

从学术界到企业界,思想者先行
去年,时代杂志公布了AI领域*影响力的100人。四大板块中,入选年龄*的是76岁的杰夫·辛顿。
人工智能简史在被神经网络重塑之前,辛顿在符号主义大行其道的80年代,一头扎进神经网络默默耕耘。
符号主义基于规则,模仿的是人心,生成的是一个白盒系统,可解释,可触达,确定性更高,但神经网络主张模仿人脑,生成的是一个黑盒系统。
可当时有一大难点,就是多层神经网络中存在的隐藏层和计算量问题,在一开始就劝退了一大批精英,所以别说发展,在那个年代,神经网络流派的生存都是问题。
但是,如果在辛顿的履历里,找一件对AI贡献*的事,并不是他让神经网络成功度过生存危机的误差反向传播算法,也不是他后来以受限玻尔兹曼机为基础,进一步演化出来的深度信念网络,而是他用了四十年的时间,坚持不懈,开创了一个新的分支:机器学习。也为后来所有的研究者,守着这扇通往新世界的大门。

2006年深度学习正式提出,辛顿已然著作等身,但关于AI究竟要走哪条路线的偏见,依然根深蒂固,多伦多大学计算机学系,当时就流传着对新生的一句忠告:不要去辛顿的实验室,那儿没前途。
当然,这句话没有劝退真正眼光毒辣的学生,比如伊利亚。
早在2003年,大家还对神经网络流派嗤之以鼻的时候,本科二年级的伊利亚,就带着惊人的直觉和更深入的研究,敲开了辛顿办公室的大门,也代表着他对这一路线,早就深信不疑。
2004年,辛顿在辗转多个大学工作后,终于在加拿大高等研究院拿到了50万美元的经费,这可能是当时*还在支持神经网络研究的机构。
50万美元,对于科研来说确实有些微薄,但是却足够让辛顿结束漂泊的访学生涯,并安顿下来,召开了一场研讨会。
当时辛顿的半个学生杨立昆,和另一位徒孙约书亚·本吉奥,也加入了他的队伍。所以早在20年前的2003年,“深度学习三巨头”(杨立昆、约书亚、辛顿),就已经坐上了同一张牌桌。

但是,只有算法上的创新还远远不够,横在三巨头眼前难以逾越的还有两座高山:算力和数据。
2012年,64岁的辛顿去谷歌做暑期实习生,这次入职,是应吴恩达邀请,接手谷歌猫项目。
如果只是识别一只普通的猫,传统的计算机视觉自然不在话下,可是猫有可能长得千奇百怪。
虽然当时谷歌在动用了16000个CPU后,识别准确率已经高达74.8%,辛顿却仍然认为:他们的神经网络用错了。
几个月后,辛顿和自己的两个学生:Ilya Sutskever、Alex Krizhevsky,带着新算法AlexNet,以及两块英伟达GTX580显卡,参加了计算机视觉领域最受关注的世界赛事,ImageNet,并以84%的识别准确率,拿下冠军。也是这一年后,曾经只拿来玩游戏的GPU,凭借*的并行计算能力,来了个180度大翻身。
神来一笔的两块GPU,算力这座大山被凿开了口子。那么数据问题又该如何解决?

