先从一次体验经历说起。
打开最新上线的Kimi探索版,你也许会发现AI搜索正在颠覆人们对搜索的传统认知。比如想要调研一下中国科技公司的影响力,可以这样把问题抛给Kimi:2024年《财富》中国科技50强企业中,哪些公司的总部位于北京?
很快,Kimi迅速检索了今年8月发布的《财富》中国科技50强榜单,试图找到这些中国公司中哪些出生于北京。
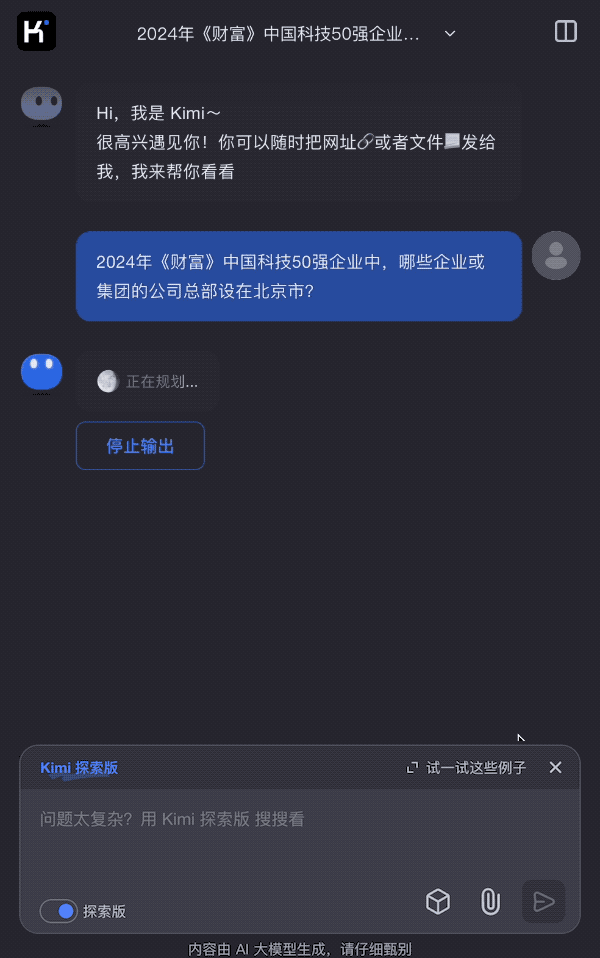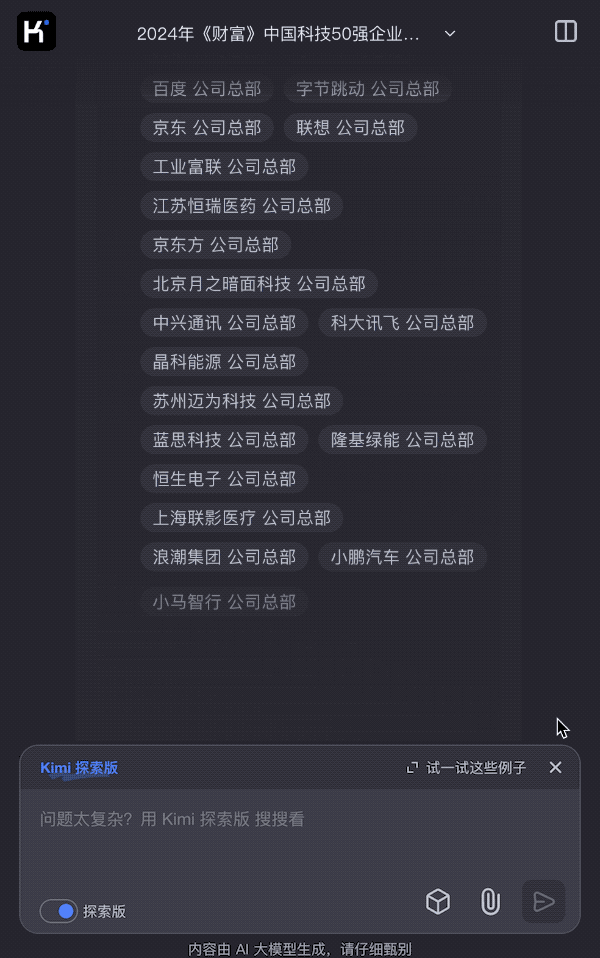