你要在炉子里点火,现在的ChatGPT已经能够很好地给出答案,甚至给出详细的解释。
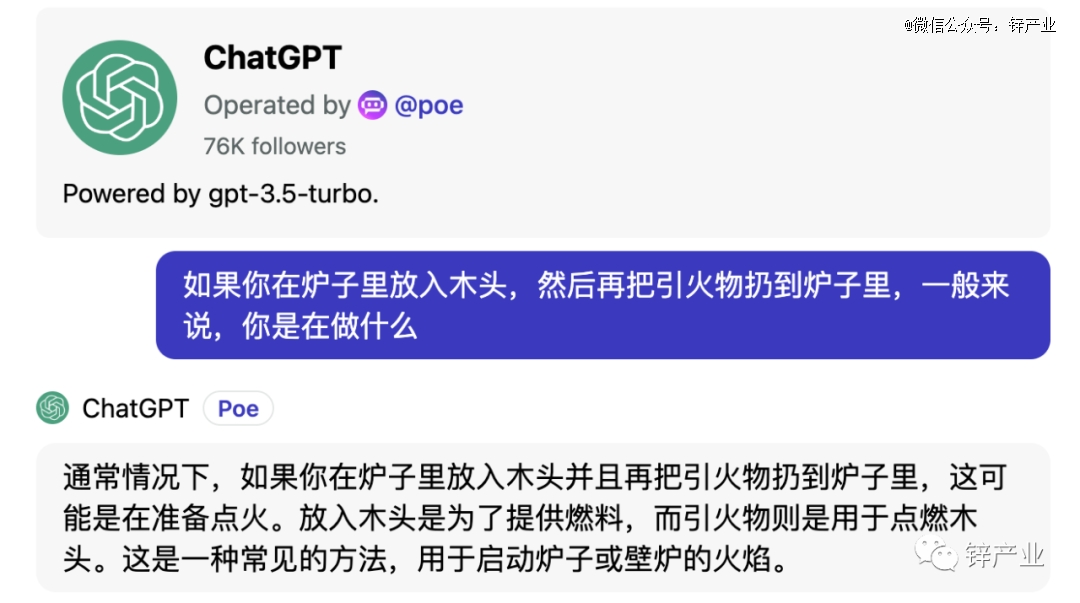
然而,就在三年前,纽约大学心理学教授Gary Marcus(曾是Uber人工智能实验室负责人)也曾向当时还很不成熟的GPT-2问过同样的问题,GPT-2给出的答案是:呕吐。
所以,在大模型出现之前,人工智能领域普遍流传着这样一个似玩笑又非玩笑的尴尬自嘲:
再聪明的AI,遇到「常识」问题,都会变得愚蠢不堪。
正如机器人的*形态是拥有双手、双脚,可以在人类定义的世界里执行任务的人形机器人一样,需要在人类世界里运转的人工智能系统,同样需要有仿人的大脑。
在过往十几年,甚至几十年里,人工智能科学家都在思考如何模仿人类的神经系统,虽然因此在CNN、RNN等神经网络上取得了不少突破,但却长期困于「常识」的漩涡。
现在的大模型其实做了另外一件事儿,另外一件模仿人类成长过程知识体系形成过程的事儿:
通过大量数据和参数,花大力气让人工智能拥有「基础认知」,而非「专业知识」。
这有点像是让人工智能去经历一个九年义务教育的折磨。
02 突破认知瓶颈
人类对自己创造的社会文明的学习,是从痛苦的数理化公式开始。
虽然大部分人类最终没有成为科学家,也没有从事基础科学研究,但这些基础知识让我们在之后的生活中拥有了「常识」,这为我们从事更具象化的工作打下了基础。
所以,九年义务教育或许没有肉眼可见的实际价值,但它为我们建立了对世界运转规律的基本认知。
肖仰华教授在行业调研过程中曾遇到过另一个更具体的案例:
医院里,医生在为病人诊断病情时,80%的时间是在排除健康因素,只有20%的情况是需要医生干预并给出诊断方案的。
也就是说,一位医生要想做好自己的工作,首先要知道人类身体在健康情况下是一个怎样的运转状态,而不仅仅要知道生病时是什么样。
要理解疾病,首先要理解什么是健康。
这反映出来的其实是,「常识」是认知的前提,是人类世界的底层逻辑。
在大模型出现之前,人工智能专家要想为某个行业研发智能化解决方案,首先要把这个行业中所有数据收集起来,从而构建一个行业数据驱动的智能化解决方案。
此前只会下围棋,但却轰动了全世界的AlphaGo,就是通过这种模式训练而来。
不过,那时,有人在尝试走另一条路。
2015年年底,OpenAI创始人奥特曼带着一群人工智能领域最聪明的人,用大量资源和万亿级参数,开始训练人工智能看起来不怎么厉害的「常识」理解能力。
他们花了7年时间,耗费巨资、巨量时间,为人工智能补了一个九年义务教育。
这时,AI有了理解传统人工智能模型学习的“大学课程”背后的“为什么”的基础。
奥特曼和他的团队——世界上最聪明的一群人,花了大量的时间和精力做了很多不讨巧、其他人不愿意做的事儿。
这才有了大模型,有了2022年年底发布的ChatGPT,有了人工智能突破认知瓶颈的2023。
如非大模型,人工智能很可能会在2023年在资本的失望情绪下,再次进入低潮。
03 补修“专业课”
大模型来了,通用人工智能来了,AI和人一样有了认知世界的基础知识了,是不是就能*解决所有行业问题了?
