

若能将各来源的数据汇聚后应用,数据的价值将会指数级上升。理想很美好,但数据的自由流动常伴随着隐私泄露问题。
有没有一种方法能够在安全合规、保障用户隐私的前提下,使数据在各个企业/机构之间自由流动,并产生应有的价值?
隐私计算或许是一个答案。
隐私计算,广义上是指面向隐私保护的计算系统与技术,涵盖数据的产生、存储、计算、应用、销毁等信息流程全过程,想要达成的效果是使数据在各个环节中“可用不可见”。目前*落地于金融、医疗等行业。
36氪观察到,约从2018年开始,无论是BAT等大厂,还是成熟的大数据公司,或是初创型科技企业,已接连入局隐私计算。
资本市场也动作频频,成立两年左右的「华控清交」已完成多轮融资,投资方包括清华大学、中国互联网金融协会、北京市海淀区创业扶持基金、香港交易及結算所有限公司(港交所)、联想集团和高榕资本等。其他受到关注的公司还包括「翼方健数」、「数牍科技」等,它们背后也有奇绩创坛、红杉中国等明星机构。「锘崴科技」、「光之树」等公司也在近一年的时间里,接连获得投资。
经36氪访谈,许多人认为这个由政策驱动、市场需求催生的新赛道,背后或许蕴藏着新的平台型机会——在数据合规的要求下,谁能汇聚海量优质的数据源,并以高效的技术/产品方式帮助需求方提取可用数据,实现数据价值,谁就可能成为新的大数据平台。
而平台型机会历来是VC机构最青睐的"Big Story"——业务上可攻可守,终局是赢家通吃,未来能为投资人带来高估值、高回报。
从这一观察出发,我们试图在本文回答以下问题:
1、隐私计算为何在此时受到高度关注?
2、隐私计算如何在技术上实现"可用不可见"?目前主要的玩家有哪几类?
3、为什么说隐私计算是一个平台型机会?会采用什么样的商业模式?
4、什么样的隐私计算公司能够成为平台?
5、行业火热,机构仍有投资机会吗?
一. 隐私计算的高关注度缘何而来?
数据流通和隐私保护的矛盾由来已久,那为何隐私计算会在此时获得超乎往常的关注?背后的核心驱动力主要有两个:政策上的合规避险,商业上的数据流通价值。
(1)政策上的合规避险
隐私保护和数据流通的双重矛盾由来已久,但一直到Facebook、华住集团等大规模数据泄露事件频发,关注度和讨论度才进一步提升。
政策的敏感度在全球范围内显露。国际上,欧盟于2016年发布、2018年实施的《通用数据保护条例》(GDPR),是目前最全面、应用最广泛的隐私保护法规之一。GDPR对违反某些重要规定的罚款最高可达2000万欧元,或全球年营业额的4%。
中国的部分法律法规中也可找到相关踪迹。2016年11月,中国发布了《中华人民共和国网络安全法》,这是*部和网络安全、数据保护相关的国家级法律,要求互联网企业不得泄露或篡改收集得到的用户个人信息。2020年3月6日,《信息安全技术 个人信息安全规范》发布,从更为细致的角度明确了各条款的具体要求。在《民法典》中,也已纳入个人信息保护的相关内容。最新的动向是在今年7月2日,中国人大网发布《数据安全法(草案)》,也强调了数据安全和发展共存的意义。
在强监管趋势下,过去几年已有一些公司由于类似问题遭受重创,这些公司已纷纷停止相关业务,其中一些尚有余力者也希望能摸索出符合合规要求的业务路线。
这一系列法规的接连出现,都意味着个人隐私与数据流通的矛盾已经上升至法律层面,以往粗放型的数据交易模式将由灰色地带上升至触犯法律红线的行为。
(2)流通的数据才有价值
为了保护数据安全,最简单的方法就是停止数据的使用和流通,但这种逃避的方式,会给AI、金融、医疗等行业带来打击。
在AI领域,海量数据是计算机视觉、自然语言处理、语音识别等技术发展的基础——它们需要经过海量数据的训练才能达到理想性能水准。在金融业中,金融机构需要收集消费者的资质信息、购买能力、偏好等数据,以便为信用良好的消费人群提供定制化的金融服务。在医疗行业,精准医学、AI制药等细分方向的发展也和数据流通息息相关。
今年的“新基建”规划也提到了大数据产业,根据国家发改委的官方解读,新型基础设施之一的融合基础设施,主要是指深度应用互联网、大数据、人工智能等技术,支撑传统基础设施转型升级,比如,智能交通基础设施、智慧能源基础设施等。并且,在日前发布的《中共中央国务院关于构建更加完善的要素市场化配置体制机制的意见》中,数据与土地、劳动力、资本、技术等传统要素并列为要素之一,这表明数据正在成为现阶段最核心的生产要素。
在政策驱动下,可用不可见的隐私计算,成了既满足合规避险又满足业务需求的优解答案,资本自然闻风而动。
二. 隐私计算如何在技术上实现数据"可用不可见"?主要玩家有哪几类?