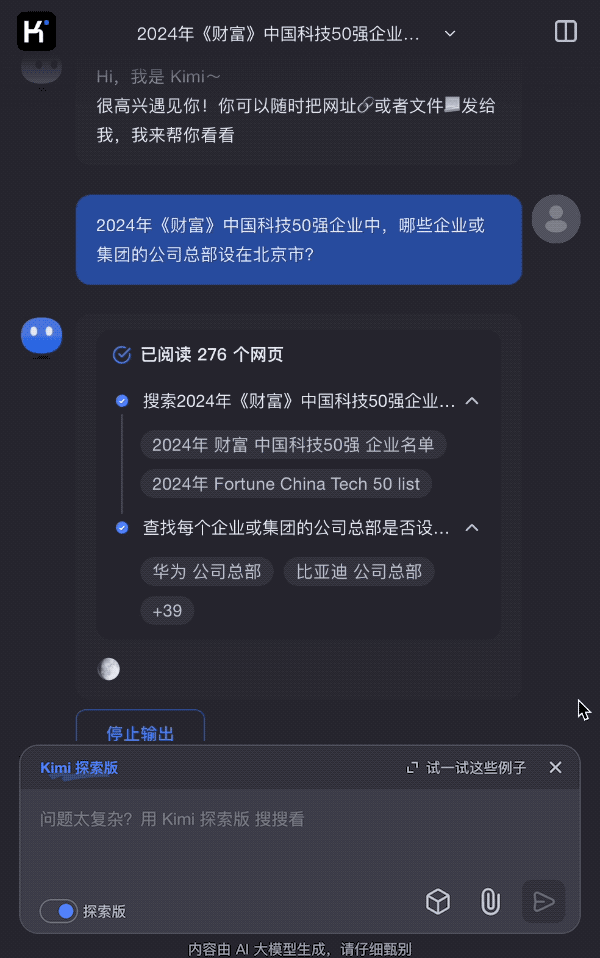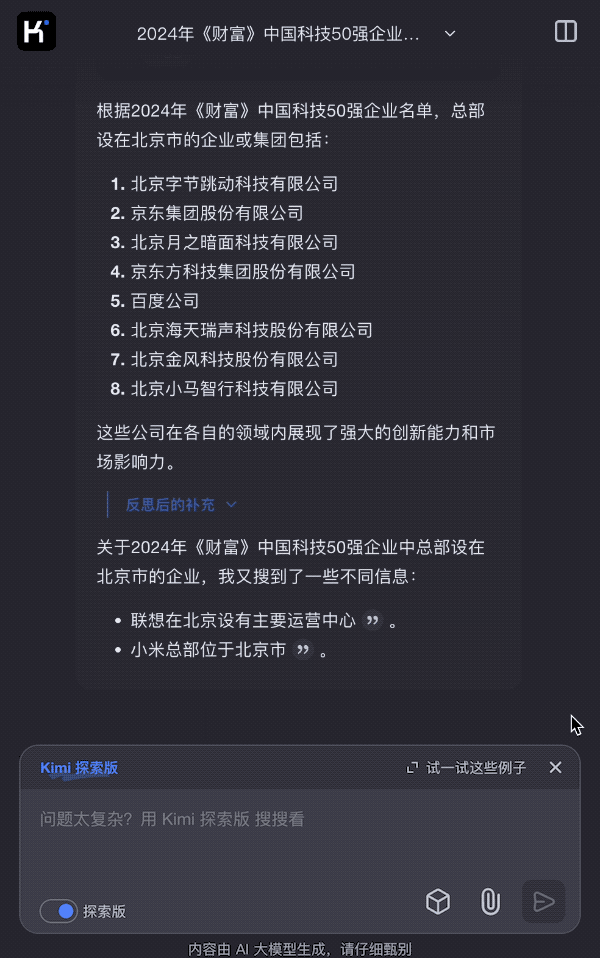
Kimi探索版的回答超出意料,在短短几秒的回答过程中,一共检索了270多个网页内容,对榜单中提到的50家企业总部进行了检索,并给出了答案:包括百度、字节跳动、京东、月之暗面在内的10家公司的总部都位于北京。
继续追问Kimi探索版,《财富》中国50强企业中,哪个企业成立最晚?哪个企业成立最早?