实际上,这场图像识别比赛(ImageNet)本身就是一块高质量的数据试金石,比赛的主办者,就是后来被称为AI教母的李飞飞。早在2000年,她就意识到,卡住神经网络脖子的,可能不在于算法的精度,而在于缺少大规模、高精度的数据。
于是,ImageNet数据集的构想产生了。
最开始她用WordNet中的名词作为索引,来筛选和分类图片,但只依靠本科生,这项任务大概90年后才能完成。
就在所有人都陷入僵局的时候,马逊土耳其机器人这个网站步入研究者的视野,也没用什么新鲜方法,亚马逊找来十万名“人类智能”,一招人海战术,在短短两年时间内,就标注了超过300万张图像。

2010年,*届图片识别大赛举办。2012年,数据库里的图片,就已经扩充到了1500万张。
也是这一年,数据集的概念出现,逐渐成为未来所有人工智能的核心养料。
所以当李飞飞看到了辛顿的AlexNet获奖,立刻就意识到,历史即将改写。她在颁奖当天,买了最后一班飞机票,亲自赶到现场给辛顿团队颁奖。
多年以来压在深度学习身上的三座大山:算法、算力和数据,在这一年被集中解决,第三次人工智能浪潮也从沉淀中苏醒,时刻准备爆发。

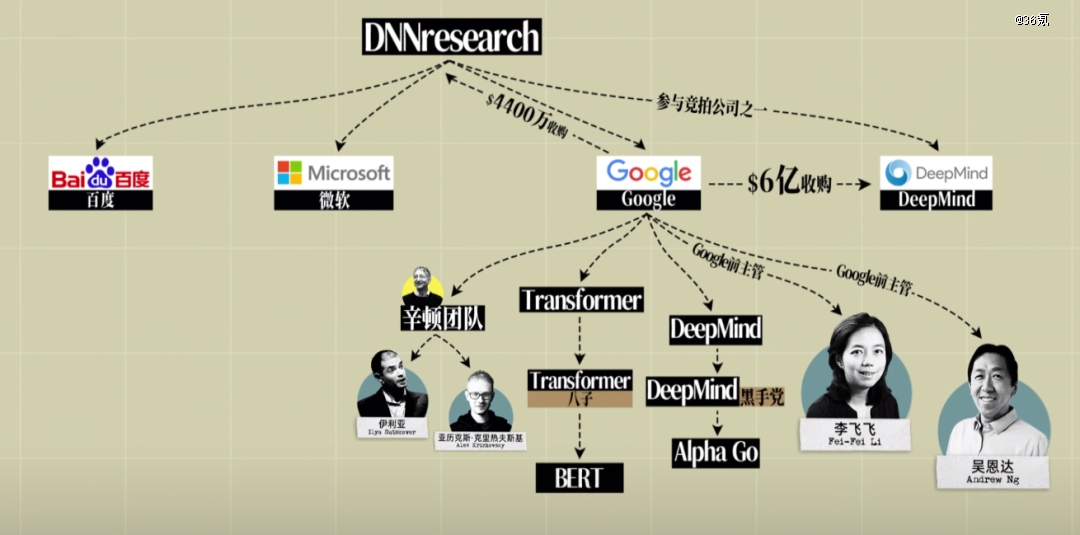
拿下大赛冠军几个月后,辛顿三人的“空壳公司”DNNresearch,也在四位买家(谷歌、DeepMind、微软、百度)的角逐中,被谷歌以4400万美元的价格收入囊中。
这次竞拍也让深度学习技术,逐渐走入资本视野,从学术界主导,正式进入企业主导的时代。
值得一提的是,参与竞拍辛顿的四家公司中,还有一家小公司,DeepMind。当时的DeepMind自己都在四处筹钱,创始人哈萨比斯竟还想和大厂掰掰手腕,买下DNNresearch,可见他非同一般的眼光和野心。
