

国内大模型还在如火如荼,但国外的一些生成式AI先锋们,正在上演一场生死出逃大戏。
3月下旬,美国生成式 AI 明星公司Stability AI突然宣布公司 CEO莫斯塔克(Emad Mostaque)辞职。莫斯塔克也在社媒平台推特(X)上表示,自己离职后将致力于去中心化AI。至于什么是去中心化AI,生产式AI怎么就过时了,就语焉不详了。
这当然都是借口。*的原因,就是Stability AI没钱了。
据福布斯报道,Stability曾经是人工智能最热门的初创公司之一,但几个月来,它的资金已经耗尽,莫斯塔克也无法获得足够的额外资金。它拖欠了亚马逊的付款,亚马逊AWS曾一度威胁要撤销对未付账单的访问权。此外,还拖欠了谷歌和CoreWeave的云服务费用。
据福布斯援引的Stability内部财务报告,Stability AI 2023年总预计成本为1.53亿美元,但预计收入仅为1100万美元。
入不敷出,自然要垮,这不稀罕。
但稀罕的是,按照Stability AI的表现,如果是在中国,在这个大模型投资火热还没有退去的时候,一亿多美元的前期亏损,不管是前期投资方还是寻找后续轮次融资,几家投资机构合作的话也并不是负担不起,只要公司能够证明自己未来的潜力。比如国内就有不少大模型企业获得数亿美元以上级别的投资,且获得投资时并未实现盈利。
至少在中国,一些大模型独角兽企业由于正处于创业初期,尽管已经收获订单,但走向盈利依然需要时日。前期一两年亏损,本就是大模型行业的常态。所以,仅仅是亏了一年就要崩,未必是Stability AI不行的真正原因。
那么,为什么在美国通货膨胀、资本并不缺美元的当下,Stability AI要不行了呢?没钱付费云服务了,投资人不投了,创始人内讧了,客户不买了,被巨头取代了,芯片断供了……大模型企业,真的是惨到有那么多种死法在等着。
那么,梳理中外各类大模型企业,大模型企业,到底需要面对多少种“坑”?到底什么样的大模型才能卷出来?大模型跑出来,要面对哪些两难选择、必经宿命?
未必死于技术不行一定死于市场不行
Stability AI的技术真的不行吗?要知道,其文生图大模型产品Stable Diffusion,与OpenAI的DALL-E以及Midjourney,被行业公认为文生图领域的三巨头。Stable Diffusion 在2022 年8 月推出,以开源底层代码的形式在HuggingFace/Github 公开发布,因此也为最多人使用。
据Everypixel统计,从1826 年*张照片拍摄到 1975 年,胶卷相机用了近150 年才拍摄约150 亿张照片。而从2022年2月到2023年8月,仅用一年半时间,使用文生图算法就已经生成了超过 150 亿张图片,其中大约 80%的图像(即 125.9 亿张)是用Stable Diffusion创建的。
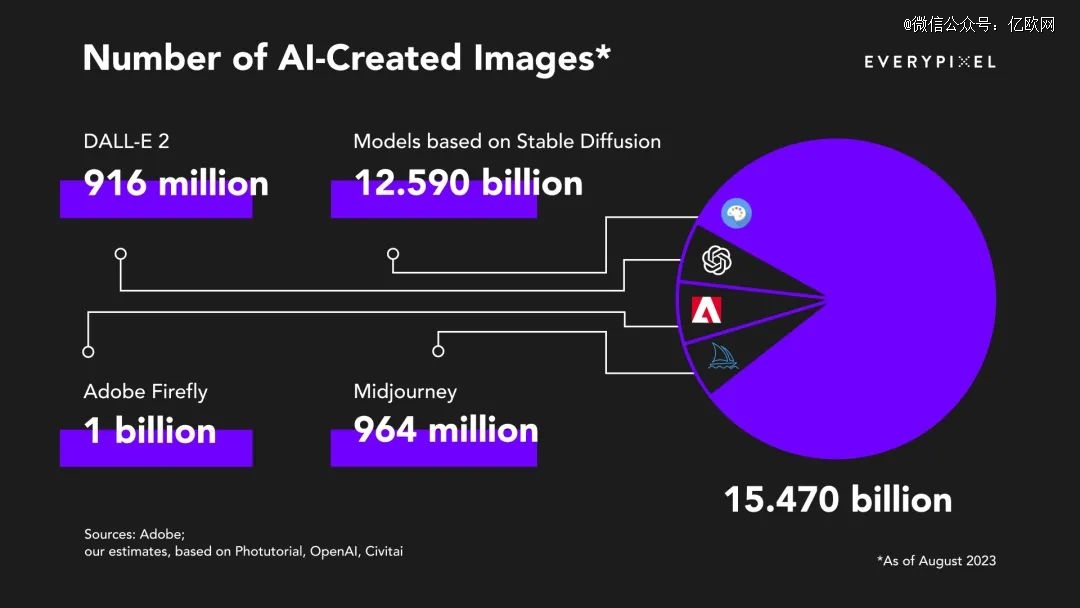
而且,因为Stable Diffusion是开源模型,使用该模型生成的图片不限于 Stability AI 官方平台,所以官方平台之外生成的图片量可能还会更多。由此也可见Stable Diffusion在行业中的地位。
但即使如此,技术行,市场不行,投资人也不会认可。
2023年才挣了1100万美元,而OpenAI却赚得盆满钵满(当然算力支出也与日俱增)。
据英国金融时报援引知情人士透露,OpenAI的2023年营收可能已经达到20亿美元(月收入乘以12的衡量标准)。知情人士人士补充称,越来越多企业客户采用生成式AI工具来提高工作效率,到2025年这一数字有望翻倍。
不过,这就够了吗?
