

在人工智能计算架构的布局中,CPU与加速芯片协同工作的模式已成为一种典型的AI部署方案。CPU扮演基础算力的提供者角色,而加速芯片则负责提升计算性能,助力算法高效执行。常见的AI加速芯片按其技术路径,可划分为GPU、FPGA和ASIC三大类别。
在这场竞争中,GPU凭借其独特的优势成为主流的AI芯片。那么,GPU是如何在众多选项中脱颖而出的呢?展望AI的未来,GPU是否仍是*解呢?
01 GPU如何制胜当下?
AI与GPU之间存在着密切的关系。
强大的并行计算能力
AI大模型指的是规模庞大的深度学习模型,它们需要处理海量的数据和进行复杂的计算。GPU的核心优势就在于其强大的并行计算能力。与传统的CPU相比,GPU能够同时处理多个任务,特别适合处理大规模数据集和复杂计算任务。在深度学习等需要大量并行计算的领域,GPU展现出了无可比拟的优势。
完善的生态系统
其次,为了便于开发者充分利用GPU的计算能力,各大厂商提供了丰富的软件库、框架和工具。例如,英伟达的CUDA平台就为开发者提供了丰富的工具和库,使得AI应用的开发和部署变得相对容易。这使得GPU在需要快速迭代和适应新算法的场景中更具竞争力。
通用性好
GPU最初是用于图形渲染的,但随着时间的推移,它的应用领域逐渐扩大。如今,GPU不仅在图形处理中发挥着核心作用,还广泛应用于深度学习、大数据分析等领域。这种通用性使得GPU能够满足多种应用需求,而ASIC和FPGA等专用芯片则局限于特定场景。
有人将GPU比作一把通用的多功能厨具,适用于各种烹饪需求。因此在AI应用的大多数情况下,GPU都被视为*选择。相应的,功能多而广的同时往往伴随着特定领域不够“精细”,
接下来看一下,相较其他类型的加速芯片,GPU需要面临哪些掣肘?
02 GPU也存在它的掣肘
文首提到,常见的AI加速芯片根据其技术路径,可以划分为GPU、FPGA和ASIC三大类别。
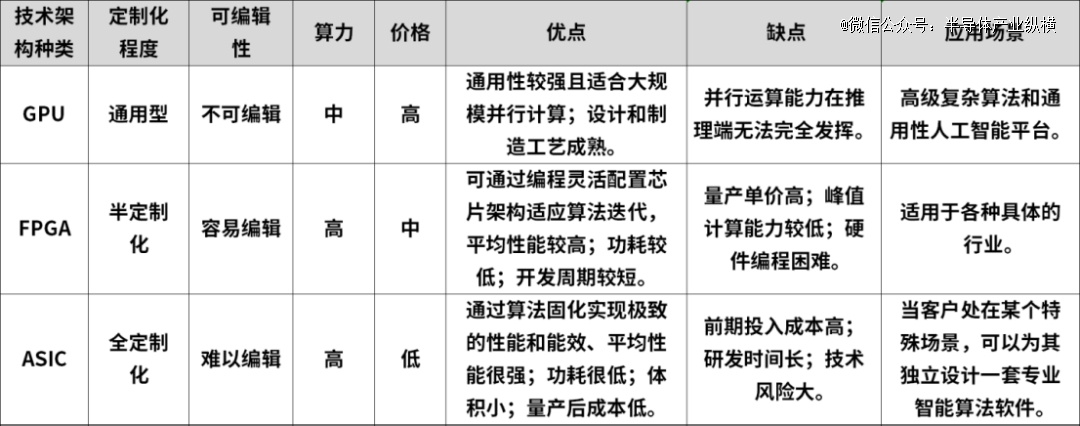
FPGA(Field Programmable Gate Array,现场可编程门阵列),是一种半定制芯片。用户可以根据自身的需求进行重复编程。FPGA 的优点是既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点,对芯片硬件层可以灵活编译,功耗小于 CPU、GPU;缺点是硬件编程语言较难,开发门槛较高,芯片成本、价格较高。FPGA 比 GPU、CPU 更快是因为其具有定制化的结构。
ASIC(Application Specific Integrated Circuit特定用途集成电路)根据产品的需求进行特定设计和制造的集成电路,其定制程度相比于 GPU 和 FPGA 更高。ASIC 算力水平一般高于GPU、FPGA,但初始投入大,专业性强缩减了其通用性,算法一旦改变,计算能力会大幅下降,需要重新定制。
再看GPU相较于这两类芯片存在哪些劣势。
*点,GPU的单位成本理论性能低于FPGA、ASIC。
从成本角度看,GPU、FPGA、ASIC 三种硬件从左到右,从软件到硬件,通用性逐渐降低、越专用,可定制化逐渐提高,相应的设计、开发成本逐渐提高,但是单位成本理论性能越高。举个例子,对于还在实验室阶段的经典算法或深度学习算法,使用GPU 做软件方面的探索就很合适;对于已经逐渐成为标准的技术,适合使用 FPGA 做硬件加速部署;对于已经成为标准的计算任务,则直接推出专用芯片ASIC。
从公司的角度来说,同样对于大批量数据的计算任务,同等内存大小、同等算力的成熟 GPU 和 FPGA 的部署成本相近。 如果公司的业务逻辑经常变化,比如1-2年就要变化一次,那么GPU 的开发成本低、部署速度快;如果公司业务5年左右才变化一次,FPGA 开发成本虽高、但芯片本身的成本相比 GPU 低很多。
