

4 月 27 日,前谷歌 DeepMind *研究员、UCL 教授 David Silver 创办的伦敦 AI 实验室 Ineffable Intelligence 宣布完成 11 亿美元种子轮融资,投后估值 51 亿美元。

这是欧洲迄今*规模种子轮。
Sequoia Capital 和 Lightspeed Venture Partners 共同领投,Nvidia、谷歌、Index、DST Global、英国 Sovereign AI Fund 等参与。
Ineffable 的目标是,做一个从自身经验中发现知识的「superlearner」,继续把强化学习推向 ASI。
这笔钱的特别之处在于阶段。
Ineffable 成立时间只有数月,公开产品、收入、路线图都还有限,但一上来就拿到 51 亿美元估值。
AI 投资已经进入一个新阶段,*研究员的个人信用,正在替代传统意义上的商业验证,成为早期融资最稀缺的抵押物。
这笔巨款,投向了强化学习
过去三年,AI 行业的主线是大语言模型。
更大的语料、更大的集群、更强的推理,几乎构成了所有头部公司的共同剧本。
Silver 选择的是另一条路,强化学习。
强化学习的核心,是让模型在环境里行动,通过反馈修正策略。
围棋、国际象棋、星际争霸这些封闭系统,是它最早打出声量的地方。
Silver 的新公司想把这套方法放大,让系统从基本动作技能一路学到科学、数学、技术层面的突破。
公司公开表述里,Ineffable 的使命是「与超级智能进行*次接触」。
Silver 对大模型路线的分歧也在这里。
大语言模型主要从人类已经写下的文本和代码中学习,能力边界很大程度上受制于人类数据。
Silver 在接受 Wired 采访时把人类数据比作化石燃料,把自我学习比作可再生能源。
这个比喻也解释了为什么投资人愿意给一个没有完全展开商业模式的实验室开出巨额支票。
强化学习
是Scaling Law撞墙后的出路吗?
依赖海量人类数据的传统 Scaling Law 没有失效,但边际收益正在变差。
继续堆参数、堆语料、堆训练算力仍会带来提升,只是高质量人类文本正在变成瓶颈。
Epoch AI 估算,公开高质量人类文本的有效库存约为 300 万亿 Token,按趋势可能最早在今年,最晚在 2032 年,被彻底用光。

https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
也就是说,旧范式这条路还能走,但越来越贵、越来越慢。
纯强化学习确实提供了一条更接近 AGI / ASI 的路线,因为它让模型从「模仿人类文本」转向「通过行动和反馈获得经验」。
AlphaGo Zero 已经证明,在规则清晰、反馈明确的环境里,系统可以不依赖人类棋谱,通过自我对弈达到超人水平。
OpenAI o1 也显示,大规模强化学习和测试时更多思考时间,能显著增强复杂推理能力。
但纯强化学习短期很难单独承担 AGI 路线。
围棋、数学、代码这类任务有明确验证器,强化学习很强;
现实世界的问题没有稳定奖励函数,探索成本高,安全和对齐也更难。
谷歌 DeepMind 的 AlphaProof 更像是现实方向的样板,它结合预训练语言模型、Lean 形式化验证和 AlphaZero 式强化学习,在 IMO 上达到银牌水平。
所以更靠谱的判断是,未来不是大模型预训练和强化学习二选一,而是混合路线。
预训练提供知识和语言底座,强化学习提供行动反馈和目标压力,搜索、验证器、工具调用、仿真环境提供可持续的新经验。
ASI 的关键,是让它能持续试错、验证、发现,并把经验重新变成能力。
大厂人,正在变成新的公司
Ineffable 赶上了一个窗口期。
OpenAI、DeepMind、Anthropic、xAI 等公司在上一轮 AI 竞赛中聚集了最稀缺的人才,也开始向创业市场外溢。
大模型公司继续用巨额算力和产品分发打仗,离开的人带着新路线、新组织和更高上行空间,去拿另一张桌子的筹码。
类似案例正在增多。
TechCrunch 提到,前 DeepMind 研究员 Tim Rocktäschel 创办的 Recursive Superintelligence 曾被报道融资需求可能上探 10 亿美元;
Yann LeCun 离开 Meta AI 负责人岗位后,其参与的 AMI Labs 在 3 月宣布 10.3 亿美元融资。
Ineffable 不是孤例,它是*研究员创业潮里,金额最夸张的其中一笔。
这也解释了英国政府为何入场。
英国 Sovereign AI Fund 和 British Business Bank 参与了这轮融资,后者确认投资 2000 万美元,并称过去 12 个月已做出 9 笔 AI 投资,包括 Wayve、PolyAI 等公司。
对英国来说,DeepMind 被谷歌收购之后,伦敦长期拥有* AI 人才密度,但缺少能留在本土、继续扩张的前沿实验室。
Ineffable 提供了一个重新下注的机会。
*的问题,是从游戏走向世界
Ineffable 的技术叙事很干净,也有可见的风险。
围棋、象棋、星际争霸有规则、边界和可计算的反馈。
真实世界的科学发现、技术发明和社会系统,没有这么稳定的奖励函数。
一个智能体在模拟环境中学到的策略,如何迁移到开放世界,是强化学习走向通用智能绕不开的问题。
Silver 的答案仍然是模拟。
Wired 报道称,他希望把 Agent 放进模拟环境,让它们学习达成目标、相互协作,并观察它们如何对待其他智能体。
这种方法有一个优点,系统行为在更可控的空间里被观察;
也有一个难点,模拟世界必须足够丰富,才可能训练出对真实世界有用的能力。
安全问题也会随之被放大。
一个从经验中学习、持续寻找更优策略的系统,可能会发现人类没有预设过的路径。
强化学习的魅力正在这里,风险也正在这里。
投资人押注的,其实是 Silver 能不能把 AlphaGo 时代那套「从经验中学习」的方法,从游戏房间带到更大的世界。
David Silver 的第二次开局
David Silver 的履历是这个估值的最重要支柱。
UCL 官网资料显示,他曾任 DeepMind 强化学习研究组负责人,主导 AlphaGo,并参与 AlphaZero,后者通过自我对弈在围棋、国际象棋、日本将棋中达到超人类水平。
同时,他还通过国际象棋比赛认识了 DeepMind CEO Demis Hassabis,并成为终生好友。
即便离开了 DeepMind,二人仍保持亲密关系——David Silver 自述「离开只是因为想开辟一条全新的道路」。