但AI的吞金能力远超大家想象,所有AI初创公司都面临巨大的融资压力,杨立昆当年关于这一点,没有说错。果然两年后,DeepMind也被谷歌用6亿美元拿下。后来的故事,大家也有所耳闻了。
2015年,谷歌DeepMind团队推出了Alpha Go,第37手,漂亮的“神之一手”,也一举成名。
但是,距离人工智能真正爆发,还缺少一个关键契机。
2017年,一篇终结了CNN(卷积神经网络)和RNN(循环神经网络)的论文问世,(《Attention is all your need》https://arxiv.org/pdf/1706.03762),八位作者都来自谷歌。
回过头来看,注意力机制,作为后来主导大语言模型的根基,被谷歌这家,全世界*的注意力商人发布,好像也在情理之中。
第二年,谷歌就发布了BERT模型。大模型的狂潮,也正式拉开了帷幕。
所以不难看出,2012年的那一次实习、一场比赛、一局竞拍,让深度学习走出学术界,正式进入商业市场里摸爬滚打。由于深度学习长期无人问津,领域里的*学者也屈指可数,
学术界就干脆以超级学者为核心,形成了几大AI高校研究阵地。
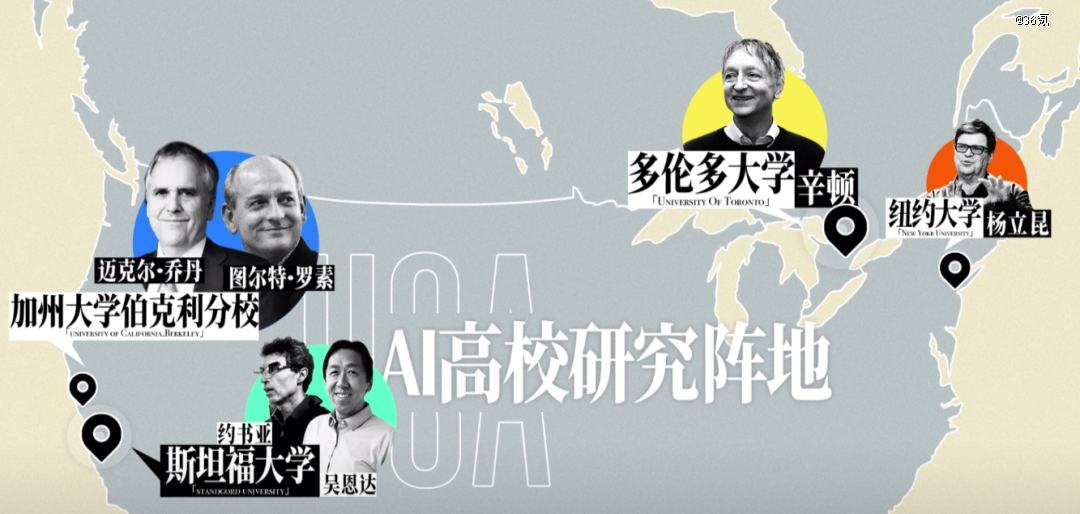
这些稀缺的大佬同时化身*猎头,带着自己的学生,从实验室,走进了AI领域的前沿公司。只不过,这一次他们不再是玩家,而是换了个身份,继续这场游戏。
AI创业者,谁笑到最后?
新的牌局上,谷歌可以说开局就有*同花顺的底气,毕竟接连拿下辛顿团队、DeepMind,
之后又连续发布Alpha Go、Transformer、BERT。手握最强AI资源的谷歌,是当时AI领域*的头号玩家,很长一段时间,风头无两。
但为什么后来坐上了王位的,会是当时连一间像样办公室都没有的Open AI呢?
谷歌输在了哪儿?
谷歌作为一家号称只招收精英的科技巨头,成立了20多年,去年裁员后仍有18万员工(Alphabet)。