并不是没有人怀疑。
红杉资本在近期举行的AI Ascent 2024上就表示,2023年,各家AI公司在英伟达GPU上已经大手大脚花去500亿美元,但由此产生的收入才有30亿美元。
如果抛开OpenAI的20亿美元年收入,那按照红杉资本的30亿美元估计,其他数百上千家大小大模型企业的总营收只有10亿美元,明显规模还不够大。
另据分析公司Similarweb的数据,自2023年4月开始, ChatGPT平台访问量就出现下滑,2023年年8月访问量比5月下降21%。美国 AI 分析师Alberto Romero也认为,AI 平台访问量停滞不前,很多大模型企业增长、收入和利润率都不尽如人意,AI 初创公司的估值过高了。
没有市场空有技术的企业,要危险了,因为投资人的钱是有限的,大家都会不约而同投给更有市场潜力的大模型企业,比如智谱AI、百川智能等企业就拿到了好几家互有竞争关系巨头的投资;投资人不再像以往互联网创业高潮时,互相投几个竞品,大家互相烧钱,竞争到最后哪怕赢家也是惨胜。
实际上,2023年除了少数几家大模型创业企业拿到大笔融资,大部分创业企业并没有获得大笔融资,反而在内卷的赛道中被大家拿放大镜去寻找差错。
就算是拿到大额融资的独角兽,也有一些我们并没有看到太多动作,比如MiniMax的产品就比较“藏在深闺”,尽管和金山办公、掌阅、腾讯等企业也已经有合作落地案例,但相比其他几家独角兽,在曝光量上似乎没有那么多。是足够自信所以低调,还是避免被更多人拿放大镜去看?
一些企业的低调,是因为PPT好做而产品难做,技术不好做但市场更难做。但没有足够的声量去助威市场的开拓,仅仅技术有优势未必就不怕“巷子深”。
死于开源还是死于从开源向闭源的惊险一跳?
主打开源的Stability AI,到底是怎么挣钱的,市场在哪里?开源就等于免费吗?其产品Stable Diffusion既然采用免费开源模式,又如何能够盈利?
当然不是。
开源也可以挣钱。比如智谱AI就开源了ChatGLM-6B、GLM-130B等。当然,也不能说智谱是开源公司,智谱的选择是开源先行,开源与闭源同时存在。开源是为了培育生态,占领更多用户。
用户用习惯了,再开始挣钱:一是根据客户需求,提供大模型定制化开发服务,云端私有化本地私有化最高价格分别为120万元/年和3690万元/年;二是标准版大模型,提供API接入方式,按照Tokens使用收费,ChatGLM-Turbo、CharacterGLM、Text-Embedding收费标准分别为0.005元/千Tokens、0.015元/千Tokens、0.005元/千Tokens。据了解,目前,智谱AI的商业化主要面向企业和机构的B端用户。
智谱CEO张鹏就曾指出,开源的好处就是开发者可以低成本、快速地切入使用上大模型,但开源大模型在安全性、稳定性等方面很难得到保障,而商业版本可以提供更多的服务,更多的保障以及更多后续的服务。
此外,国外不少初创大模型企业也都用开源来开局,如Hugging Face推出的HuggingChat,比如美国芯片制造公司Cerebras(开源Cerebras-GPT)、Databricks(开源Dolly)等。
开源其实只是大模型企业用于敲开客户大门的一块敲门砖,客户可以使用开源大模型训练一定参数的、在企业内部部署的大模型,只要客户用习惯自己的开源模型,就可以转为付费用户,购买调试更加*的闭源大模型,从而享受到更全面的大模型服务。
而Meta的Llama 2在2023年7月宣布开源,并且可直接商用。巨头的开源就不同于创业企业的开源,不仅是为了当敲门砖,而是仿照安卓开源的思路,在落后于OpenAI之后,试图用免费开源吸引更多开发者从而构建出强大完整的生态,日后再通过生态盈利。
所以,拆解Stability AI的问题,没有市场的关键,就在于没有走通从开源迈向闭源的商业一步,开源是为了能够引导向可商业化的闭源,不能为了开源而开源。而OpenAI这类闭源大语言模型,B端会向接入其端口的APP应用收取费用,C端像用户收取使用费用,走通了商业化之路,才能去畅谈未来。
死于找错了场景?
