

当新赛道挤满了摩拳擦掌的选手,场边的裁判员也应运而生。
5月,国家科技部下属的中国科学技术信息研究所,发布了《中国人工智能大模型地图研究报告》。内容显示,截至5月28日,国内10亿级参数规模以上基础大模型至少已发布79个。
每一个亮相时,都少不了“行业*”“技术革新”诸如此类的标签。不免引来质疑:如何直观地评判哪一款大模型在技术和性能上更为*?那些宣称“*”的评估标准与数据来源又是怎样的?
一把衡量不同模型效能基准的“尺子”亟待打造。
前不久,国际咨询公司IDC发布《AI大模型技术能力评估报告2023》,调研了9家中国市场主流大模型技术厂商。其他不少研究机构和团队也投入资源,发布了对应的评价标准和深度报告。这背后所显露的现象和趋势,更值得深层次的探讨。
01 评测基准百家争鸣
ChatGPT 带火了大模型应用的相关研究,评测基准亦成为关注焦点所在。
日前,微软亚洲研究院公开了介绍大模型评测领域的综述文章《A Survey on Evaluation of Large Language Models》。根据不完全统计(见下图),大模型评测方面文章的发表呈上升趋势,越来越多的研究着眼于设计更科学、更好度量、更准确的评测方式来对大模型的能力进行更深入的了解。
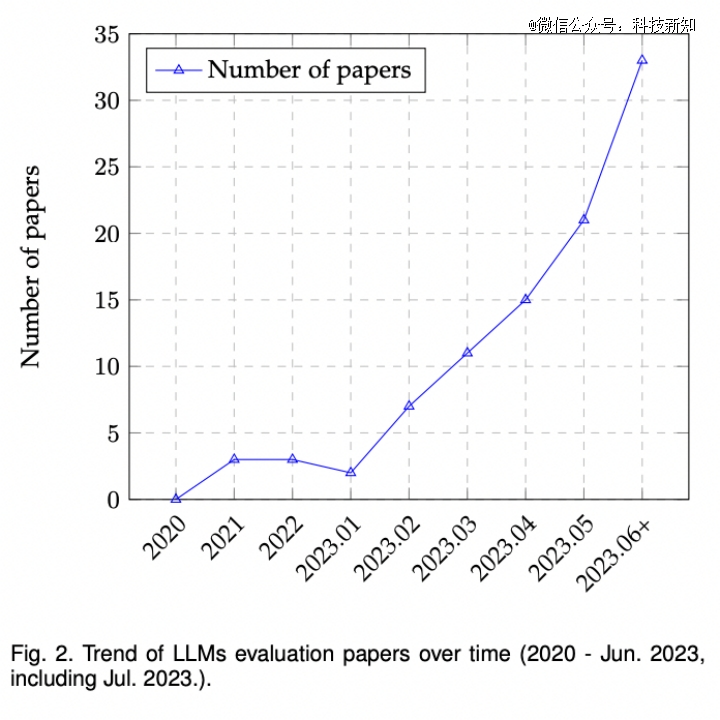
文中一共列出了19个受欢迎的基准测试,每个都侧重于不同的方面和评估标准,为其各自的领域提供了宝贵的贡献。为了更好地总结,研究员将这些基准测试分为两类:通用基准(General benchmarks)和具体基准(Specific benchmarks),其中不乏一些深具盛名的大模型基准。
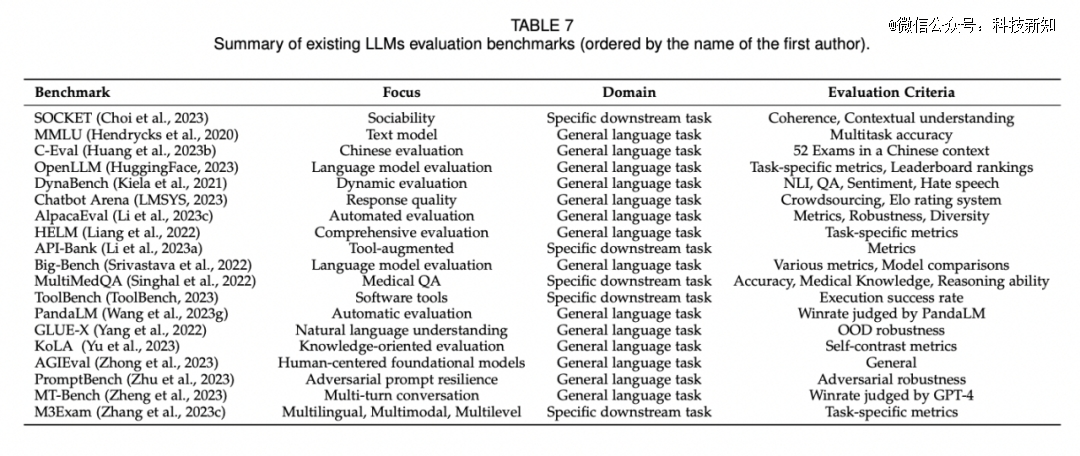
Chatbot Arena,就被行业人士普遍认为是*公平性与广泛接受度的平台。其背后的推手——LMSYS Org,是一个开放的研究组织,由加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学合作创立。
这个创新性的评估标准,为各大AI研究机构与技术爱好者,提供了一个既独特又具有激烈竞争力的场所,专门用于评价和比对不同聊天机器人模型的实际应用效果。用户能够与其中的匿名模型进行实时互动,而后通过在线投票系统表达他们对于某一模型的满意度或喜好。