第二点,GPU的运算速度要逊色于FPGA和ASIC。
FPGA、ASIC和GPU内都有大量的计算单元,因此它们的计算能力都很强。在进行神经网络运算的时候,三者的速度会比CPU快很多。但是GPU由于架构固定,硬件原生支持的指令也就固定了,而FPGA和ASIC则是可编程的,其可编程性是关键,因为它让软件与终端应用公司能够提供与其竞争对手不同的解决方案,并且能够灵活地针对自己所用的算法修改电路。
因此在很多场景的应用中,FPGA和ASIC的运算速度要大大优于GPU。
具体到场景应用,GPU 浮点运算能力很强,适合高精度的神经网络计算;FPGA 并不擅长浮点运算,但是对于网络数据包、视频流可以做到很强的流水线处理;ASIC 则根据成本有几乎无限的算力,取决于硬件设计者。
第三点,GPU的功耗远远大于FPGA和ASIC。
再看功耗。GPU的功耗,是出了名的高,单片可以达到250W,甚至450W(RTX4090)。而FPGA一般只有30~50W。这主要是因为内存读取。GPU的内存接口(GDDR5、HBM、HBM2)带宽极高,大约是FPGA传统DDR接口的4-5倍。但就芯片本身来说,读取DRAM所消耗的能量,是SRAM的100倍以上。GPU频繁读取DRAM的处理,产生了极高的功耗。另外,FPGA的工作主频(500MHz以下)比CPU、GPU(1~3GHz)低,也会使得自身功耗更低。
再看ASIC,ASIC的性能和功耗优化是针对特定应用进行的,因此在特定任务上性能更高、功耗更低。由于设计是针对特定功能的,ASIC在执行效率和能效比方面通常优于FPGA。
举个例子,在智能驾驶这样的领域,环境感知、物体识别等深度学习应用要求计算响应方面必须更快的同时,功耗也不能过高,否则就会对智能汽车的续航里程造成较大影响。
第四点,GPU时延高于FPGA、ASIC。FPGA相对于GPU具有更低的延迟。GPU通常需要将不同的训练样本,划分成固定大小的“Batch(批次)”,为了*化达到并行性,需要将数个Batch都集齐,再统一进行处理。
FPGA的架构,是无批次的。每处理完成一个数据包,就能马上输出,时延更有优势。ASIC也是实现极低延迟的另一种技术。在针对特定任务进行优化后,ASIC通常能够实现比FPGA更低的延迟,因为它可以消除FPGA中可能存在的额外编程和配置开销。
既如此,为什么GPU还会成为现下AI计算的大热门呢?
在当前的市场环境下,由于各大厂商对于成本和功耗的要求尚未达到严苛的程度,加之英伟达在GPU领域的长期投入和积累,使得GPU成为了当前最适合大模型应用的硬件产品。尽管FPGA和ASIC在理论上具有潜在的优势,但它们的开发过程相对复杂,目前在实际应用中仍面临诸多挑战,难以广泛普及。因此,众多厂商纷纷选择GPU作为解决方案,这也导致了第五点潜在问题的浮现。
第五点,高端GPU的产能问题也令人焦虑。
OpenAI 首席科学家 IlyaSutskever 表示,GPU 就是新时代的比特币。在算力激增的背景下,英伟达的B系列和H系列 GPU 成为“硬通货”。
然而,虽然该系列需求十分旺盛,但考虑到HBM和CoWos供需紧张,以及台积电先进产能吃紧的情况,GPU产能实在无法跟得上需求。
要知道“巧妇难为无米之炊”,在这种形势下,科技巨头们需要更加灵活地应对市场变化,囤积更多的GPU产品或者寻找替代方案。
如今已经有不少厂商开始另辟蹊径,在GPU之外的道路上探索并研发更为专业化、精细化的计算设备和解决方案。那么未来的AI加速芯片又将如何发展?
