

2024年5月,互联网大模型率先迎来“618”。
制图:周鑫雨
5月20日晚间,阿里云用一条“明天,又有事发生”的公众号贴文,放出了降价风声——21日早上10:00,通义千问模型家族宣布降价,开源和闭源均有不同程度的限免和降价政策。
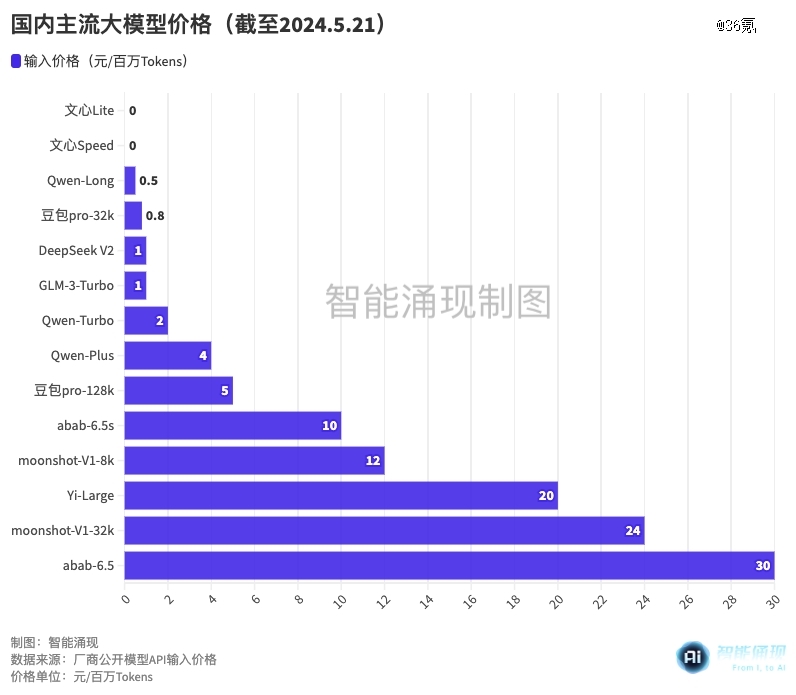
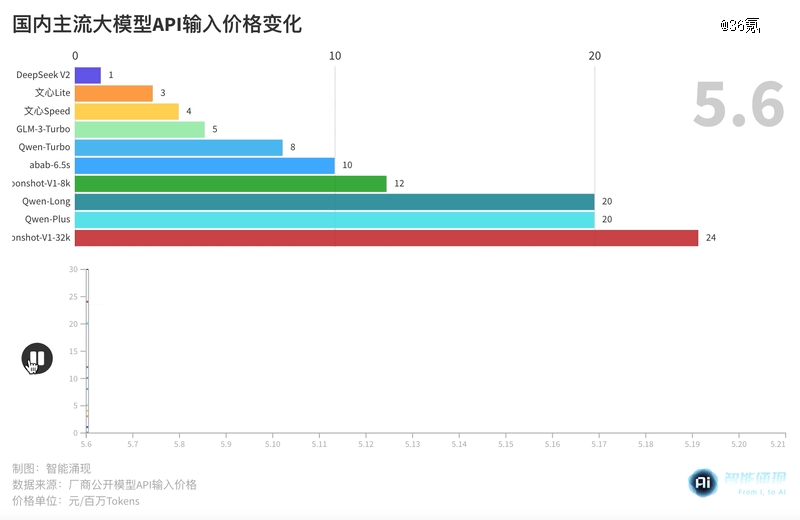
其中,阿里云商业化的主力大模型Qwen-Long,输入价格降幅甚至达到了97%,价格从原有的20元/百万Tokens,直降为0.5元/百万Tokens。
这一价格,以0.0003元/千Tokens的微妙优势,击穿了5月15日字节刚刚公布的“豆包大模型”的输入地板价:0.8元/百万Tokens。
然而,低价*刚易位4小时,百度就前来“掀翻了价格地板”——文心一言两款模型ERNIE Speed和ERNIE Lite,直接宣布“免费”。
在2023年,模型的降价仍然遵从着训练效率优化和规模效应的自然趋势。
2023年11月,百度的大模型平台“文心千帆”,曾经调整了相同汉字数量对应的Token数,变相将模型的价格降低了20%。与之对应地,是文心大模型的推理成本降低到了原来的1%。
但2024年的模型价格战,开打得几乎毫无预兆。
价格断崖的开端,是一条名为“DeepSeek V2”的鲶鱼。DeepSeek的出品机构“深度求索”的背后,是坐拥过万张英伟达A100 GPU的量化基金——幻方量化。
5月6日,深度求索发布了DeepSeek大模型的新版本V2。作为模型领域的“黑马”,2360亿参数规模的DeepSeek V2,模型性能处于国产*梯队,定价也没有什么包袱,支持32k上下文的模型API定价仅1元/百万Tokens(计算)、2元/百万Tokens(推理),是彼时百度文心4.0-8k推理价格(120元/Tokens)的1/60。
制图:周鑫雨
此后,大模型独角兽智谱AI率先加入了价格战。5月11日,智谱AI旗下的GLM-3-Turbo,价格从5元/百万Tokens,降低到了1元/Tokens。
“黑马”搅局模型定价的另一面,则是更具性价比的小模型被重提。
不少从业者对智能涌现表示,小模型的潜力还没被完全发掘,完全可以通过数据治理、效率优化等策略,以小博大,这对于下游客户而言也是更有性价比的选择。
2024年4月22日,Meta发布的开源模型Llama-3,就以70B的“小参数”,和超过20倍参数量的GPT-4在性能上掰手腕。紧接着,微软又发布了3.8B的模型Phi-3 mini,号称性能对标GPT-3.5,还能在苹果A16芯片上流畅运行。
对于下游客户而言,昂贵的大模型不够“香了”。大厂大模型的集体降价,也是在顺应市场选择。
不过,即便是价格砸穿地板,大厂们依然有利可图。大模型只是门面,大厂的渔翁之意,是通过模型卖自己的云服务。
以拥有自己的计算集群的幻方量化为例,据SemiAnalysis计算,在其算力服务力利用率最高的情况下,DeepSeek每台服务器每小时收益可达35.4美元,毛利率在70%以上。
但对于被迫卷入价格战的小厂商和初创公司而言,营收的压力将会更大。2024年5月21日,零一万物CEO李开复就直言,不参与价格战,最新模型Yi-Large的API定价仍为20元/百万Tokens。
未来,小厂们唯有在单点或多点性能上和竞争对手们拉开差距,才能分到蛋糕。