值得一提的是,该评测方式的设计灵感来源于国际象棋等竞技游戏中盛行的ElO评分系统。通过积累大量的用户投票,它能够更为贴近实际场景地评估各模型的综合表现。
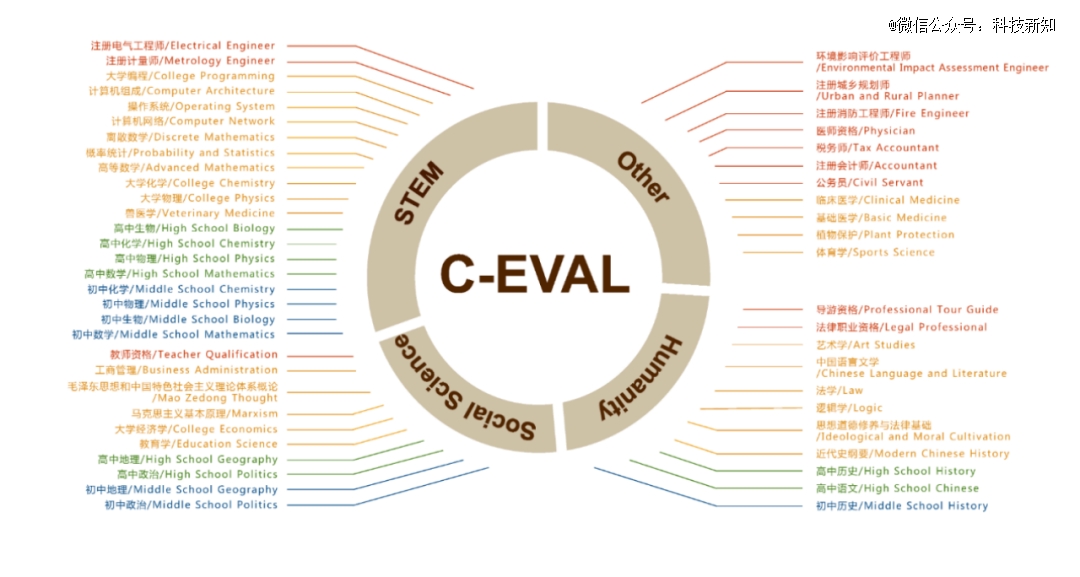
微软亚洲研究院还在文中提到了通用基准C-Eval,这是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,该项目由上海交通大学、清华大学、爱丁堡大学共同完成。
除了通用任务的基准测试外,还存在一些专为某些下游任务设计的具体基准测试。
譬如,MultiMedQA是一个医学问答基准测试,重点关注医学检查、医学研究和消费者健康问题。该基准由谷歌和DeepMind的科研人员提出,它包括七个与医学问答相关的数据集,其中包括六个现有的数据集和一个新的数据集。测试目标是评估大语言模型在临床知识和问答能力方面的性能。
还有一些中文评测基准被微软研究院所遗漏。例如SuperCLUE,作为针对中文可用的通用大模型的一个测评基准,由来自中文语言理解测评基准开源社区CLUE的成员发起。
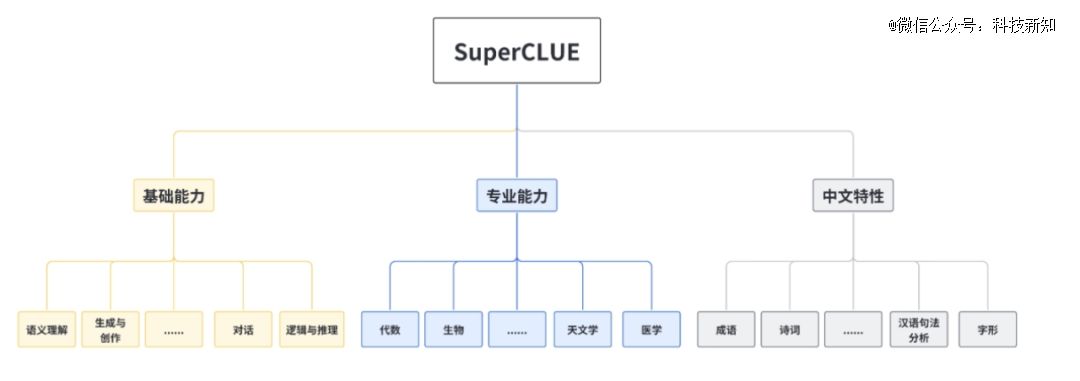
为了着眼于综合评价大模型的能力,使其能全面地测试大模型的效果,又能考察模型在中文上特有任务的理解和积累,SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。
实际上,这些维度只是冰山一角。在评测 LLMs 的性能时,选择合适的任务和领域对于展示大型语言模型的表现、优势和劣势至关重要。微软亚洲研究院将现有的任务划分为了7个不同的类别:
自然语言处理:包括自然语言理解、推理、自然语言生成和多语言任务;
鲁棒性、伦理、偏见和真实性;
医学应用:包括医学问答、医学考试、医学教育和医学助手;
社会科学;
自然科学与工程:包括数学、通用科学和工程;
代理应用:将 LLMs 作为代理使用;
其他应用。
纵观当前AI领域的发展趋势,大模型的评测基准测试不再仅仅是一个单一的技术环节,而是已经逐步成为整个上下游产业链中的重要配套。