不缺资金、不缺人,也不缺资源,但与之对应的,是精力分散、过分谨慎,以及团队磨合的问题,船大难掉头。
相比于Open AI产品的一目了然(Open AI官网),谷歌的产品开发可以用眼花缭乱来形容。这个网站上:https://killedbygoogle.com/ 记录了被谷歌砍掉的295个项目(包含AI与非AI)。

谷歌一直在各种不同的技术路线上广撒网,却并没有带来与之对应的收获。
技术开发什么最重要?选对路线,并持续加码。这几轮翻牌,在GPT模型上(BERT线)持续加码的玩家,只有一个,就是Open AI。
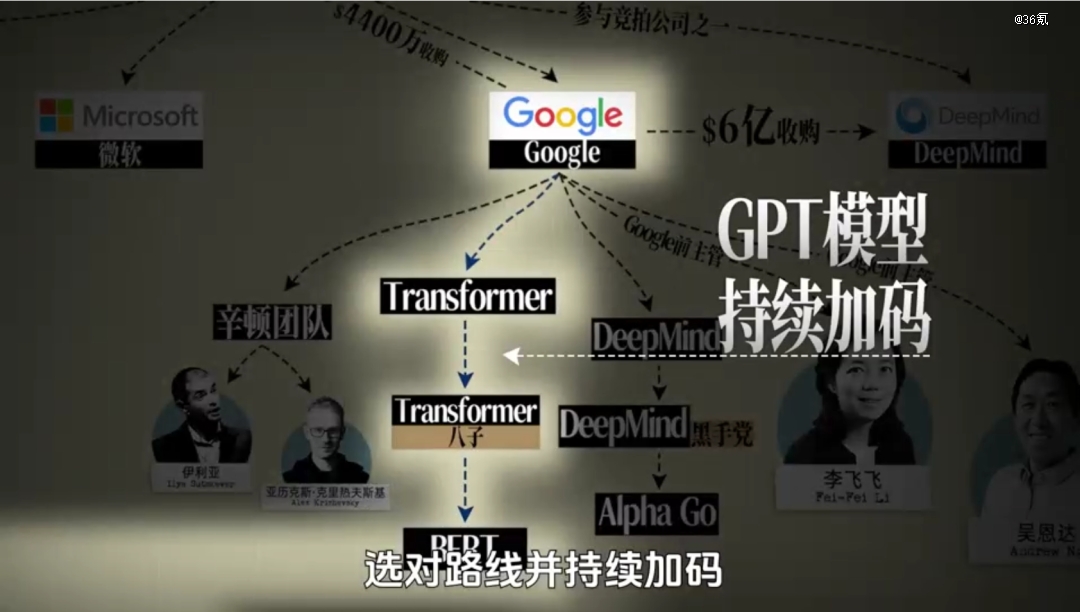
谷歌后知后觉,在GPT-3出现后才下定决心All in,但此时它的身份已经从领头羊,变成了追赶者。不仅如此,由于手上的筹码太多,谷歌还面临另一个难题,就是优等生陷阱。
由于Bard机器人发布后频频翻车,而市场对大公司的小失误又极其敏感,直接导致股价跌了8%,损失高达1000亿美元,也留下了非常严重的后遗症,就是内部越来越倾向保守,论文一篇篇地发,但产品落地不声不响。
好在去年3月,谷歌终于把Google Brain和Google DeepMind合并,哈萨比斯统一领导,全力开发Gemini系列,但是内部磨合问题,必然会消耗一定的时间和精力。
哈萨比斯当初卖身谷歌,是因为只有10%的时间搞研发,其它时间都在找钱,现在倒是不缺钱了,但管理问题同样令人头大。
原先DeepMind实验室的核心成员陆续离开,创立或者加入新的公司,当初的Transformer八子也是一样选择。
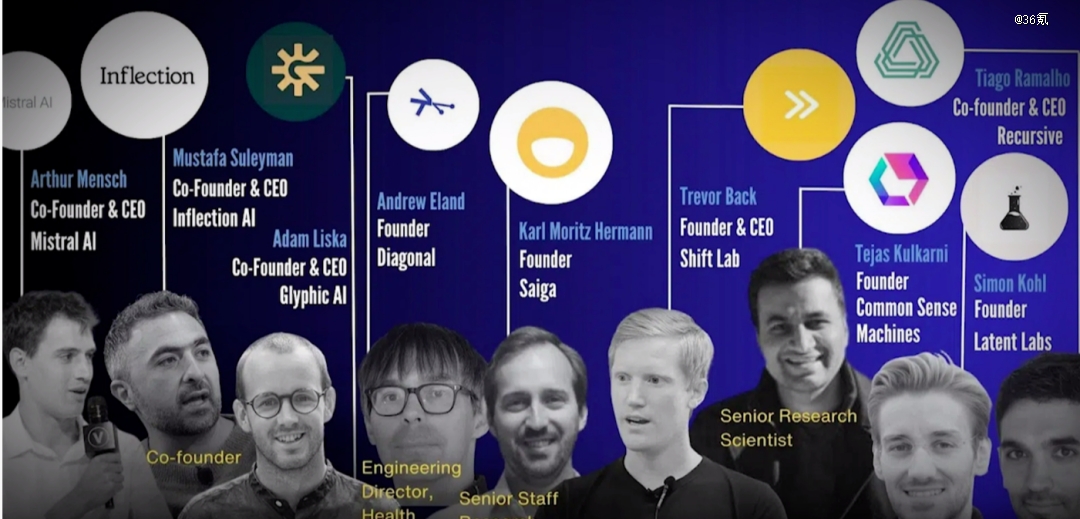
尽管谷歌已经开始亡羊补牢地召回人才,但是相较于山姆·奥特曼的气势如虹,钱,已经不是吸引*人才的主要因素。
微软成*赢家?Open AI能赢到最后吗?
