

*的芯片供应商,如AMD和Intel,已经在多个产品中采用了小芯片(Chiplet)技术。根据我们的分析,这项技术可以将大型7nm设计的成本降低高达25%;在5nm及以下的情况下,节省的成本更大。我们预计小芯片将广泛用于这些高级节点中的数据中心处理器和网络芯片。Alphawave赞助了这篇白皮书的创作,但其观点和分析都是作者的观点和分析。
随着芯片设计人员努力应对摩尔定律的放缓,许多人正在采取一种称为小芯片的新方法。这种方法将一个复杂的设计,例如一个高端处理器或网络芯片,分成几个小芯片,而不是一个大的单片芯片。数据中心产品通常具有*的晶体管数量,是小芯片的早期采用者。AMD 和英特尔已经推出了多种基于小芯片的设计,英伟达也在开发小芯片技术。我们预计小芯片技术的使用率会提高。
数据中心客户是最苛刻的客户之一,需要更高的计算性能来提供新的云服务和更大的网络带宽来连接大量服务器。为了满足这些计算需求,英特尔和 AMD 竞相在其服务器处理器中塞入更多内核。英伟达强大的GPU已成为训练大型人工智能模型的热门工具,这些模型可以执行标准服务器无法执行的任务。大型数据中心已将以太网速度推至 100Gbps 甚至更高,同时需要具有高端口数的交换芯片。高端 FPGA 客户希望产品具有用于其前沿应用的更多逻辑门。
几十年来,摩尔定律不断改进晶体管技术,使芯片供应商能够满足这些客户的需求,但它正在失去动力。将晶体管密度加倍现在需要三到四年而不是两年。密度的每一次增加都伴随着晶圆成本的急剧上升,每个晶体管的成本几乎没有降低,这是摩尔定律的一个关键原则。每个新晶体管节点的功率和速度增益也有所减少。简而言之,迁移到下一个节点变得更加昂贵,而提供的收益却更少。
小芯片提供了一种创建更高级设计的替代方法。通过使用两个或更多芯片,公司可以将设计的晶体管数量增加到超出单个芯片所能容纳的数量。它可以将较旧的节点用于一些小芯片以节省成本,同时在需要*性能的地方使用前沿节点。对于复杂的设计,这种方法可以降低制造成本。随着设计转向 5nm 及以下,成本上升提高了小芯片的经济性。
数据中心中的小芯片
AMD 是*个引入小芯片架构的主要供应商。其最初的 Epyc 服务器处理器代号为 Naples,于 2017 年推出,在单个封装中具有四个相同(同类)小芯片,总共提供 32 个 CPU 内核。2019年,该公司又推出了第二款Epyc设计(“罗马”),使用8块CPU芯片实现64核,是当时英特尔*的处理器的两倍多。。Rome 设计增加了第九个小芯片,它集中了所有的 DRAM 和 I/O 电路,如图 1 所示;该芯片使用较便宜的 14 nm节点,而 CPU 小芯片使用7 nm晶体管来提高速度和功率。AMD 为其最新的第三代Epyc 处理器(“米兰”)保留了相同的小芯片配置。
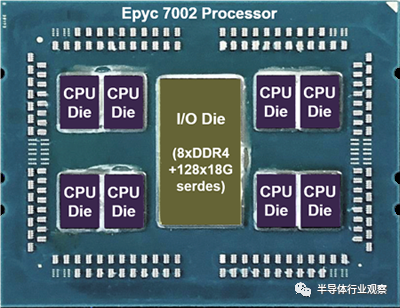
图 1. AMD 小芯片设计。Epyc 7002(“Rome”)处理器具有 8 个 74mm²CPU 芯片,每个芯片具有 8 个 x86 内核和 32MB 缓存。I/O 芯片尺寸为 410 mm²,并连接到 DRAM 和高速外围设备。有机包装尺寸为 58x78mm。(照片由 AMD 提供,林利集团提供)
