

这是一个打破传统大语言模型解码限制的研究。
英伟达提出了全球*三模式的大语言模型系列,只需简单更改注意力模式 / 掩码,即可在自回归、扩散和自推测解码之间切换。
一个模型,三种解码模式,没有额外的草稿模型,没有架构变更。最快的模式 token 吞吐量能提升 4 倍。

我们知道,传统上大语言模型主要采用的自回归解码(Autoregressive,AR)方式在低 batch sizes 时严重受内存限制,你必须为每个生成的 token 将海量权重从 HBM 移动到 SRAM。这种模式虽然准确率高,但由于无法并行,在并发量较低、追求单用户极速响应的场景(如个人 AI 助手)下,GPU 算力常常无法被充分利用,导致生成速度遭遇瓶颈。
与之相对的是,扩散模型(Diffusion Model)能够提供并行生成的能力,但由于训练时平等对待所有 token 排列,缺乏自回归模型天然的从左到右的语言先验,历史上它们的生成质量一直落后。
如果有一个模型能同时结合两者的优势,会是什么样?英伟达这项研究的核心目的,就是通过统一的模型架构消除这两种范式的隔阂,做到「准确率与速度兼得」。
HuggingFace:https://huggingface.co/collections/nvidia/nemotron-labs-diffusion