从技术角度出发,和隐私计算相关联的概念很多——多方安全计算(MPC)、可信硬件(TEE)、联邦学习、差分隐私、区块链等。目前业内采用的主流技术包括三类:多方安全计算(MPC)、联邦学习和可信执行环境(TEE)。
(1)多方安全计算
多方安全计算(Secure Multi-Party Computation,简称MPC)是指在无可信第三方情况下,通过多方共同参与,安全地完成某种协同计算。即在一个分布式环境中,多个参与者共同完成对某个函数的计算,该函数的输入信息分别由这些参与者提供,且每个参与者的输入信息是保密的,在计算结束后,各参与者获得正确的计算结果,但无法获知其他参与者的输入信息。这种方式主要基于密码学的一些隐私技术,相关概念还包括同态加密(Homomorpgic Encryption)、不经意传输(Oblivious Transfer)、混淆电路(Garbled Circuit)和秘密共享(Secret Sharing)等。
(2)联邦学习
联邦机器学习(Federated machine learning/Federated Learning),又名联邦学习,联合学习、联盟学习。联邦机器学习是一个机器学习框架,能帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。联邦学习的系统架构大致分为横向联邦学习、纵向联邦学习、迁移学习三类,分别对应不同数据集的差异情况。
(3)可信执行环境(TEE)
以上两种方式主要是在软件和算法层面实现隐私计算。可信执行环境(TEE)则基于硬件实现。
这种方式的思路是在CPU 上构建一块安全区域,这块区域的作用是给数据和代码的执行提供一个更安全的空间,在这个安全区域内进行相关的计算。比较有代表性的是Intel-SGX、ARM-TrustZone等。