03 科技巨头另辟蹊径
在当下这个科技发展极快、算法以月为单位更迭的大数据时代,GPU 确实适合更多人;但是一旦未来的商业需求固定下来,FPGA 甚至 ASIC 则会成为更好的底层计算设备。
各芯片龙头和科技龙头也早已开始研发生产专用于深度学习、DNN 的运算芯片或基于 FPGA 架构的半定制芯片,代表产品有 Google 研发的张量计算处理器 TPU、 Intel 旗下的 Altera Stratix V FPGA等。
Google押注定制化的 ASIC 芯片:TPU
Google 早在 2013 年就秘密研发专注 AI机器学习算法芯片,并用于云计算数据中心,取代英伟达 GPU。
这款TPU自研芯片2016年公开,为深度学习模型执行大规模矩阵运算,如自然语言处理、计算机视觉和推荐系统模型。Google 其实在 2020 年的资料中心便建构 AI 芯片 TPU v4,直到 2023 年 4 月才首次公开细节。
值得注意的是TPU是一种定制化的 ASIC 芯片,它由谷歌从头设计,并专门用于机器学习工作负载。
2023年12月6日,谷歌官宣了全新的多模态大模型Gemini,包含了三个版本,根据谷歌的基准测试结果,其中的Gemini Ultra版本在许多测试中都表现出了“*进的性能”,甚至在大部分测试中完全击败了OpenAI的GPT-4。
而在Gemini出尽了风头的同时,谷歌还丢出了另一个重磅炸弹——全新的自研芯片TPU v5p,它也是迄今为止功能最强大的TPU。根据官方提供的数据,每个TPU v5p pod在三维环形拓扑结构中,通过最高带宽的芯片间互联(ICI),以4800 Gbps/chip的速度将8960个芯片组合在一起,与TPU v4相比,TPU v5p的FLOPS和高带宽内存(HBM)分别提高了2倍和3倍。
随后在今年5月,谷歌又宣布了第六代数据中心 AI 芯片 Tensor 处理器单元--Trillium,并表示将于今年晚些时候推出交付。谷歌表示,第六代Trillium芯片的计算性能比TPU v5e芯片提高4.7倍,能效比v5e高出67%。这款芯片旨在为从大模型中生成文本和其他内容的技术提供动力。谷歌还表示,第六代Trillium芯片将在今年年底可供其云客户使用。
据悉,英伟达在AI芯片市场的市占高达80%左右,其余20%的绝大部分由各种版本的谷歌TPU所控制。谷歌自身不出售芯片,而是通过其云计算平台租用访问权限。
微软:推出基于Arm架构的通用型芯片Cobalt、ASIC芯片Maia 100
2023年11月,微软在Ignite技术大会上发布了*自家研发的AI芯片Azure Maia 100,以及应用于云端软件服务的芯片Azure Cobalt。两款芯片将由台积电代工,采用5nm制程技术。
据悉,英伟达的高端产品一颗有时可卖到3万到4万美元,用于ChatGPT的芯片被认为大概就需要有1万颗,这对AI公司是个庞大成本。有大量AI芯片需求的科技大厂极力寻求可替代的供应来源,微软选择自行研发,便是希望增强ChatGPT等生成式AI产品的性能,同时降低成本。
Cobalt是基于Arm架构的通用型芯片,具有128个核心,Maia 100是一款专为 Azure 云服务和 AI 工作负载设计的 ASIC 芯片,用于云端训练和推理的,晶体管数量达到1050亿个。这两款芯片将导入微软Azure数据中心,支持OpenAI、Copilot等服务。
负责Azure芯片部门的副总裁Rani Borkar表示,微软已开始用Bing和Office AI产品测试Maia 100芯片,微软主要AI合作伙伴、ChatGPT开发商OpenAI,也在进行测试中。有市场评论认为,微软 AI 芯片立项的时机很巧,正好在微软、OpenAI 等公司培养的大型语言模型已经开始腾飞之际。
不过,微软并不认为自己的 AI 芯片可以广泛替代英伟达的产品。有分析认为,微软的这一努力如果成功的话,也有可能帮助它在未来与英伟达的谈判中更具优势。
据悉,微软有望在即将到来的Build技术大会上发布一系列云端软硬件技术新进展。而备受关注的是,微软将向Azure用户开放其自研的AI芯片Cobalt 100的使用权限。