02 正确地使用“尺子”
存在即合理。
大模型评测基准的诞生和持续优化,之所以呈现出愈演愈烈的势头,无疑与其所能带来的巨大价值和业界的广泛认同是密不可分的。
可以看到,通过深入的大模型评测基准分析,能够更为明确和系统地揭示大模型在各种应用场景中的优势与局限性。这种专业的评估不仅为AI领域的研发者提供了清晰的指导,同时也助力用户最终作出更为明智的技术选择。
在复杂的研发过程中,判断技术方案或特定模型的优越性往往是一个挑战。C-Eval数据集和其相关榜单,意义不仅仅是一系列的数字或排名,而是为大模型的研发者提供了一套客观、系统的评估工具。
用C-Eval项目团队的话来说,“我们的最重要目标是辅助模型开发”。
具体来看,研发团队可以与企业紧密合作,将大模型评测基准整合到他们的开发和测试工作流程中。这不仅可以在实际应用环境中验证模型的性能,还能通过双方的深度沟通,找到在测试过程中可能遇到的技术难题和挑战,从而实现更为高效和准确的模型优化。
正是基于这一点,多家头部大模型厂商不仅在模型研发上持续投入,同时也在评测基准的制定与优化上下足了功夫。
譬如科大讯飞通过认知智能全国重点实验室牵头设计了通用认知大模型评测体系,覆盖7大类481个细分任务类型;阿里巴巴达摩院多语言NLP团队发布了*多语言多模态测试基准M3Exam,共涵盖12317道题目,等等。
不过也正如C-Eval项目团队所强调的:对于大模型厂商,单纯地追求榜单的高位排名,并不应成为其主要追求。
当厂商将榜单成绩作为首要目标时,可能会为了追求高分而采用过度拟合榜单的策略,这样就很容易损失模型的广泛适用性。更为关键的是,若仅仅着眼于排名,厂商可能为了短期的成绩而试图寻找捷径,从而违背了真正踏实的科研精神与价值观。
再看终端用户的视角中,大模型测评基准提供了一个全面的、结构化的参考框架,从而充分地辅助用户在众多技术选项中做出更为理性和明智的决策。这种评测不仅降低了技术采纳的风险,也确保了用户能够从所选模型中获得*的投资回报率。
尤其对于那些还未拥有深厚大模型研发实力的企业来说,深入了解大模型的技术边界,并能够针对自身需求高效地进行技术选型,是至关重要的。
综上,不论是对于背后的研发团队还是产品侧的终端用户,大模型评测基准都承载着不可估量的价值和意义。