项目页面:https://research.nvidia.com/publication/2026-05_nemotron-labs-diffusion-tri-mode-language-model-unifying-autoregressive
技术报告:https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_Diffusion_Tech_Report_v1.pdf?VersionId=db8_EMO8B.vmU26.jr7Le9pN3MqcUDNL
英伟达提出的模型不使用弱外部 MTP 模型或额外 heads,而是利用自身的扩散模式同时起草多个 token,然后在 AR 模式下使用相同的 KV cache 验证它们。这样,你就获得了扩散模型的并行生成,同时具备 AR 的严格准确性。
该方法比起之前的 Eagle/MTP 方法具有更高的接受率,无需额外权重,或者只需少量额外权重即可获得更高的接受率。
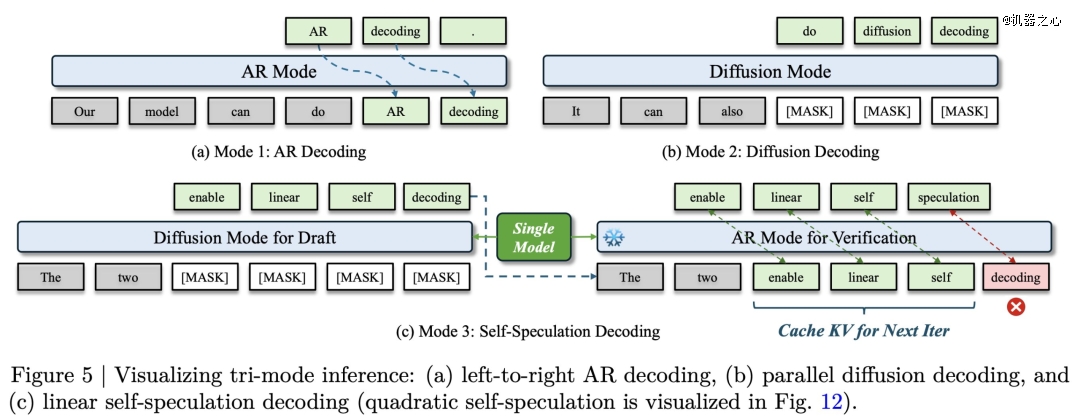
训练时,模型同时优化两个损失函数:AR Loss 和 Diffusion Loss,这完全改变了扩散语言模型质量的游戏规则。为了稳定训练,团队采用了两阶段训练策略,并引入了 Global Loss Averaging 技术,大幅降低了扩散模型训练中因随机掩码导致的梯度激增问题。
