近日,AI*学术刊物IEEE T-PAMI(全称:IEEE Transactions on Pattern Analysis and Machine Intelligence)将特斯联科技集团首席科学家邵岭博士及其团队的五项科研突破收录其中。此次被收录的内容包括:物体检测与分割、图像恢复与增强、显著对象识别等细分方向的研究突破。IEEE T-PAMI刊发人工智能、计算机视觉、模式识别等多个领域的文章,其2022年影响因子达24.314,被公认为人工智能领域*的*期刊。近一年,特斯联首席科学家邵岭博士共有16篇论文被IEEE T-PAMI录用,位居全球前列。
上述五项研究成果可广泛应用于智慧城市的高效治理、城市服务等诸多领域及业务场景,并将被特斯联新一代智慧城市操作系统TacOS及其他AI算法赋能平台采用。
以下为本次被T-PAMI收录的五项研究成果的核心介绍:
1)基于完整学习的显著目标检测
Salient Object Detection via Integrity Learning
尽管当前的显著对象检测(Salient Object Detection, SOD)工作已经取得了重大进展,但当涉及到检测的显著区域的完整性时,它们仍不够完善。团队在微观和宏观层面上定义完整性的概念。具体来说,在微观层面,模型应突出属于某个显著对象的所有部分。同时,在宏观层面,模型需要发现给定图像中的所有显著对象。为了促进SOD的完整性学习,团队设计了全新的完整性认知网络(integrity cognition network, ICON),它探索了学习强完整性特征的三个重要成分。1)与更关注特征可辨别性的现有模型不同,团队引入了一个多样化的特征聚合(diverse feature aggregation, DFA)组件来聚合具有不同感受野(即卷积核形状和上下文)的特征,并增加特征多样性。这种多样性是挖掘整体显著对象的基础。2)基于DFA特征,团队引入了完整性通道增强(integritychannelenhancement)组件,旨在增强突出整体显著对象的特征通道,并抑制其他干扰对象。3)在提取增强特征后,采用部分-整体验证(part-whole verification)方法来判断部分和整体对象特征是否具有强一致性。这种部分-整体一致性可以进一步提高每个显著对象微观层面的完整性。为验证所设计ICON的有效性,团队在七个颇具挑战的基准数据集上进行了全面的实验。ICON在广泛的指标方面均优于其他方法。而值得注意的是,在六个数据集上,该ICON的平均假负类率(FNR)相较此前的*模型实现了约10%的改进。

宏观及微观层面完整性问题的图示说明。与现有*算法相比,团队的方法可以更好地整体检测显著区域。前两行为图像和标注的标准结果,蓝色区域为EGNet输出结果,黄色区域为MINet输出结果,红色区域为团队方法的输出结果。
完整论文:https://ieeexplore.ieee.org/document/9789317
2)增强的快速图像及视频实例分割
Enhanced Fast Image and Video Instance Segmentation
团队提出了一种用于图像和视频实例分割的快速单阶段方法,称为SipMask,它通过执行多个子区域掩码预测来保留实例空间信息。团队所提出方法中的主要模块是一个轻量级空间保留(spatial preservation)模块,该模块为边界框内的子区域生成一组单独的空间系数,从而能够更好地描绘空间相邻实例。为了更好地将掩模预测与目标检测相关联,团队进一步提出了掩模对齐加权损失(maskalignmentweightingloss)和特征对齐方案。此外,团队明确了两个阻碍单阶段实例分割性能的问题,并引入了两个模块,包括样本选择方案(sampleselectionscheme)和实例细化模块(instancerefinementmodule),以解决这两个问题。团队在图像实例分割数据集MS COCO和视频实例分割数据集YouTube VIS上对方法进行了实验。在MS COCOtest-dev集上,团队所提出的方法实现了*进的性能。在实时能力方面,在相似设置、相当的运行速度下,该方法相较YOLACT高出了3.0%(mask AP)。在YouTube VIS验证集上,团队的方法也取得了可喜的结果。