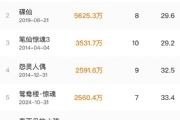
要回答这个成立时间的问题,传统方法依然需要对一个个企业查找资料进行核实,而Kimi探索版很快给出了答案:历史最悠久的是武汉光迅科技股份有限公司,前身是1976年成立的邮电部固体器件研究所,已经有40多年的历史,而最年轻的公司当属月之暗面,成立于2023年。
把同样的问题抛给OpenAI。
检索了5个网页之后,给出的回答是有6家科技50强企业的总部位于北京,遗漏了4家,而对成立时间早晚的问题上,则更是答对了一半,它回答50强公司中成立最早的公司是华为,而成立最晚的是月之暗面。
在Kimi展示的对这个复杂问题的思考过程中,分成三步,先检索了《财富》中国50强的公司名单,然后查找50强企业的总部所在地,最终确定了答案。每一个思考过程,都有多个关键词作为内容支撑,逻辑分析严谨。
在过去,Kimi一直以长文本能力而著称,如今,Kimi探索版的能力上也开始让人刮目相看,在处理日常任务上,Kimi更像人一样思考和应对复杂提问了,它变被动执行搜索为自主思考和分析调研,而用户只负责决策就可以。
未来的大模型搜索会进化成什么样?这可能是影响很多人生活的重要部分,如今Kimi率先给出了自己的范式。
搜得更多,答得才更明白
过去,要解决复杂的问题,检索一次往往是不够的,因为互联网里有海量的信息量,而每个人的问题往往又是独特的,要实现精准匹配,必然要多次搜索才能达到目的。