这三种方式在安全性、工程能力和落地场景等方面存在不同的特点,我们可以通过下文这张对比图,了解不同技术思路的优劣势。
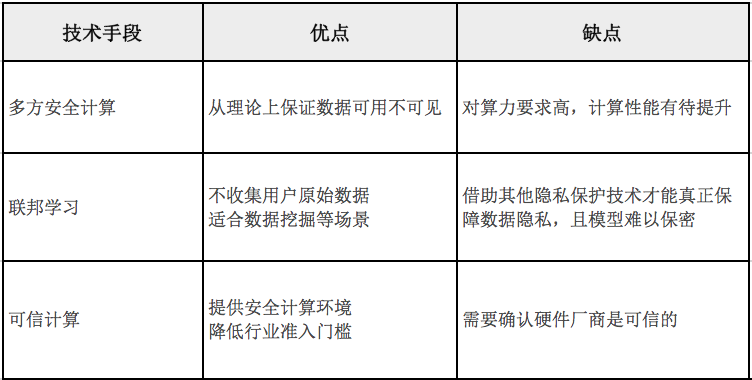
36氪根据采访和公开信息整理
当然,这三种技术思路可以在不同场景下彼此结合,也可以和差分隐私、区块链等技术结合,共同保证隐私计算的效果。事实上,隐私计算企业为客户提供的,大多都是融合了多种技术思路的解决方案,但也会根据公司已有客户、此前技术积累等因素存在不同程度的倚重。
至于该领域目前的玩家,我们认为大致可分为以下四类:从成立初就专攻隐私计算的初创公司、过去为银行等客户提供大数据服务的企业及金融机构本身、泛区块链背景公司和BAT等综合型大厂。
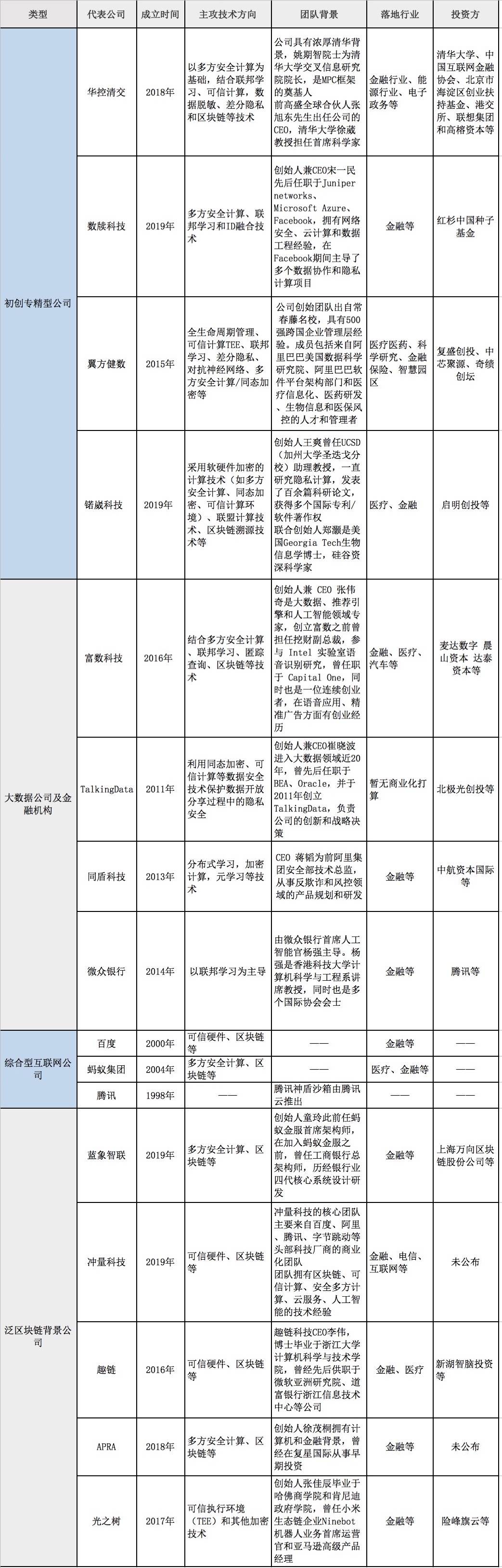
隐私计算四类主流玩家(排名不分先后)
在落地中,金融领域是当前的强需求行业,也是多数公司此时主要扩展的行业。
其中,信用贷类产品是重点。为降低放贷风险,金融机构需要通过授信模型确认贷款风险、贷款数额等信息。这里的授信模型需要调用多方数据,而隐私计算能满足构建授信模型时的数据合规共享需求。
医疗行业同样需求较高,翼方健数、锘崴科技的产品多在这一行业落地。科研是医疗行业的需求之一,目前医疗科研的发展一定程度上被可用数据的范围与数量所制约。一些资料显示,若要开发出性能良好的医疗AI,需要一万名专家花费10年时间才可能收集到足够的可用数据。而隐私计算可以使大家在保护隐私的前提下打破数据孤岛,获得足够的数据加速研发进程。
三. 为什么说隐私计算是一个平台型机会?它会用什么商业模式来赚钱?