https://www.wired.com/story/david-silver-ai-ineffable-intelligence-reinforcement-learning/
ACM 在 2020 年授予他 2019 ACM Prize in Computing,理由是其在计算机博弈上的突破性贡献。
英国*学会资料还列出,他参与过从 Atari、AlphaGo、AlphaZero 到 AlphaStar 的多项关键工作。
其谷歌学术主页及公开资料显示,Silver 的学术引用量已达 30 万,H-index 达到 103,是强化学习领域少数同时拥有学术影响力和产业战绩的人。
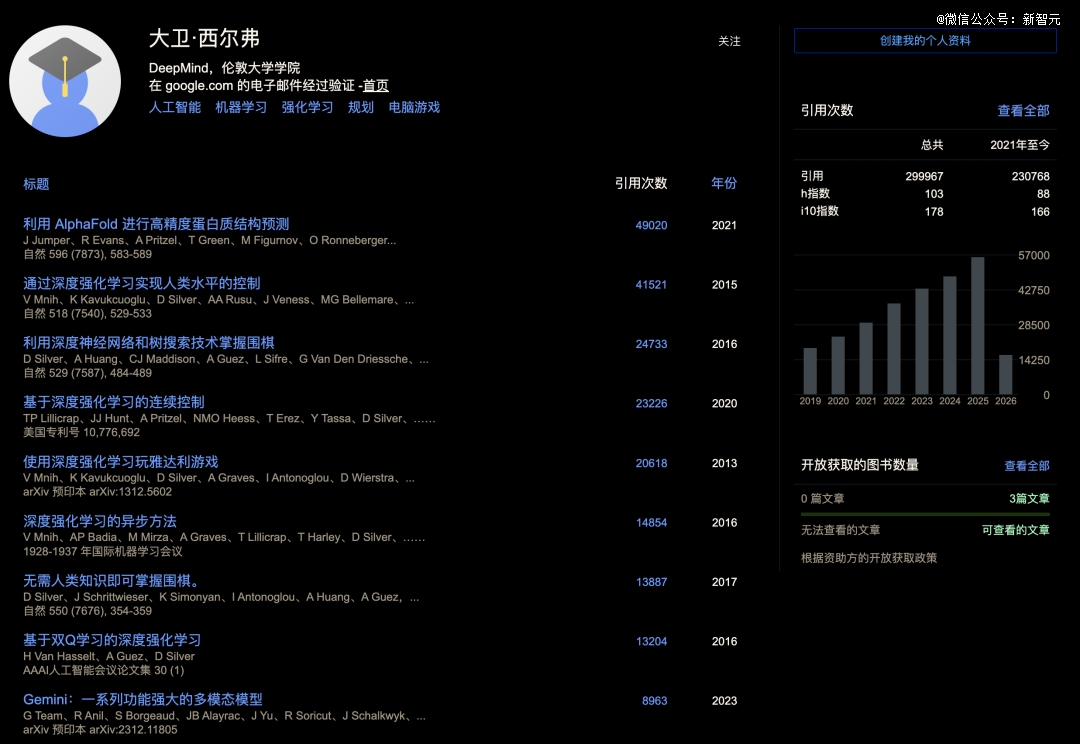
https://scholar.google.com/citations?user=-8DNE4UAAAAJ&hl=zh-CN&oi=ao
Ineffable 的 11 亿美元种子轮,表面是又一个 AI 融资纪录,核心是一次路线投票。
大模型仍在主赛道狂奔,Silver 试图证明,ASI 还可以从行动、反馈和自我经验里长出来。
过去,AlphaGo 让强化学习*次走到大众面前;
现在,Ineffable 想让它从棋盘走向一整套新的智能系统。
参考资料:
https://www.cnbc.com/2026/04/27/deepmind-ineffable-intelligence-record-seed-funding-nvidia-google.html
https://www.wired.com/story/david-silver-ai-ineffable-intelligence-reinforcement-learning/
https://davidstarsilver.wordpress.com/