对于金融市场的观察者来说尤其如此,在不断变化的投资市场环境中,每时每刻的交易环境都是不一样的,这就产生了无数复杂的特定场景,但开启探索版后,Kimi会拆解复杂问题,做更深入的搜索和调研分析,你会发现了一个更大的世界。
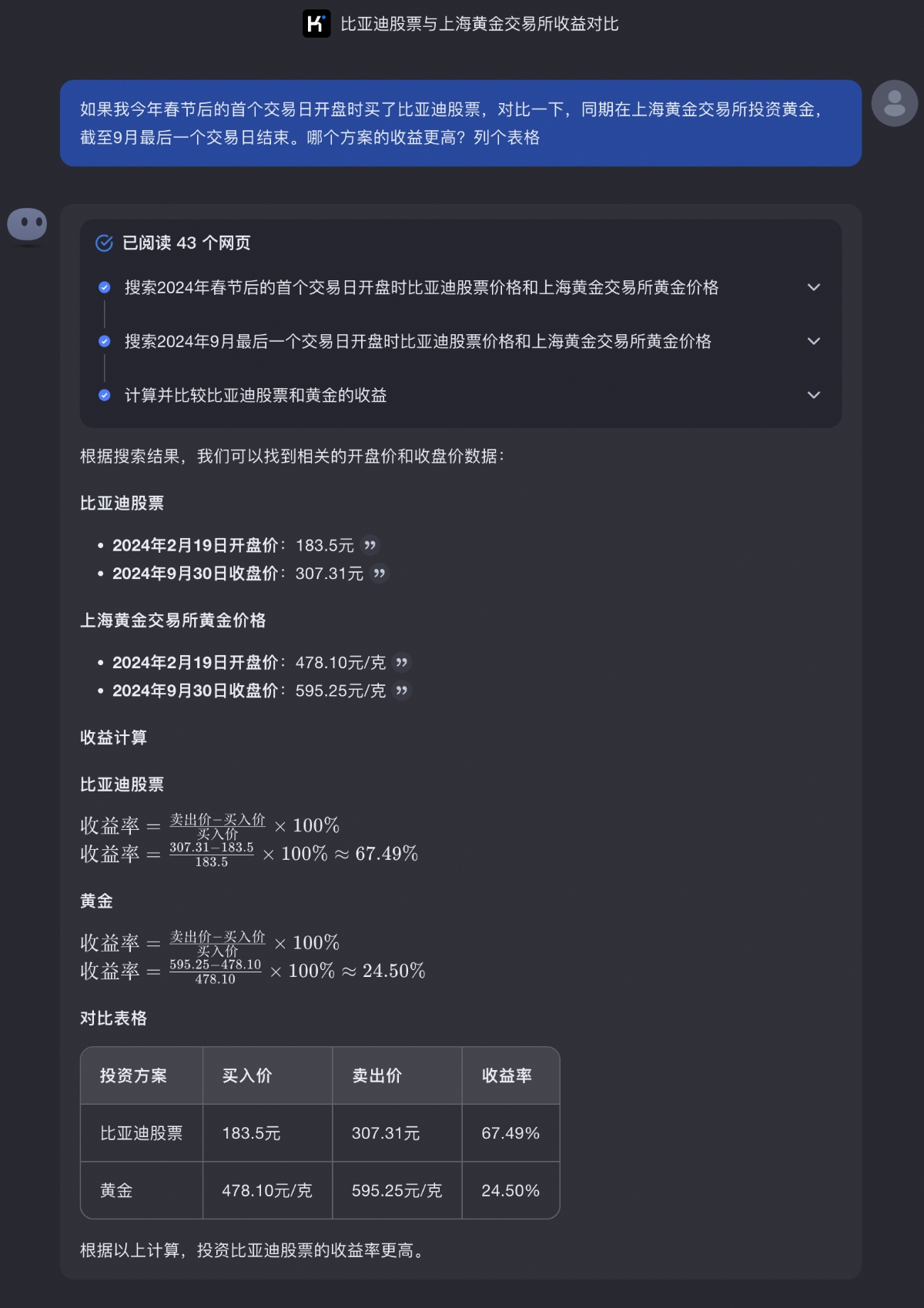
比如,通过复盘对比今年春节后*交易日的历史信息,和9月最后一个交易日的信息,Kimi直接测算出投资比亚迪的收益率远高于投资黄金。
Kimi探索版是如何聪明的做到这一点的?最直接的原因,就是它搜得比其他大模型产品更多,通过拆解复杂问题,把问题拆解成几十个关键词,进而自动阅读几百个网页,穷尽海量的权威信息源。
跟《财富》中国科技50强榜单的问题阅读了270个网页一样,同时给 Kimi和其他大模型产品进行深入搜索一个信息量更大的问题:「OpenAI公司最近发生了什么变化?变化的原因是什么?苹果公司为什么停止投资它?」Kimi分别就这三个连续的问题进行了检索和思考,在短时间内阅读了135个网页后做出回答,而同类的大模型产品阅读的网页数量是12个,搜索的数量级相差十倍。
但搜的越多,就代表回答的质量更高了吗?更深层的原因,还要算 Kimi探索版开始模拟人类的思考方式了。
比如,当用户在Kimi探索版上进行用中文检索,而Kimi判断英文内容可以有更好的结果,就自动切换成英文关键词进行检索,进而生成质量更高的答案,自动规划能力这一点,很多同类AI搜索产品都做不到。