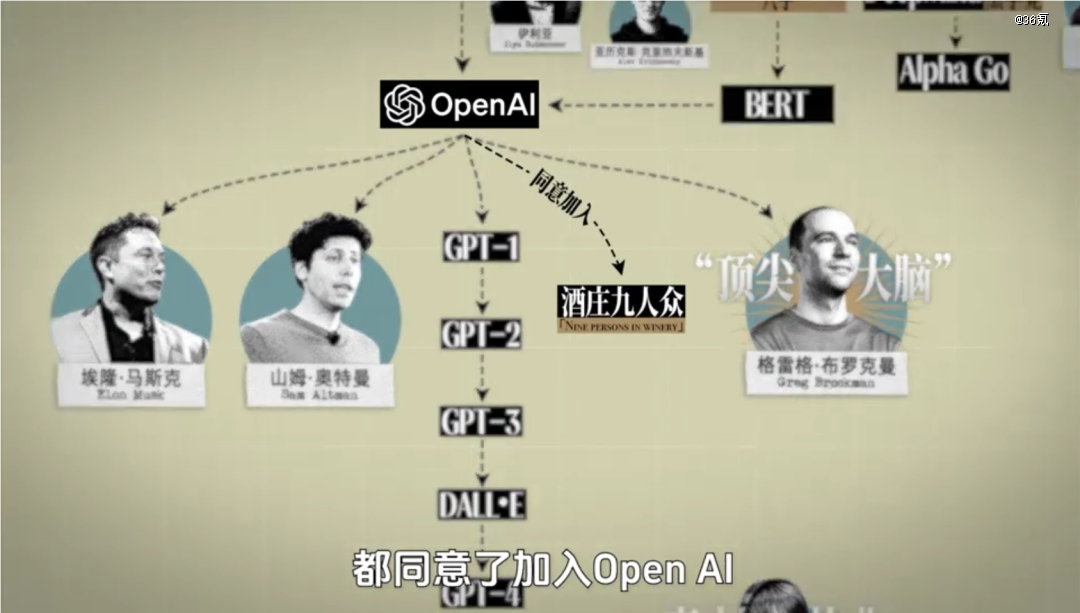
*的大脑,才是致胜的关键。而从一开始就践行这一点的,就是开头那场晚宴上迟到的年轻人,布罗克曼。
他那场他还不是主角的晚宴结束后,*时间就给当时AI行业的*人物们一一打了电话,
可惜的是,辛顿已经去了谷歌,杨立昆也被Facebook收入麾下,只剩下致力于学术界的约书亚·本吉奥。
本吉奥也是神助攻,直接给他提供了一份年轻研究者名单,虽然当时AI界的聚光灯都在大佬们身上,但布罗克曼依然租了辆大巴车,把名单上的研究人员,带到一个与世隔绝的葡萄酒庄,度过了一整个周末。
三周之后,因为布罗克曼在人才招揽上超高的执行力,再加上马斯克+山姆·奥特曼的人格魅力,可以说OpenAI从一开始就拥有双重Buff,而且那时候的他们,言辞里充满对技术的浪漫主义情怀,一种奥本海默式的理想气质蔓延在整个酒庄。
最终,10个人里有9个,都同意了加入Open AI,当然也包括拒绝了谷歌两到三倍薪酬诱惑的伊利亚。就这样,在一众巨头的抢人大战中,OpenAI成功拿下了大批现如今的*学术大牛。
AI公司起步,人不在多,必然得精。
有了这些人在前,Open AI的人才军火库也形成了自己独特的筛选标准,一不重学历,二不重资历。相比遍地博士的大型研究机构,ChatGPT研发团队里的本、硕、博人数雨露均沾,当然其中绝大部分,也都是*名校的学位。
但他们仍然认为只要能解决问题,甚至高中毕业的也能上。

虽然如今OpenAI的创始团队已经七零八落,布罗克曼本人也宣布了长期休假,但Open AI在人才上的先发优势依然不容小觑。
看到这里可能有人会有疑问,Facebook怎么缺席了?