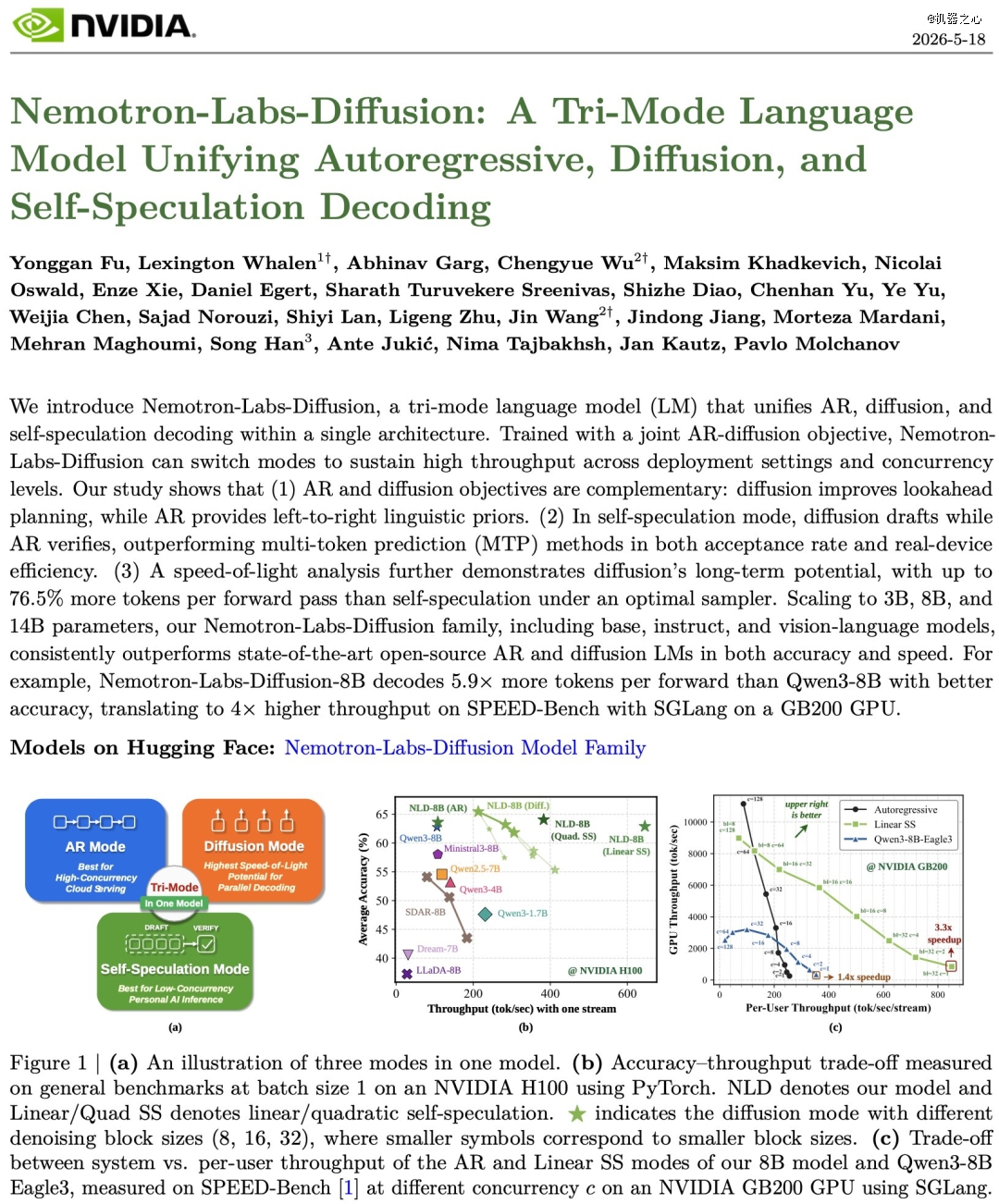
借助这种训练方式,模型在推理时可任意切换以下三种模式:
自回归模式(AR Mode): 传统的从左到右逐字生成,保留完整的因果注意力机制。适合高并发、计算密集型的云端服务;
扩散模式(Diffusion Mode): 采用分块去噪(Block-wise Denoising),利用双流注意力机制(Dual-stream Attention)在块内进行大规模并行 token 推测。为了进一步压榨并行的上限,英伟达还专门训练了一个轻量化采样器(Trained Sampler)来替代传统的置信度阈值判定;
自猜测模式(Self-Speculation Mode): 它将传统的 Speculative Decoding(需要一个额外的小模型来垫字)改造成「单模型自我博弈」。
该研究给出了 3B、8B、14B 三个尺寸的基座模型,展现出了对现有开源自回归模型及扩散模型的全方位碾压。研究人员在之前的开源 dLLM(如 LLaDA、Dream 和 SDAR)上看到了从 9% 到 22.4% 的巨大准确率提升。也就是说,现在我们有了新的 SOTA dLLM。
在测试中,新模型匹配了 Qwen3-8B 的基线 AR 准确率,但在前向传播中达到了 5.9 个 token(TPF)。