比如通过Kimi探索版提问:「UCLA的人形机器人课题组,2023年有哪些新毕业的博士?」这个答案显然是英文资料更丰富也更权威,于是Kimi探索版自动切换到英文信息中,自动对这个复杂的问题进行拆解,进而给出了7位相关人才的名单,他们中间不少人已经成为人工智能行业的精英人才。
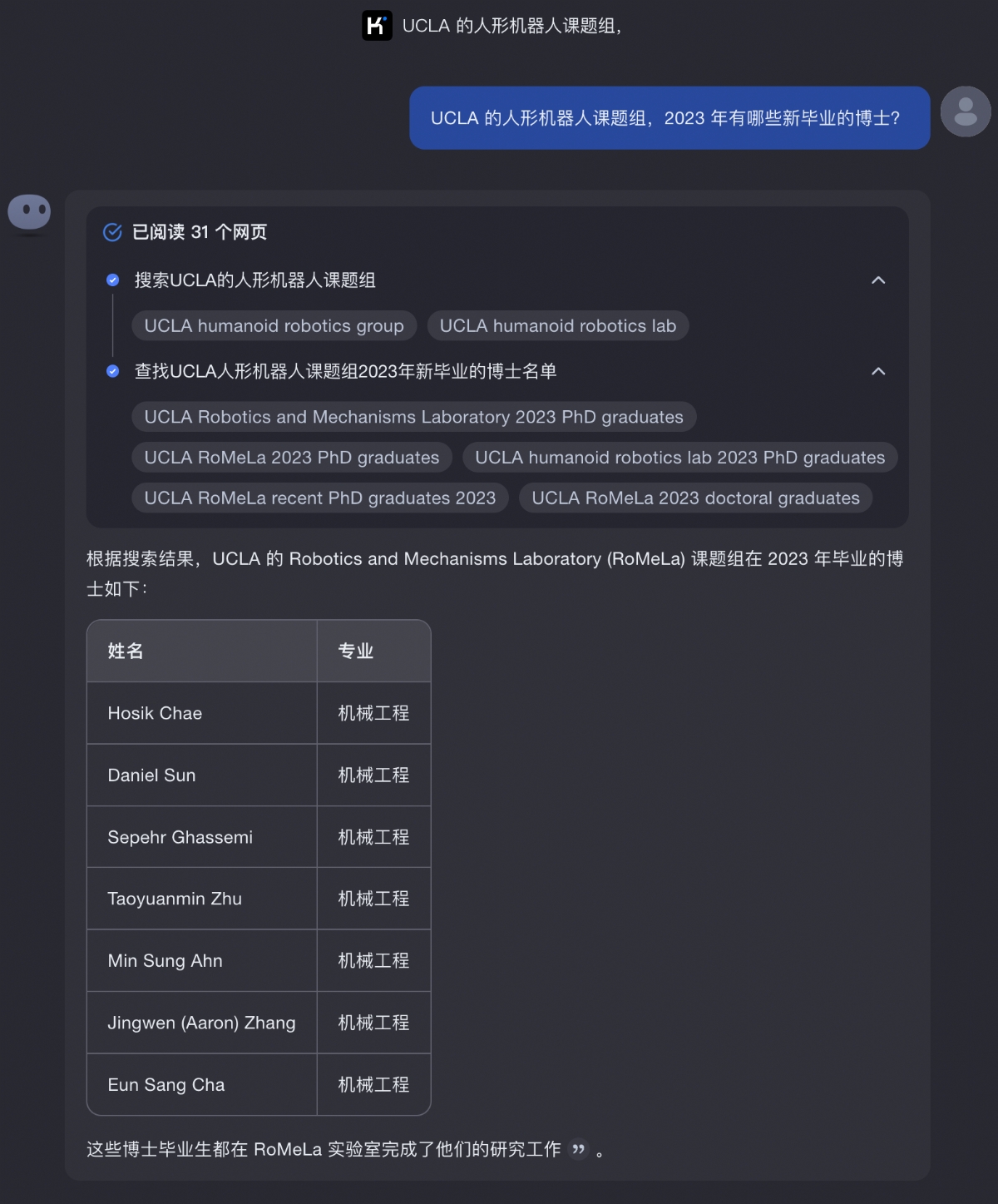
具身人工智能是将人工智能融入到物理实体中的重要方式,而人形机器人是具身人工智能的一种重要表现形式和应用载体,在这个趋势中,UCLA(加利福尼亚大学洛杉矶分校)人形机器人课题组在人工智能行业处于较高的水平。
这个问题都答案和投资收益对比的回答一样,Kimi可以拆解用户的长难提问、自己规划解答思路,并分步骤执行,这展现出了更强的逻辑分析能力。而且这种推理思考过程的结果,非常清晰明了,不再需要用户手动搜索各种信息然后导入 Excel,通过逻辑和分析,Kimi可以直接给出计算结果。
国内其他家大模型厂商也推出过深度搜索功能,但相比较而言,Kimi 的深度搜索搜得更多,回答得更简明扼要,同时具有结构化的特点,这就意味着用户不需要花费大量时间去梳理和理解答案。
此前,Kimi在长文本处理能力上保持*,而现在探索版在搜索数量和质量上的飞跃,让模型输出了更全面、更准确的结果。满足用户基本需求是AI过去的任务,而给用户超出预想需求的高质量答案,可能就是AI不断进化的方向之一。
颠覆AI搜索的不只是技术