去年5月,华盛顿白宫,美国副总统哈里斯拉着这几家AI巨头开了个闭门会(谷歌、微软、OpenAI和Anthropic),却没出现Facebook的身影。
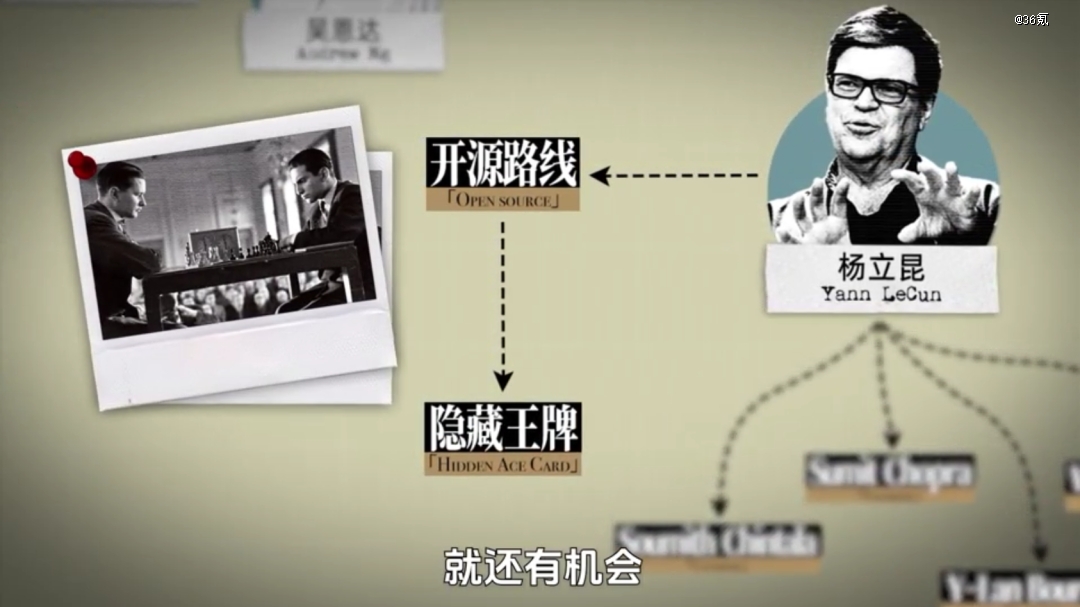
要知道当年DeepMind卖身,Facebook也是出价者之一,这家公司不仅成功将GAN改造成了工具,推出了PyTorch,也拿下了大将杨立昆。
但问题就是,在GPT风起云涌的时候,Facebook还有一堆自己的麻烦没处理好,VR和元宇宙业务出师不利,社交媒体业务陷入监管危机。直到去年,才推出了LLaMA。
但相比迟到,Facebook有一点倒是值得肯定,不仅在商业路径受阻时,还持续向AI团队提供足够的资金支持,也始终没忘当年对杨立昆的承诺,坚持开源路线。
因为Facebook坚信,AI牌局里,开源是隐藏的王牌。只要自己一直在牌桌上,就还有机会。
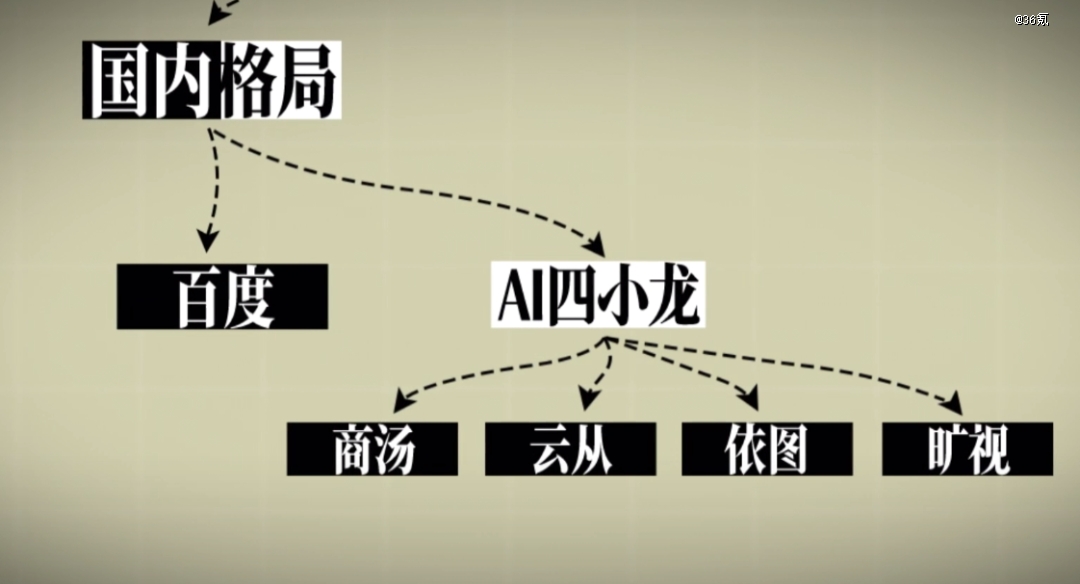
而当初那场决定了AI未来走向的关键竞拍中,还有一个熟悉的身影,百度。而且中国实际上是当时最早抛出橄榄枝的一方。
但那个时候,中国公司还陷在技术研发和投资回报哪个更重要的问题中,无法自拔。最直接的体现就是主打计算机视觉的AI四小龙(商汤、云从、依图、旷视),一直在估值和股价的质疑里浮浮沉沉。直到,GPT出现后,事情才有了转机。
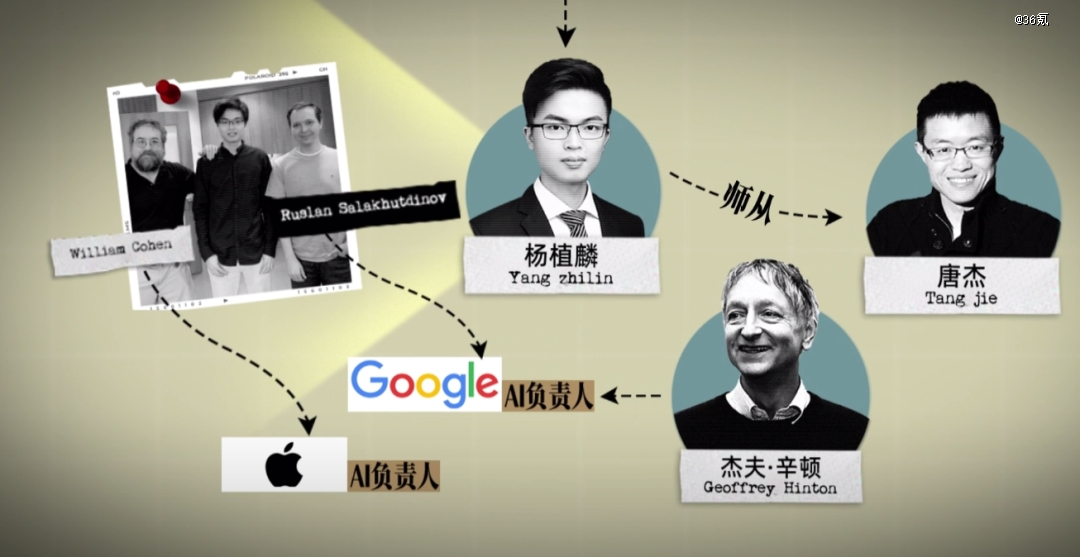