(1)市场前景、上下游分散、平台型属性
“以后所有涉及到数据流通的环节,都会应用到隐私计算。”尽管行业刚刚起步,但创业者对这一技术的应用前景却无比乐观。并由此推导得出,这是一个拥有广阔前景的大市场。
这种观点将数据市场中所有基于应用数据的的份额,都纳入了隐私计算的市场规模中。这可能有所夸大,从当下来看,比较切合实际的市场规模计算方式应该和具体落地场景相结合。
比如在金融领域中,传统的贷款需要提供抵押物,个人授权具体银行从人民银行处拿到征信报告就可以得到贷款。而在进行类似花呗的创新消费金融业务时,可能需要更多的数据来源形成更精准的授信模型。这些数据来源包括社保数据、医保数据、同业数据、其他用户行为数据等,这就牵扯到不同数据拥有方之间的数据合规流通问题,需要隐私计算来帮忙解决。
所以,隐私计算在金融领域的市场规模可能要框定类似消费金融等具体场景,再和这类银行的IT支出数据结合计算。其他行业,如隐私计算在医疗领域的市场规模也需要结合具体场景测算。
但从理论上来看,这依然是一个需求激增、高速增长的行业,市场规模或不及大数据行业整体规模,但也会高于传统数据安全市场。
平台型机会往往诞生于双边主体分散、需求多元的行业,如此一来平台在其中进行连接的价值才能得以体现。以隐私计算目前落地最多的金融、医疗行业的数据产业链为例,上游数据来源有各类型的APP、三大运营商、征信公司、医疗大数据国家队、各家分散的医院数据等等,下游目前集中于银行、保险公司、药厂等,未来还可能包括需要合规使用大数据的公司,行业特性满足平台诞生的前提。
我们再来看,为何隐私计算是其中的平台机会。
如果简单将数据产业划分为数据源、数据流通、数据应用三个部分,以往的数据流通可能存在以下现象——一些大数据公司通过爬取技术抓取数据后,倒卖数据和以此生成的报告,而这无疑侵犯了用户隐私,且存在法律风险。
在政策开始逐步禁止企业泄漏和篡改用户数据后,能够实现"可用不可见"的隐私计算,成为了新的数据流通渠道,进而为上游的数据源,下游对数据合规分享、使用有需求的各行业客户,进行数据调用、流通的连接匹配。
而在政策和需求的双驱动力下,会有更多不限于金融、医疗行业的企业客户,意识到需要在储存和使用数据的同时保护隐私安全,一家隐私计算公司具备网罗数据源、技术/产品和客户的能力,就有机会形成一张覆盖各行业的数据网,成为一个超大规模的隐私计算平台。当前隐私计算入局者众多,平台当然更可能从已有的公司中衍生而来。
(2)用什么商业模式来赚钱?
在商业模式上,相比单纯售卖软硬件的方案,平台不仅边际成本更低,同时还可以与各种数据源、技术提供方探讨抽成、分润的盈利模式。
具体来说,边际成本更低体现在:
隐私计算企业服务上游数据源时,需要处理各种千奇百怪格式的影相、图表、文字数据,尤其是医院的数据,处理起来会相当复杂。但数据一旦介入,就可以一劳永逸。
而在面向下游需求方时,能够快速完成软硬件部署,之后需要做的是持续运营。而行业长期存在定制化需求,私有化部署将持续存在,这可能会拉高客户的转换成本,后续的数据沉淀和运营或能进一步增强客户对平台的黏性。
而相比一锤子买卖,根据数据交易总量,按流量抽成,是把隐私计算从一个技术服务商变成平台机会最刺激的地方——原本只能从客户的IT投入中切分一块蛋糕出来,主要价值体现在于合规避险,现在却可以在整个数据产业链的流通环节,按照数据使用量或交易规模获取分润,还可以向数据源、技术提供方收取"准入费"或者是其他增值服务费(如为获取展示位、精准推荐的营销广告费用),蛋糕也就被做大了。
但目前尚未有隐私计算企业真正通过平台模式获得收入,按照软硬件产品部署和项目方式收费仍然是各路玩家现有的主流方式。从逻辑上,平台思路美好且天衣无缝。但目前行业还处于早期教育市场、拓展客户阶段,如果客户方长期处于交易的强势地位,项目制收入将会成为常态,平台也将成为空谈。由此衍生的一个问题是,隐私计算平台的关键点和风险点是什么?
四. 什么样的隐私计算公司能够成为平台?
我们认为,具备工程落地能力、整合足够高价值数据源、在此前已有相关行业客户积累,以及能证明公信力的公司更有机会长成平台。
这一判断的根源来自,所有平台要形成壁垒的关键点都在于规模,隐私计算也不例外,想要建成平台,就必须垄断足够多的上下游。这时,隐私计算服务商不得不面对以下四个问题:(1)工程落地能力;(2)高价值数据源的合作态度;(3)平台可信性;(4)效率究竟能提升到什么程度?