在PC电脑上打开搜索引擎,输入关键词,跳出无数条信息,这是过去人们在工作中的常见方式。但对内容有要求的人如何搜索?
过去最常见的方式,就是在搜索引擎中手动打开高级搜索功能,并自定义设置各种关键词、检索时间范围和检索某个网站等,方便查找到更精确的信息内容,但这也意味着找到专业内容需要的时间更久。
AI时代的搜索会怎么做?打开大模型对话框,输入一个完整的问题,大模型会自动给你生成一个完整回答。但对复杂的问题呢?
要想让大模型回答的更精准,就需要将一个复杂问题变成多个简单问题,我们需要仔细的问,再分别借助AI获取信息和知识,最终辅助决策,问得越仔细,往往回答就越准确。
也就是说,精准的搜索对用户来说永远都有价值,技术的进化带来的进步之一,就是用户与AI之间可以进行一种直观而精准的双向对话,再也没有了过去搜索广告的烦恼。
事实上,从纵向的时间发展角度看,大模型给AI搜索带来的变化是肉眼可见的直观,而从横向的竞争角度看,大模型给搜索带来的变革还远没有停止, Kimi探索版把AI搜索带入了新阶段,率先颠覆了传统搜索无法像人一样思考。
Kimi探索版中还有一个重要的进步,就是Kimi回答结束时,如果 Kimi认为自己的搜索结果还可以更全面、更有价值,会进行反思和补充,这意味Kimi可以思考自己的回答质量、自我修正、自我迭代,这就很像人对思考方式,因为人类能够自我反思和提升。