清华系逐渐进入大众视野,如今的中国AI大模型五虎(智谱AI、百川智能、月之暗面、零一万物和MiniMax),三家出身清华,这一批AI创业者身上标签也更明显,那就是像极了OpenAI:
年轻、根正苗红的技术背景,以及更成熟的AI落地思路。
代表人物,就是月之暗面的创始人杨植麟,师从智谱AI首席科学家唐杰,博士生导师分别是谷歌和苹果的AI负责人。
AI草台班子里的角儿
从辛顿到杨植麟,从硅谷到清华,从学术界到企业界,在主题为AI的这场牌局中,我们也能一窥其中的玩家风格。
就像杨立昆最早质疑的一样,年轻,没经验,但他没料到的是,正是这样的玩家,才有更强的学术延伸性,伟大确实很难被计划。也是因此,才会出现创业公司和大厂同台竞技的画面。
同样也是阿里这类巨头,多方押注创业公司的原因(上述五虎,阿里全部都投了)。
模型公司绑定巨头的玩法,已经在美国走通,(微软+OpenAI、亚马逊+Anthropic、特斯拉+xAI),可一旦出现突破性进展,最直接的可能,就是脱离大厂,重新洗牌,提前预定新一代大厂。
所以AI这场牌局,从辛顿30年坐冷板凳开始,就已经注定了会是一场长期游戏,只有*想象力的玩家,才有胜出的可能。

比如Open AI成立之初,就只有两个目标:一是训练一台机器,在《魔兽争霸》里打败*玩家;二是打造一只五指机械手,用来还原魔方,这只机械手还出现在了布罗克曼的婚礼上。
未来,或许很难再有第二个Open AI,但草台班子的戏台上,总有耀眼的角儿能杀出重围,也正是新奇和有趣,才造就了出色和有戏,这或许才是新技术行业,应有的题中之义。