对于Agilex FPGA,Intel采用了芯片,但采用了不同的方法。Agilex将设计的主要部分(包括可编程逻辑、CPU子系统和DRAM控制器)保留在单个芯片上。这些芯片(Intel称之为tiles)实现额外的I/O连接,如高速serdes、PCIe Gen5、高带宽内存(HBM2)和Optane持久内存。这种方法允许公司只需更改已安装的芯片即可提供具有各种I/O组合的Agilex产品。英特尔甚至可以创建特定于客户的芯片来添加特殊功能。公司可以添加新的小芯片,例如112Gbps的serdes或HBM3,即使在基本芯片已经投产之后。
Barefoot Networks 现在是英特尔的一部分,在其名为 Tofino 2 的 400G 以太网交换芯片中使用了小芯片。与 Agilex 一样,该产品将中央逻辑保留在单个芯片上,但将其 32 个以太网端口划分为四个小芯片。这种划分简化了封装中 I/O 信号的布线。我们相信以太网小芯片采用 16nm 技术,相对于将它们保留在主要的 7nm 芯片上,降低了成本。该公司还可以在完成其余复杂设计之前开发和测试高速以太网电路,从而降低开发风险。
其他生产中的小芯片设计包括华为 Ascend 910,它包括一个计算芯片和一个独立的 I/O 芯片。它使用硅衬底来连接两个芯片以及四个 HBM2 堆栈。有传言称,英伟达的下一代 GPU(也称为 Lovelace 或Ampere Next)将使用小芯片。英特尔计划在未来的处理器中转向小芯片,优化 CPU、GPU 和 I/O 电路的技术节点。其针对数据中心和超级计算机的 Ponte Vecchio GPU 分为多个小芯片,尽管英特尔尚未透露 2022 年产品的细节。最终,该公司希望通过在小芯片上实现单独的功能块、通过混合搭配过程创建新产品来减少处理器设计时间。.
小芯片的好处
将大芯片分成更小的小芯片通过提高产量来降低制造成本。传统的良率模型假设缺陷在晶圆上随机散布,并且芯片上任何地方的缺陷都会使其无法使用。因此,大芯片比小芯片更可能包含缺陷。掩模尺寸 700mm²的设计(可能的*尺寸)通常会产生大约30% 的合格芯片,而 150mm²芯片的良品率约为 80%。即使考虑到更多数量的小芯片,这种产量的提高也节省了大量成本。
为了提高大芯片的良率,一些供应商包括可以容纳某些缺陷的冗余电路。例如,一块 SRAM 可以有额外的行来替换任何失效的行。这种方法增加了芯片面积,但减少了易受缺陷影响的“有效面积”。小芯片设计可以去除冗余电路,减少芯片面积,同时仍然提高产量。
进一步的成本节约来自使用不同的制造节点创建不同的(异构)小芯片,这在单片设计中是不可能的。例如,对于密集封装的逻辑和存储器,7nm 晶体管比 16nm 晶体管便宜,但 I/O 接口通常具有模拟电路和其他无法从较小节点中受益的大型功能。出于这个原因,许多小芯片设计将 I/O 功能隔离到在旧节点中制造的单独芯片中。一些逻辑电路(例如加速器)可能不需要以与主处理器相同的*时钟速率运行,因此可以在中间节点中制造。使用较旧的工艺技术可以将这些小芯片的制造成本降低多达 50%。