(1)工程落地能力
在实际商用环节,工程落地能力是检验产品的重要指标,具体可拆解为算力和带宽两方面,其中算力影响数据处理能力,带宽影响数据交互速度。
算力掣肘隐私计算已久。一些包含在隐私计算方案内的技术,比如多方安全计算并不是新鲜事——早在上个世纪八十年代,图灵奖得主姚期智院士就创立了多方安全计算理论。但影响该理论落地的一个重要因素就是算力,「华控清交」CEO张旭东曾在一次分享中提到,公司成立的目标之一就是克服算力问题,让多方安全计算真正商用。因而在实际操作中,「华控清交」采用了明密文结合的方式来提升算力。
在带宽方面,「360金融」曾做过相关调研,其首席数据科学家沈赟称,在实际运作过程中,联邦学习对网络带宽要求比较高,在学习过程中需要把中间计算值相互传输,迭代次数越多需要交互的中间数据也越多, 带宽不够会拖慢学习的速度,甚至出现学习中断等一些异常情况。
广州金控征信服务有限公司(简称「广金征信」)大数据负责人仇小星介绍,由于广金征信目前的重点项目信易贷平台(广州站),为中小企业提供以信用为基础的新型融资对接服务,汇集了来自政府部门、金融机构、第三方信用服务机构等多渠道的企业信用信息。为达成这些数据在安全前提下的开放应用,公司决定采用隐私计算产品辅助数据共享、建模。目前该公司的合作方为「富数科技」,这是一个隐私计算产品在政务大数据场景中的落地案例。
在实际使用过程中,仇小星认为当前多数隐私计算类产品可以持续提高数据处理的效率,“现在如果数据量大一些,联邦学习的处理效率就会有所下降,相比传统建模速度还是有明显下降的。”他补充到,由于目前金融行业的建模训练频次不是非常高,所以这样的效率依旧在接受范围内。
(2)高价值数据源的合作态度
数据源是进行数据处理的基础,现有隐私计算公司为客户提供的解决方案,本质上是改变了数据流通的方式,但数据本身的质量才决定数据最终的使用效果。
现有数据来源有各类APP、整合式数据提供方(如运营商)和客户等几种。
其中,像三大运营商这类整合式数据提供方往往掌握了海量*质的数据,在手机实名制的背景下掌握着用户的背景资料、行为数据、通话记录、交费记录等信息,过往这些数据在征信等场景中已起到举足轻重的作用。
所以在金融领域中,上游数据源已经形成一定的集中效应,其合作态度会影响主攻金融领域的隐私计算公司对平台的搭建。据了解,目前已有公司在和运营商沟通合作。不过TalkingData CTO阎志涛根据公司服务经验介绍,目前运营商对数据共享态度还处于保守状态,而其他类型的数据源在考虑合作时不会仅考虑技术解决方案,会更看重落地场景。
如果撬动上游有困难,那么就需要集中相当数量的下游,从而尽量促使更多上游数据源加入其中。「青桐资本」执行总经理毕英哲认为,银行、政府等现在是最有意愿接入多方数据开展业务的角色。
利益是各方最重要的连接点,平台积累的客户越多,拿单能力越强,越能吸引更多的数据源参与其中。在隐私计算这一领域想拿到单,公司背景以及自带的客户资源是一个因素。从这个角度看,以往在相关领域有所积累的公司(如金融数据服务商)会较有优势。
相较而言,医疗行业中的数据在数量分布上不如金融领域集中。36氪了解到,目前有公司在积极拓展医疗大数据国家队成为合作对象,他们认为,在实际情况下一家一家做地推,请客户进行数据的标准化并不现实,和国家队合作,这些机构本身拥有牌照,且已采用相关数据格式标准,公司可以较顺利地将数据接入系统中。
这或许是一种可行的思路——由于技术手段和医院方的态度,患者的治疗数据往往还散落在各大医院中,越头部的医院拥有越多高价值数据,而考虑到医院体系较为封闭,更需要强推动力来推广。
总体来看,现阶段抢夺高价值数据源也是各家优先级较高的事情,目前已有公司在探索和这类数据源进行利润分配的商业路线。
(3)平台的可信性
隐私计算本质上是由数据合规交易推动的市场机会,合规是其中的重点,只有平台本身得到信任,才可能撬动更多的上下游角色。
金融机构是强风险管控机构,要打开这类客户的信任切口比其他行业更难。
一位银行从业人员透露,银行由于担心数据泄露的风险,仍然更倾向于自己解决数据合规流动的问题,但在技术能力无法满足的情况下,也会考虑外采,“具体合作到什么程度得谈,基本上现在各个行都想自己处理。”该人士透露,某些银行倾向和此前已有金融服务经验的大数据公司建立合作。
「360金融」沈赟认为,如果某些参与联邦学习的公司(特别是主控方)拥有较高权限,在部署的代码中留有一些后门, 又不遵守协议进行恶意数据传输操作,就可以拿到各方数据,“从技术设计层面,比如所有的代码都开源、可检查可以避免这个问题。但现有的框架确实存在操控空间。”
上游数据源也是一样,运营商数据的重要程度已经是普遍共识,这类机构在考虑数据共享的同时也会重视平台的可信性。
而在医疗领域,「华大基因」曾在2018年,因为“14 万中国人基因大数据”项目受到泄露个人隐私的质疑。其在回复深交所问询函时强调,该项目分析工作均在境内由中国科研团队完成,样本及数据保留在深圳国家基因库,不存在遗传资源数据出境的情况,研究披露的是群体分析结果,不存在泄漏个人隐私的风险。
但此类质疑必然进一步提高了数据源对数据隐私的重视,平台的可信性也就会成为达成合作的必要考量标准之一。
“这个事儿如果真的要成立的话,可能要抱大腿。甚至我认为应该是一个运营商投资或者控股的公司才行。”一位长期关注隐私计算领域的观察人士如此形容公信力的重要性。
(4)平台究竟能帮上下游将效率提高到什么程度?