其实,不然。
大模型让人工智能拥有了「常识」的同时,也带来了一个与生俱来的严重问题是:“幻觉”现象,也就是我们在使用ChatGPT这类大模型过程中,它总是会“胡说八道”。
大模型之所以被称为生成式AI,是因为它基于训练数据,有了一定的创造性,这样的创造性,在具体某一个垂直行业中,表现为对先验知识缺乏足够的“忠诚度”。
如果在医疗、工业等行业领域中,大模型遇到了一个它没有学习到的知识,或者是一个开放性的问题,它发挥了自己的创造力,由此带来的后果将难以想象。
在垂直行业场景中,引入人工智能技术,首先需要它是一个可控、可编辑、可解释、可防护的模型,这是基于知识图谱的传统人工智能模型的特性,也是为什么这类模型会先发展起来的一个主要原因。
但是如果不懂乐理,终究难成大师级音乐家。
当传统人工智能模型最终遇到瓶颈,人们发现大模型才是正道时,如何让“创造力有余,专业力不足”的大模型拥有进入产业时所必须的,这些它本不擅长的能力,就成了如今的关键。
肖仰华认为,通用大模型向行业大模型的适配、优化,今天才刚刚开始,无论是从数据、知识、训练,还是模型架构、评估体系、生态建设上,我们都还有很长的路要走。
例如,在长文本的理解能力、长短期记忆能力,甚至金融领域最基本的数学量纲、数量推理上,现在的大模型都还无法很好地做出正确的理解。
不过,我们能看到的是,在大模型发布还不到一年的时间里,各行各业都已经迫不及待地尝试将大模型引入各自领域中。
具体在进入垂直领域时,大模型往往会将需要执行的任务分解为三个子任务:提示、生成、评估,当下大模型最擅长的,仍然是生成子任务。
因而,学术界和产业界都在为大模型补课,希望可以通过与数据库、知识图谱这些相关技术的协同,提升大模型的专业能力。
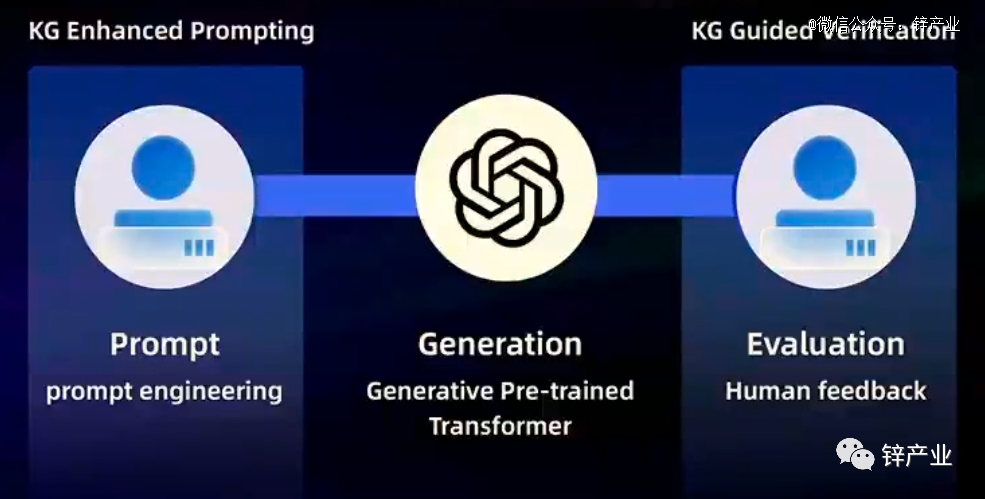
例如,通过知识图谱来做提示和评估,缓解大模型的“幻觉”问题。
大模型欠下的专业课,都需要再修一遍,这其中,与专业能力更强的知识图谱这类技术进行协同应用,不失为一条不错的捷径。
04 像云计算一样颠覆产业
在ChatGPT问世之前,没有多少人相信大模型,就像云计算在国内问世时,不少互联网大佬都曾质疑过云计算一样。
在ChatGPT问世后,大模型成了人工智能技术的拐点。
甚至在ChatGPT问世不到一年的时间里,各行各业都展开了对大模型在垂直行业里的应用探索,商业模式更清晰的行业大模型也成了一大竞争焦点。
来自全球知名咨询机构麦肯锡的预测数据显示,生成式AI将为全球带来至少9万亿美元的经济价值增量。
在这9万亿美元的经济增量中,排在前三的产业分别是高科技、零售、金融,预计产生的经济增量分别为2000亿美元-4600亿美元之间。
即便是在农业这样被视为最传统的产业中,也将带来至少400亿美元的经济增量。
过去三十年里,全球GDP增长主引擎已经由就业人口转向生产力,而在过去十年里,生产力增速不断放缓导致了全球经济减速。
谁来挽救全球经济?
麦肯锡中国区主席倪以理认为,生成式AI是其中关键。
他指出,在过去很长一段时间里,自动化始终无法替代的诸如互动、决策类工作,生成式AI带来了新的替代可能。
此外,作为擅长用数据表达趋势的咨询机构,麦肯锡还给出了生成式AI对自动化的加速量化效果——当前半数工作被自动化取代的时间,相较之前预测提前了10年。
这意味着,虽然大模型才刚开始从通用大模型转向专用大模型,但大模型将会像云计算一样颠覆产业。
这种颠覆,或许比人们想象的要来得更快。