比如,把「清朝天地会起源的时间和地点」这一有历史争议的话题抛给Kimi,它的回答会先写明「康熙十三年」和「乾隆二十六年」这两个史学主流观点,地点都位于福建漳州,但这一问题在史学界仍有历史争议,所以Kimi最后的回答中还是给出了另外的参考答案,分别是「雍正十二年」和「乾隆三十二年」。
兼听则明,复杂的问题往往意味着不止一种答案,尤其是连特定的专家学者们都无法明确答案的时候,更丰富的答案才能给人更科学的决策空间。
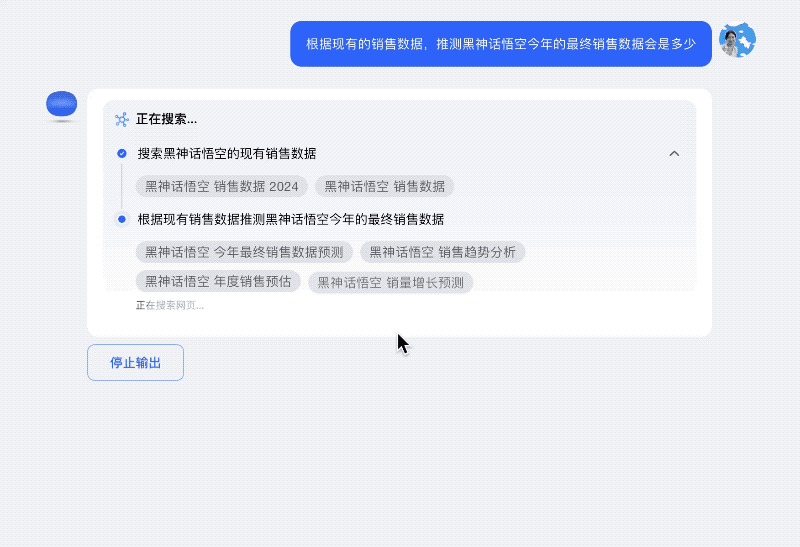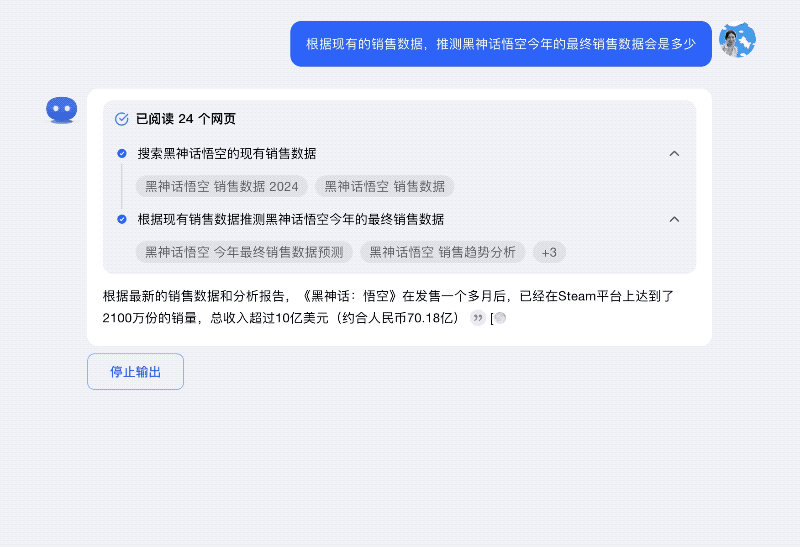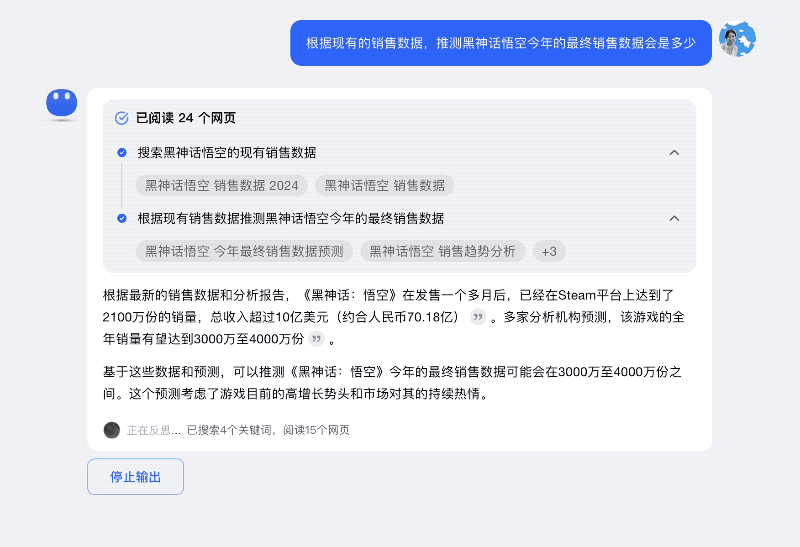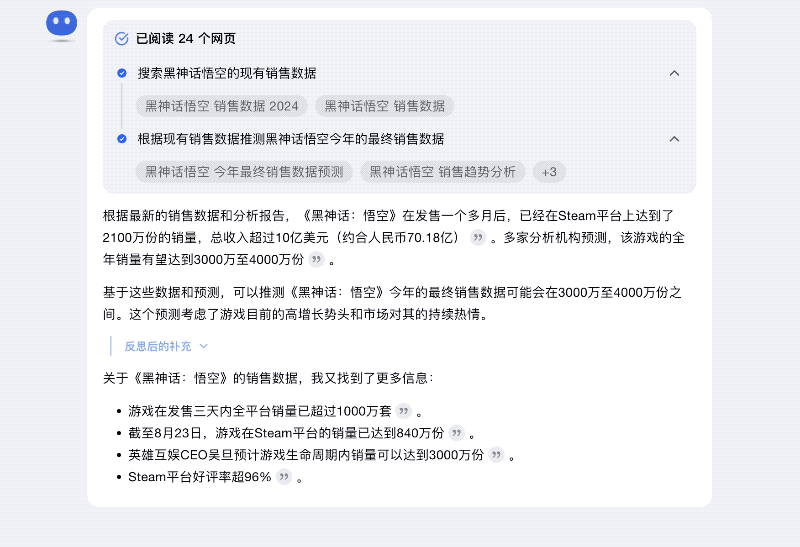
再比如对「黑悟空今年最终销售数据是多少」这一未知问题的预测性回答,Kimi探索版在穷尽海量的权威信息源之后,给出3000万 -4000万份之间的回答,然后又做了反思,把Steam平台好评率等一系列关键信息作为了补充,这都帮助用户做出更科学的判断。
究其本质,Kimi探索版更像人一样的反思回答,一方面意味着回答得不够全面,需要做出补充,另外一方面则证明,初答结果和其他结果有冲突,需要给用户另外一个角度信息作为参考。
写在最后
回到今天的主题。
之所以说Kimi探索版颠覆了搜索,就在于它一方面抬高了AI搜索的上限,穷尽海量的权威信息源和即时反思补充结果,意味着Kimi搜不到的,人工搜索或其他产品也搜不到。