这个问题直接冲击平台的价值。
数据交易并非新鲜事,尤其是在金融领域,隐私计算接入的数据源和客户方之间,可能早已建立起业务合作。对产业链上的一些上下游而言,目前只是缺失了使数据安全合规分享的方案,他们需要的只是技术方案提供方。如此一来,隐私计算公司成为通道型平台的意义或许没有想象中那么大。
平台在这种场景下可以提供的增量价值是,尽量汇聚更多的上游和下游,让此前暂未建立联系的双方拥有更多的选择权。再者,当平台扩展进上下游更加分散的行业时,其价值或许会更加突显。
此外,有潜力成为平台的公司还需在自身产品上多进行打磨,并形成差异化的特点。
在上游资源暂未完全开放、下游需求也未全面爆发的蛰伏期,将产品打磨完善是不二选择。「广金征信」仇小星介绍,由于当下各技术提供方已经在产品内构建了一些机器学习模型,功能比较类似。所以「广金征信」在选择合作方的时候,也会考虑产品操作体验,以及数据可视化探索、模型实时监测等辅助性功能。
而在愈发增强的数据隐私保护潮流下,许多公司已频频发声,意在推广产品的同时教育市场。在平台的前进道路上,企业应意识到各种技术路线都有其适配的场景,比如联邦学习更适合数据挖掘,多方安全计算的安全性更高,这些技术需要彼此结合使用,才能满足客户的综合需求。从结果上看,大多数公司已经意识到了,并因此出现了产品方案的同质化现象。
「小苗朗程」合伙人方正浩认为,方案同质化意味着市场发展到下一阶段,可能会形成企业之间的价格战。如果一家企业能够提供在同质化产品之外的附加产品价值,在一个或多个领域内提供更深入的解决方案,就会在一定程度上拉开和他人的差距,更有可能形成竞争力。
五. 行业初兴,仍有早期机构的投资机会
总体来说,隐私计算行业目前刚刚起步,各家客户数量也不多。在36氪的调研过程中,不少潜在的目标客户甚至未曾听闻过“隐私计算”的概念。但也正因行业初兴,才有了创业投资机会。
在融资方面,隐私计算创业公司普遍集中在B轮之前的阶段,且仍存在资本市场视野外的公司,也陆续有新的创业公司出现,对于早期机构而言,现在入局为时不晚。
在投资回报方面,我们暂时难以在二级市场找到直接对标的公司,来预判这将是百亿级或千亿级的创业投资机会。但由于隐私计算的想象空间,即便是处在整个创投行业出手谨慎的时期,投资机构仍然愿意一掷千金。一些行业观察人士告知36氪,赛道上玩家的估值大多在1~3亿元区间——有团队背景较好的公司,即使业务没有太多进展,天使轮后的估值也已达到近3亿元,而一家明星公司的估值在约半年前已超过6亿元。
这些愿花高价买门票的投资者多半相信平台成立的可能性,但故事的另一半是——还有些从去年开始观望却仍未出手的机构认为,隐私计算公司要成为平台,仍需迈过产品工程化、聚拢数据源、可信性等门槛,各家公司当下的高估值需要打上问号。
无论是哪种态度,不可否认的是——隐私计算确实是目前数据合规流通的热门解法之一,俨然已成为当下投资圈的热点话题。