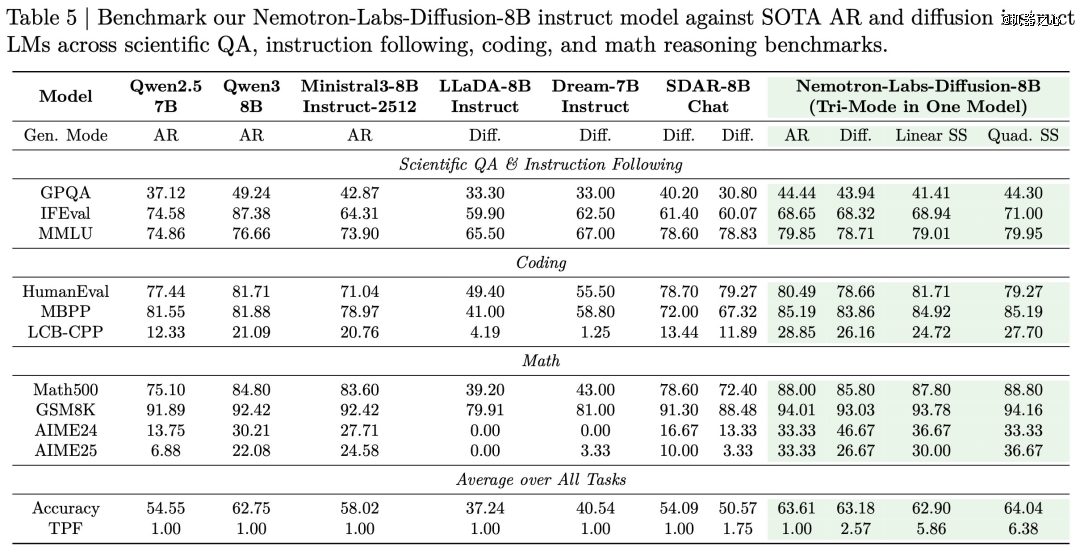
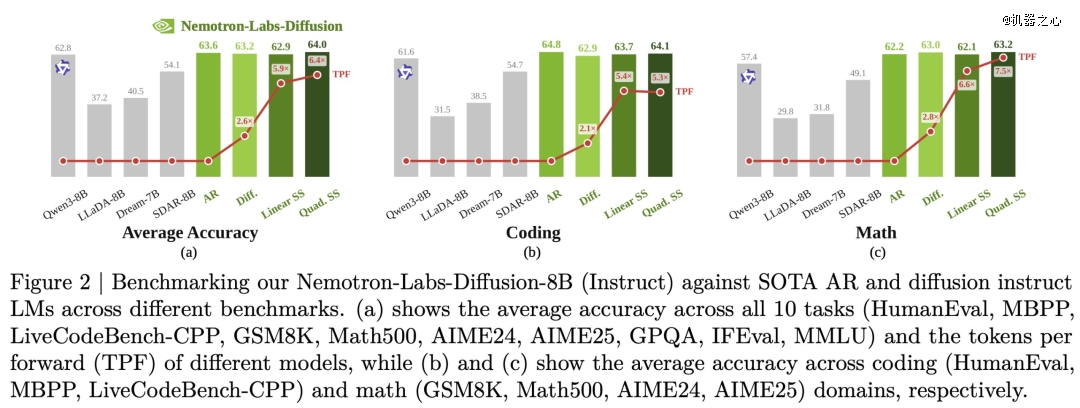
dLLM 的主要优势在于效率。
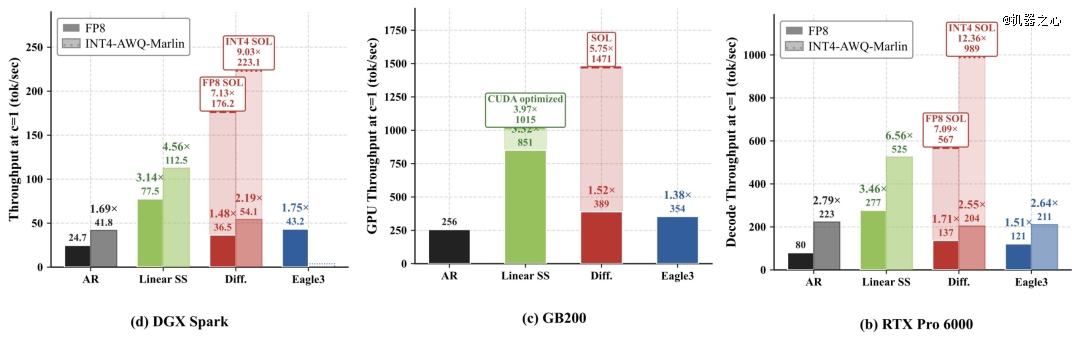
NLD 在实际应用中的加速效果(8B 模型,单用户场景)如下:
DGX Spark:FP8 精度下提速 3.14 倍;INT4 精度下提速 2.7 倍(112 token/s vs 41.8 AR);
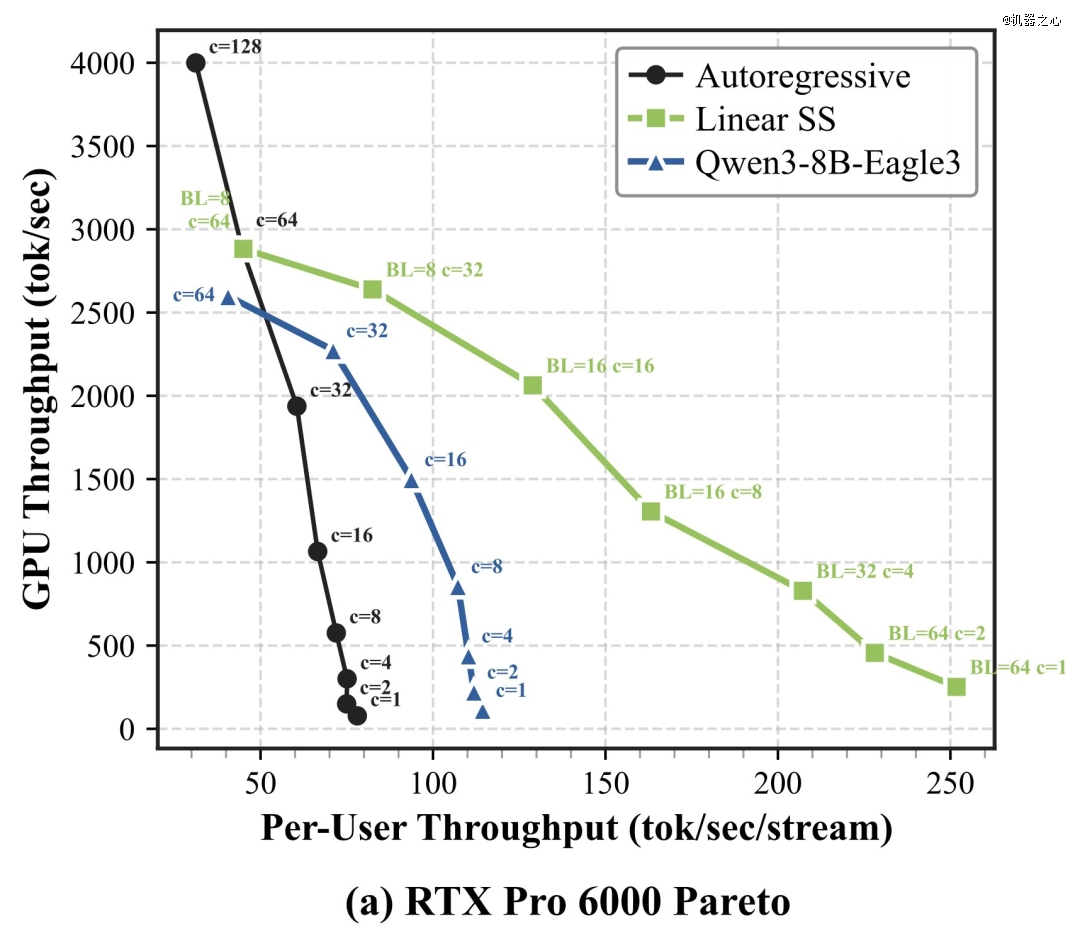
RTX 6000 Pro:FP8 精度下提速 3.4 倍;INT 精度下提速 2.3 倍;
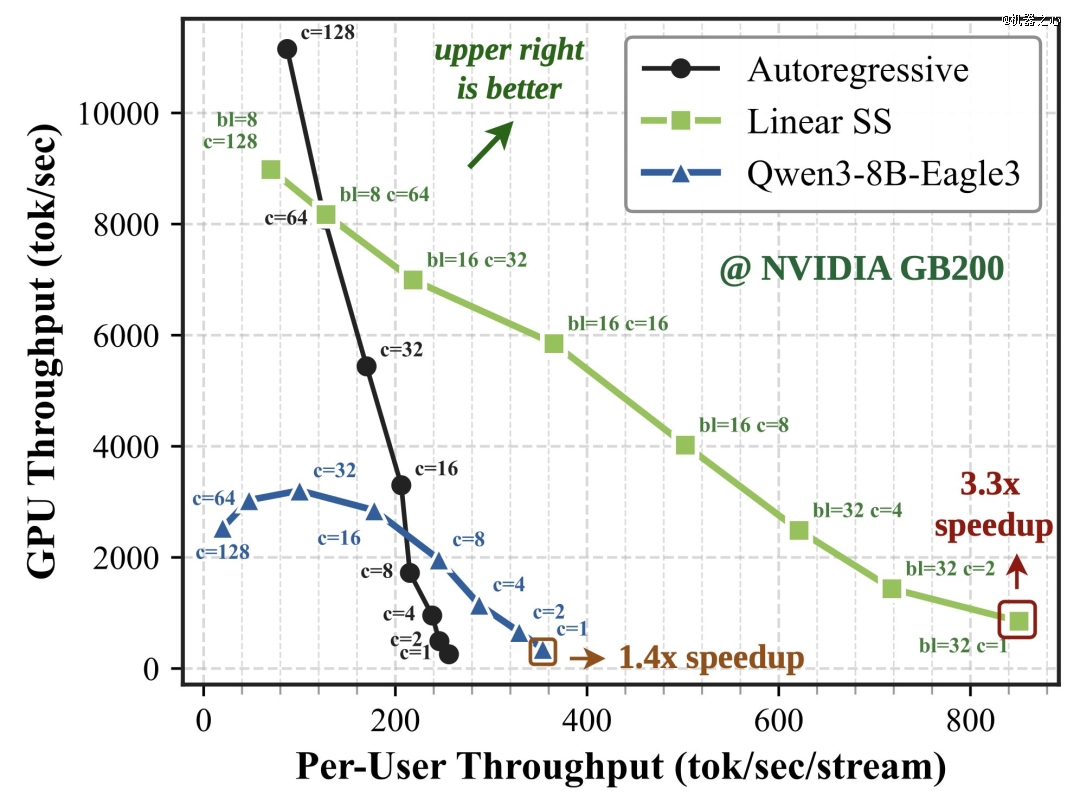
GB200:提速 3.3 倍(850 tok/s);若配合自定义 CUDA 内核,最高可提速 4 倍。
在 SPEED-Bench 基准测试中,线性自推测(linear self-speculation)机制实现了 8.7 的平均接受长度,相比之下,Qwen3.5-9B-MTP 为 4.7,Qwen3-8B-Eagle3 为 2.81。该数据为针对数学、代码、推理及多语言任务的综合估算值。
具体方法上,这种能力并不是单个的解决方案。