英特尔押注FPGA芯片
英特尔表示,早期的人工智能工作负载,比如图像识别,很大程度上依赖于并行性能。因为 GPU 是专门针对视频和显卡设计的,因此,将其应用于机器学习和深度学习变得很普遍。GPU 在并行处理方面表现出色,并行执行大量计算操作。换句话说,如果必须多次快速执行同一工作负载,它们可以实现令人难以置信的速度提高。
但是,在 GPU 上运行人工智能是存在局限的。GPU 不能够提供与 ASIC 相媲美的性能,后者是一种针对给定的深度学习工作负载专门构建的芯片。
而 FPGA 则能够借助集成的人工智能提供硬件定制,并且可以通过编程提供与 GPU 或 ASIC 相类似的工作方式。FPGA 可重新编程、重新配置的性质使其格外适合应用于飞速演变的人工智能领域,这样,设计人员就能够快速测试算法,并将产品加速推向市场。
英特尔FPGA 家族包括英特尔 Cyclone 10 GX FPGA、英特尔 Arria 10 GX FPGA 和英特尔Stratix 10 GX FPGA等。这些产品具备 I/O 灵活性、低功耗(或每次推理的能耗)和低时延,本就可在 AI 推理上带来优势。这些优势在三个全新的英特尔 FPGA 和片上系统家族的产品中又得到了补充,使得 AI 推理性能进一步获得了显著提升。这三个家族分别是英特尔 Stratix 10 NX FPGA 以及英特尔 Agilex FPGA 家族的新成员:英特尔 Agilex D 系列 FPGA,和代号为“Sundance Mesa”的全新英特尔 Agilex 设备家族。这些英特尔FPGA 和 SoC 家族包含专门面向张量数学运算优化的专用 DSP 模块,为加速 AI 计算奠定了基础。
今年3月,芯片巨头英特尔宣布成立全新独立运营的FPGA公司——Altera。英特尔在2015年6月以167亿美元收购Altera,被收购时Altera是全球第二大FPGA公司,九年后英特尔决定让FPGA业务独立运营,再次选择以Altera命名。
NPU(Neural Processing Unit)也是一种参考人体神经突触的 ASIC 芯片。随着深度学习神经网络的兴起,CPU和 GPU 逐渐难以满足深度学习的需要,专门用于神经网络深度学习的处理器NPU应运而生。NPU 采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。区别于 CPU 以及 GPU 所遵循的冯诺依曼架构,NPU 参考人体的神经突触结构,将存储与运算结为一体。
Arm 近日宣布推出 Ethos-U85 NPU。作为 Arm 面向边缘 AI 的第三代 NPU 产品,Ethos-U85 适用于工业自动化和视频监控等场景,在性能方面提升了四倍。Ethos-U85 较上一代产品在能效方面拥有 20% 的提升,还可在常用神经网络上实现 85% 的利用率。其在设计上适合基于 Arm Cortex-M / A 处理器内核的系统,能接受较高的内存延迟。
协同、训练推理融合、具备统一生态的系列化智能芯片产品和平台化基础系统软件。寒武纪产品广泛应用于服务器厂商和产业公司,面向互联网、金融、交通、能源、电力和制造等。
此外,OpenAI也正在探索自研AI芯片,同时开始评估潜在收购目标。AWS自研AI芯片阵容包括推理芯片Inferentia和训练芯片Trainium。 电动汽车制造商特斯拉也积极参与AI加速器芯片的开发。特斯拉主要围绕自动驾驶需求,迄今为止推出了两款AI芯片:全自动驾驶(FSD)芯片和Dojo D1芯片。
去年5月Meta披露了旗下数据中心项目支持AI工作的细节,提到已经打造一款定制芯片,简称MTIA,用于加快生成式AI模型的训练。这是Meta首次推出AI定制芯片。Meta称,MTIA是加快AI训练和推理工作负载的芯片“家族”的一分子。此外,Meta介绍,MTIA采用开源芯片架构RISC-V,它的功耗仅有25瓦,远低于英伟达等主流芯片厂商的产品功耗。值得注意的是,今年4月,Meta公布了自主研发芯片MTIA的最新版本。分析指出,Meta的目标是降低对英伟达等芯片厂商的依赖。