一些YOLACT(上)和团队所提出SipMask(下)的实例分割结果。YOLACT未能准确描绘相邻实例。为解决这一问题,SipMask引入了一种全新的空间保留(SP)模块,将掩码预测分为多个子区域掩码预测,这可以保留边界框中的空间信息,并达致改善的掩码预测。
完整论文:https://ieeexplore.ieee.org/document/9790321
3)学习丰富的特征用以快速图像复原和增强
Learning Enriched Features for Fast Image Restoration and Enhancement
给定退化的图像,图像复原旨在恢复丢失的高质量图像内容。诸多应用领域均需有效的图像复原,例如计算摄影、监控、自动驾驶汽车和遥感。近年来,图像复原领域已经取得了重大进展,主要由卷积神经网络(convolutional neural networks, CNN)主导。广泛使用的基于CNN的方法通常作用于全分辨率或渐进式低分辨率表征。在全分辨率情况下,空间细节得到保留,但上下文信息不能被精确编码。在渐进式低分辨率情况下,生成的输出在语义上是可靠的,但在空间上不够精确。团队提出了一种全新架构,以通过整个神经网络维持空间上精确的高分辨率表征为整体目标,并从低分辨率表征中获取互补的上下文信息。这一方法的核心是包含几个关键元素的多尺度残差块(multi-scale residual block):(a)用于提取多尺度特征的并行多分辨率卷积流(multi-resolutionconvolutionstreams);(b)跨多分辨率流的信息交换;(c)用于捕捉上下文信息的非局部注意力机制(non-localattentionmechanism);以及(d)基于注意力机制的多尺度特征聚合(multi-scalefeatureaggregation)。团队在六个真实图像基准数据集上进行的大量实验表明,所提出的方法(MIRNet-v2)在多种图像处理任务,包括失焦去模糊(defocusdeblurring)、图像去噪(imagedenoising)、超分辨(super-resolution)和图像增强(imageenhancement)上均达到了行业最高水平。
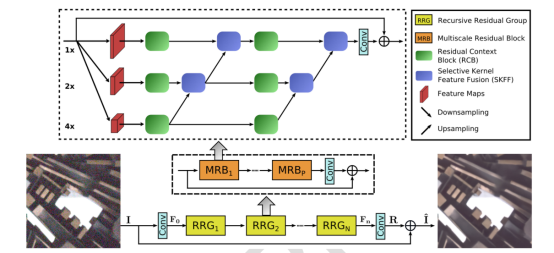
MIRNet-v2框架学习丰富的特征用以快速图像复原和增强。
完整论文:https://ieeexplore.ieee.org/document/9756908
4)杂乱环境下的显著对象
SalientObjects in Clutter
团队发现现有的显著对象检测(salient object detection, SOD)数据集存在严重的设计偏差——不切实际地假设每张图像应至少包含一个清晰、整洁的显著对象。在对现有数据集进行评估时,这种设计偏差导致SOTASOD模型的性能饱和。然而,这些模型在实际应用场景中还达不到令人满意的效果。根据分析结果,团队提出了一个新的高质量数据集并更新了此前的显著性基准。具体来说,团队将新数据集称为杂乱环境下的显著对象(Salient Objects in Clutter, SOC),包括来自数个常见对象类别的显著和非显著对象的图像。除了对象类别注释外,每个显著图像都附有反映常见场景中常见挑战的属性,有助于更深入地了解SOD的问题。此外,基于给定的显著性编码器,例如骨干网络,现有的显著性模型旨在实现从训练图像集到训练ground-truth集的映射。因此,团队认为改进数据集可以产生比只关注解码器设计更高的性能增益。考虑到这一点,团队研究了几种数据集增强策略,包括用以隐式强调显著边界的标签平滑(labelsmoothing)、使显著性模型适应各种场景的随机图像增扩(randomimageaugmentation),以及作为从小数据集中学习的正则化策略的自监督学习(self-supervisedlearning)。大量的结果证明了这些技巧的有效性。

来自新SOC数据集的示例,包括非显著(*行)和显著对象图像(第2到4行)。针对显著对象图像,团队提供了实例水平的真实数据图(不同颜色)、对象属性(Attr)和类别标签。
完整论文:https://ieeexplore.ieee.org/document/9755062
5)使用深度残差网络推进LDDMM框架
Advancing the LDDMM Framework Using Deep Residual Networks
在可变形配准中,几何框架——大形变微分同胚度量映像(large deformation diffeomorphic metric mapping, LDDMM)——激发了诸多用于比较、变形、平均和分析图元及图像的技术。在这项工作中,团队使用深度残差神经网络来求解基于欧拉离散化方案(Eulersdiscretizationscheme)的非平稳常微分方程(non-stationaryODE)。其核心思想是将时间相关的速度场(velocityfields)表示为全连接的ReLU神经网络(buildingblocks),并通过最小化正则化损失函数得出*权重。计算最小化形变之间的路径,即图元之间的路径,从而转变为通过在中间buildingblocks上进行反向传播来找到*网络参数。几何上,在每个时间步骤,ResNet-LDDMM搜索空间划分为多个多面体的*划分,然后计算*速度向量作为在每个多面体上的仿射变换。结果,即使它们很接近,图元的不同部分,也可以属于不同的多面体,并因此可以在不同的方向上移动而不消耗太多能量。尤其值得注意的是,团队展示了其算法如何能够预测微分同胚变换(diffeomorphictransformations)或更准确地说是bilipshitz变换。
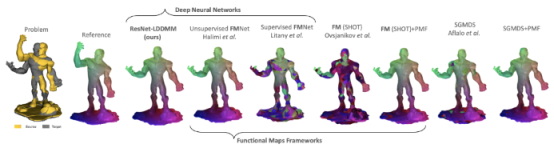
ResNetLDDMM(第三栏)与*方法的定性比较。
完整论文:https://ieeexplore.ieee.org/document/9775044
该五项研究之于人工智能技术与产业的深度融合及高效落地有着深远的意义,进一步夯实了特斯联作为城域AIoT产业开拓者的研发实力及领导地位。