在低到中等并发度下,自行推测*占据主导地位(非常适合个人 AI 和交互式代理)。但在巨大的批处理规模下(>64 个流),推理会变成计算受限。英伟达的解决方法是:只需将注意力掩码切换回纯 AR 模式。一个模型,在所有部署场景下都能实现通用高效。
最后,英伟达公布了他们的训练配方(从 Ministral3-3B/8B/14B 开始):
1T 个 token 的 AR-only 持续预训练
300B 个 token 的联合 AR + Diffusion 训练
随后进行 SFT 和 VLM 对齐
使用的关键技术:
全局损失平均 + DP-rank 变化掩码
严格因果干净流(防止标签泄漏)
LoRA 增强的起草器以改进自我推测
这项研究指明了未来大模型架构演进的一个方向:不要去刻意挑选自回归还是扩散模型,将它们揉碎在同一个全连接 / 因果注意力切换的 Transformer 体系内或许才是正解。
更令人兴奋的是,论文最后的分析指出,如果未来能够开发出更*的扩散采样器,扩散模式的理论性能上限比现有的自猜测模式还要再高出 76.5%—— 这表明扩散大语言模型依然留有巨大潜能,长文本的「秒级生成」时代可能离我们不远了。
更多细节详见论文。
参考内容:
https://x.com/PavloMolchanov/status/2056799786377039995