公司可以通过在多个产品中重复使用小芯片来减少设计时间和流片费用。例如,AMD 在其*代 Epyc 和 Ryzen 产品中使用了相同的小芯片设计;PC 处理器使用单个小芯片,而服务器处理器最多包含四个小芯片。此外,AMD 可以通过改变封装中的小芯片数量来轻松提供广泛的 Epyc 核心数量。相比之下,英特尔通常会流片出三款至强芯片,每款都有不同的核心数,以涵盖每一代的全系列型号。同样,Barefoot 可以通过更改以太网小芯片的数量来扩展其交换机的端口数。
I/O 接口故障会导致产品无法启动。为了降低这种风险,Barefoot 将其前沿的以太网设计转移到一个单独的小芯片上,使其能够独立于主逻辑芯片开发和测试该电路。尽管其 Agilix FPGA 已经开始出货,但英特尔计划开发新的小芯片以随着时间的推移升级产品的 I/O 功能。
小芯片可以通过实例化比单个芯片容纳更多的晶体管来实现晶体管数量“超摩尔”的增益。Xilinx 从 2011 年开始使用这种方法,当时它将四个中型小芯片组合在一起,提供的门数是当时*的单片 FPGA 的两倍。AMD 的 Rome产品在 9 个小芯片上集成了 400 亿个晶体管,而英特尔的现代 Skylake Xeon 单片设计只有 80 亿个。然而,对于许多前沿产品,功耗 (TDP) 在设计达到*芯片尺寸之前限制了晶体管的数量。
小芯片成本研究
设计人员可以通过多种不同方式实现小芯片。有些使用同构的小芯片,而其他的则将计算和 I/O 功能隔离到不同的小芯片中。硅衬底在小芯片之间提供密集的布线和更大的带宽,但有机衬底的成本更低。作为一个简单的案例研究,让我们来看一个假想的处理器,它可以被分成四个同质的芯片。单片版本需要 7nm 节点中的 600mm²和昂贵的 60x60mm有机 BGA 封装,具有许多布线层来处理大量 I/O。该设计包括一个具有冗余行的相当大的内存,留下了 80% 的有效区域。
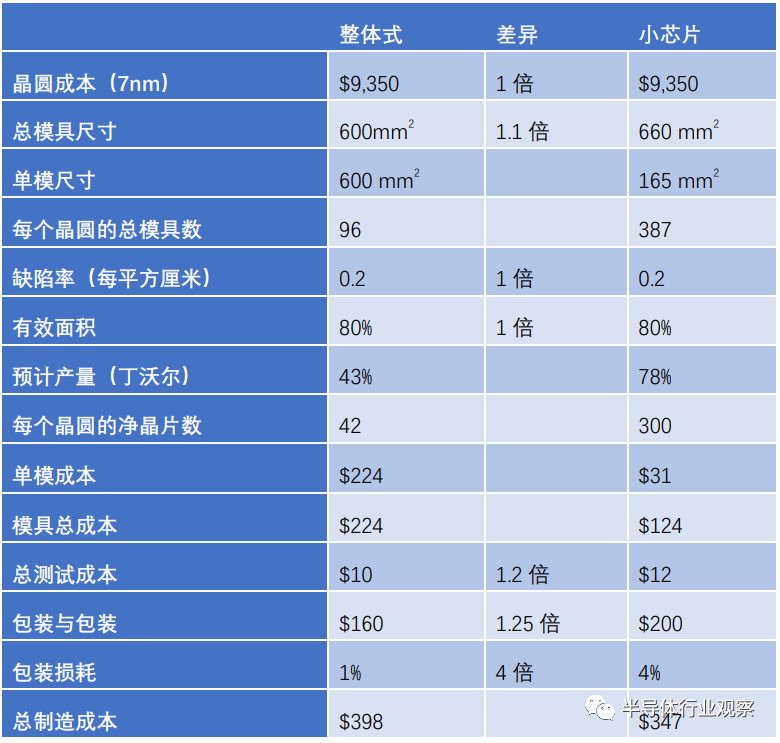
表 1. Chiplet 成本比较。这个比较假设一个大芯片 (600mm²) 几乎没有冗余(80% 的有效面积)和一个大 (60x60mm²) 的有机封装被分成四个相同的小芯片。小芯片降低了总芯片成本,但需要更昂贵的封装,净节省 13%。(资料来源:林利集团估计)
划分这种设计可能会产生四个 150mm²的芯片,但小芯片需要额外的芯片到芯片连接区域,这需要比芯片上信号大得多的驱动器;为此,我们估计有 10% 的开销。即便如此,如表 1 所示,较小芯片的良率几乎是大型单片芯片的两倍,从而节省了 100 美元的总芯片成本。
然而,由于测试四个芯片而不是一个芯片的开销,测试成本略高。由于多种原因,该包装已经很昂贵,但成本会大幅增加。如上所述,小芯片的总面积要大 10%,并且封装需要小芯片之间有一些空间,因此它增长到 60x80mm²。将 I/O 分布在更大的封装中减少了布置这些信号所需的层数,但新的芯片到芯片信号增加了布置的层数;我们假设这些变化不重要,并且层数保持不变。最后,多芯片封装的组装成本会更高,组装损耗也会更高。这些封装成本抵消了大约一半的芯片成本节省,净收益为 13%。
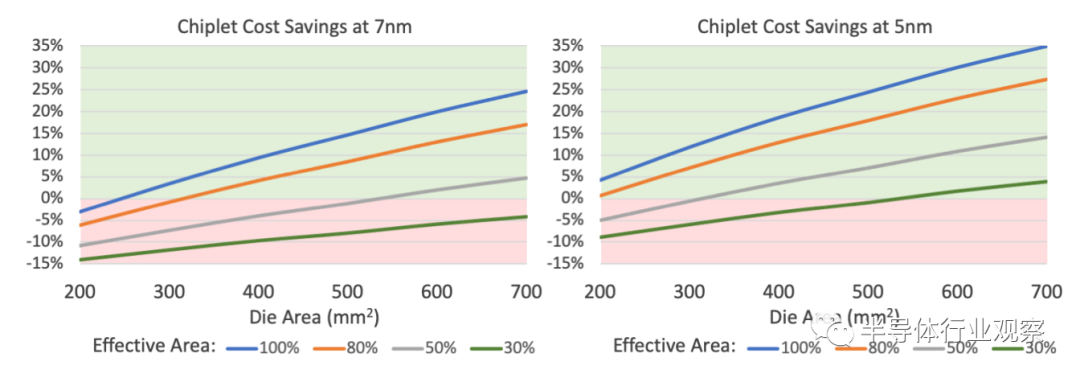
图 2. Chiplet 成本场景。小芯片对于几乎没有冗余的大芯片来说是*成本效益的。在 7nm 节点中,100% 有效面积设计的交叉点约为 400mm²,而对于 5nm,交叉点低于 300mm²。(来源:林利集团分析)