03 劣币来袭
吊诡的是,由于在原理核心上并不涉及复杂的技术门槛,导致目前市场上的大模型评测基准的数量,甚至已经超过了大模型本身。这其中自然有许多机构见到了可乘之机,进行各种市场操作,包括混淆视听、误导消费者的行为。
此前就有观点认为,随着AI技术的发展,大模型评测可能会被某些公司或机构用作营销工具,通过发布其模型的高分评测结果来吸引公众的注意力,以期提高产品的市场份额。
目前也有一些突出的现象佐证:在某些特定评测榜单中*的厂商,放到其他不同的榜单评测中,却未能够维持其优势地位。
不能排除存在着客观原因。当前阶段,对于大模型的评估机制和具体评测指标,并没有达到一个行业共识,更遑论出现统一的的评测标准。不同的应用环境和任务标准,就会产生截然不同的评价框架和需求。
此外,大模型评测通常依赖于两大主要方法:自动评测和人工评测。自动评测是基于精确的计算机算法和一系列预定义的指标进行,而人工评测更多强调人类专家的主观见解、经验和质量判定。
遇到大模型生成诗歌或短文这类任务时,人工评测的主观性变得尤为显著。自古“文无*,武无第二”,不同的评审者可能会对同一作品给出不同的评价。
然而,从相关搜索结果中不难发现,大模型评测早已被某些厂商视为一个营销的竞技场。毕竟在一个竞争激烈的市场中,每一个厂商都希望自己的产品能够脱颖而出。
因此有充分的动机去选择那些能够突显自己产品优势的评测指标,而忽略那些可能暴露弱项的指标。这种选择性的展示,即使有机会带来短期的市场优势,但是对于消费者和整个行业来说,必然是有害的。
一时的误导一旦扭曲了市场的竞争格局,可能使得真正有价值的创新被埋没。劣币驱逐良币之下,那些只是为了宣传而进行的“创新”反而会趋之若鹜。
从这个角度出发,大模型评测基准还是应该回归其本质,即为了更好地理解和比较不同模型的性能,为研发者和终端用户提供反馈,而不是为了产品厂商的短期利益。
既然要当裁判员,还是要尽量做到独立、客观、第三方。
参考资料:
微软研究院《A Survey on Evaluation of Large Language Models》
机器之心《13948道题目,涵盖微积分、线代等52个学科,上交清华给中文大模型做了个测试集》