而另外一方面是降低了AI搜索的门槛,把找到专业内容的搜索时间和难度降低了,通过像人类思考一样自动规划回答策略,AI开始逐步辅助我们解决复杂的搜索和调研问题,帮助用户获得更准确的答案。
AI适应的场景很多,它可以化身老师、健身教练或是程序员,总之它是提升生产力的全能助手,可以完成不同特定场景下的日常工作任务。尤其是对知识工作者和大学生们来说,Kimi无疑将成为一个更好用的调研和生产力工具。
根据 Similarweb 数据,从今年以来,在代表生产力的PC网页端,Kimi的月访问量从140多万增长到2400多万,增长了16.7倍。目前 Kimi的PC网页版,也是国内AI助手产品中*月访问量稳定超过 2000万。
纵观大模型公司的发展,模型能力的强弱,使用价格的高低,模型落地的简易与否,这三个维度已经成为大模型厂商们在各自差异化的进阶之路上的赛点。尤其是落地的可靠程度,意味着是否能够为大多数用户所使用,以及能否为大多数用户带来更好的使用习惯和更高的频次。
因为真正颠覆AI搜索的,不只是AI技术本身,而是AI技术不断满足人们日益进化的实际需求。
随着Kimi探索版带来的AI搜索能力,Kimi的智商、逻辑分析能力进一步上升,更多生活中常见的问题都将获得更可靠和简易的回答,这让Kimi在长本文能力之后,进一步扩大了自己的差异化能力;但是,要进化成智能体走向更多人的广阔生活,还有一段很长的路要走。
序幕已然拉开。
作者 I 赵至