将此成本模型扩展到其他示例,我们看到了在几乎没有冗余或没有冗余的情况下*的节省。在 7nm节点中,小芯片降低了单片设计的成本,有效面积大于 400 mm²,如图 2a 所示。根据我们的模型,对于相同内核占用 50% 或更多芯片面积的高度常规处理器,小芯片通常会增加制造成本。在这种情况下,冗余内核会提高大芯片的良率,从而降低小芯片的良率增益。
在更先进的制造节点中,小芯片在更广泛的设计中具有优势。例如,在5nm 工艺中,晶圆成本几乎翻了一番,达到 17,000 美元。因此,转移到更小的芯片所节省的成本更大,更容易抵消封装成本的增加。根据我们的模型,5nm 的净成本节省比 7nm 高约10%,这意味着小芯片可以降低小至 200mm²的裸片成本。即使对于有效面积为 50% 的处理器,在 300mm²以上也会节省成本。尽管 3nm 的晶圆成本尚未确定,但成本节约肯定会再次上升,将小芯片的盈亏平衡点推到150mm²以下。
结论
我们的成本分析表明,用于大型数据中心芯片的芯片组架构具有相当大的优势。在 7nm 中,我们估计分解非常大的芯片最多可节省 20% 的成本,而小至 400mm²的芯片则节省较少的成本。不断上涨的晶圆成本提高了小芯片方法的价值,将超大芯片的潜在节省推至 5nm 的 30% ,在3nm 上则可能达到 40%。在这些先进的节点中,即使是 300 mm²或更小的中等尺寸芯片,小芯片也会很有吸引力,尽管这些较便宜的设计节省的成本自然会更小。该分析排除了其他潜在好处,例如通过在尾随节点中构建部分设计来降低制造成本,或通过在多个产品中重复使用小芯片来降低设计成本。
该分析与迄今为止的小芯片部署一致。如果作为单个 7nm 芯片实施,大多数生产中的小芯片产品将是掩模尺寸(或更大),这使得这种方法最适合昂贵的数据中心芯片。一些供应商将他们的 PC 处理器称为小芯片设计,但他们只是将主处理器和南桥封装在一起,英特尔已经这样做了好几年。到 2022 年,我们预计大多数 PC的GPU 、以及一些中端网络芯片和 FPGA将采用小芯片设计技术。设计内部 ASIC 的公司也将开始采用该技术。
小芯片并不适合所有设计。PC 和智能手机处理器的尺寸通常为 150 mm²或更小,因此它们不会受益。英特尔和英伟达等供应商通过减少某些产品型号的核心数量以容纳有缺陷的核心来提高产量;这种方法还降低了小芯片的成本效益。异构小芯片设计(例如 Agilex 和 Ascend)实际上会增加昂贵的流片数量,尽管其中一些流片通常会转移到较旧的、成本较低的节点上。在多个产品中重用小芯片可以抵消额外的流片成本,但考虑到不同产品细分和跨代的需求不同,到目前为止,我们很少看到重用示例。
然而,许多数据中心芯片都是小芯片技术的*选择。该技术已经引起了*供应商的极大兴趣,AMD、英特尔和英伟达都在出货或至少开发基于小芯片的产品。正如这些供应商所证明的那样,优势不仅在于节省成本,还包括构建比任何单片芯片都更大的设计、通过解耦新技术降低进度风险以及提供灵活的产品配置。其他在高级节点(包括 ASIC)中构建大型设计的公司应该评估这种新方法,以确定他们是否可以从小芯片技术中受益。