死了的或者投资人失去信心的大模型企业,基本都是找错了场景。
文生图场景,能够活下来几家?
至少Stability AI没有跑通,Midjourney等巨头又基本垄断了主要市场,创业者可以基于开源模型做开发还可以走,一些艺术家也在AI文生图领域做轻创业。但想做一个类似Midjourney这样的文生图大模型,靠C端付费盈利,就基本被堵死了这条路。
谷歌的文生图大模型 Imagen 2有多少人用?当然,国内还是有大厂在做,如文心一格大模型,美图的文生图模型等。
但美图主要还是用大模型技术,实现AI绘画、AI扩图、AI头像、牙齿矫正、AI去皱纹等功能,本质上是对以往美颜功能的再强化。
不过,美图并不避讳俗气的美颜。美图CEO吴欣鸿就曾在财报电话会里指出:“我们不能无边无际去做一个大而全,什么能力都有,但不知道要给谁用的模型。美图一开始就是有明确的需求和场景来反推模型的研发。”
所以美图不做高大上的、Midjourney一样的文生图,而是根据固定指令去做轻量化但很实用的“文生图”,进一步优化用户的美颜需求。
代码生成,也是大模型企业最想落地商业化的场景。
智谱AI CEO张鹏曾表示,国外真正的AI落地过程当中最明确的一个需求、一个场景就是代码辅助,大概占整个付费意愿里面50%以上的场景,智谱也在国内做类似的落地。
商汤也在今年推出“小浣熊”2.0版本,包含办公辅助、代码辅助等功能。小浣熊基于日日新SensNova大模型,在代码辅助上,评测指出可以帮助开发者提升编程效率超50%。
此外,AI Agent也被很多大模型企业视为变现的重要道路。什么是AI Agent?其实就是不必人类一步一步下达指令,可以自主感知、规划决策、执行复杂任务,这就需要在大模型基础上,增加规划(Planning)、记忆(Memory)、工具(Tools)等组件。要不然每个任务还需要一个单独的指令下达人员,对企业来说也就不能节省成本。
找对场景,可以获得营收。找错了场景,烧完钱可能就会面临经营难以维系的窘境。
不过,中国的大模型企业,除了少数新创企业,大部分背后都还有一个可以输血的母公司。赔多了不敢说,但一两亿美元的前期投资,一般还是能够支持,找错场景赶紧切换,还能有一些容错的时间。
死于通用还是死于专业
至少在去年,行业多将大模型的落地市场,分为通用大模型和垂直大模型两大类。
通用大模型,一般参数千亿以上聚焦基础层,百度文心一言,阿里通义千问、科大讯飞星火大模型等。
垂直大模型,一般参数在十亿、百亿级别,聚焦解决垂直领域问题,一般在通用大模型基础上训练行业专用模型,应用到各类垂直行业。
一般而言,通用大模型做C端,或者赋能垂直大模型;垂直大模型则主做B端。但这个分类,真的能够囊括这么多类型的大模型创业吗?
谁更挣钱?
垂直未必不挣钱。前几天据报道,就有一家企业中标了千万级的湘钢人工智能钢铁大模型建设项目(硬件部分)。
通用也未必不挣钱。据百度在刚结束的GENERATE 生态大会上透露,截至2024年3月底,百度智能云的千帆大模型平台已经为 8.5万家企业提供服务,帮助他们精调了1.4万个大模型,并开发出超过19万个大模型应用。显然,这些服务不会都是免费的。
不过,大家依然打的难舍难分。
你百度赋能行业,我阿里、字节同样能做到。
2023云栖大会上,阿里巴巴集团主席蔡崇信透露,目前全国80%的科技企业和超过一半的AI大模型公司跑在阿里云上。阿里云同样在赋能千行百业。
火山引擎在2023年一场会议上也透露,火山引擎的大模型云平台获得智谱AI、昆仑万维等众多企业的良好反馈;国内大模型领域,七成以上已是火山引擎客户。
做通用的巨头,真的就能三分天下或者五分大模型天下?巨头既做赋能自己也下场做大模型,如何和生态伙伴相处?
这些问题不解决,通用大模型也未必能一直稳坐钓鱼台。
死于B端还是死于C端?
通用和专业大模型,其实还可以转化为另外一个问题,做C端还是做B端?通用大模型两者皆可,而垂直大模型基本都是做B端。
相比于对C端客户收费,一个月几十块一年几百块,10万级的付费用户数才能做出几千万的营收。而且,中国用户很难习惯对软件付费,毕竟摸不着。哪怕国内率先对C端收费的通用大模型,也没有公布相关的营收。
做B端,拿到几个项目就能做到几千万营收。而且,虽然AI时代不同于互联网时代,但网友们依然习惯免费精神,能够持续付费的就只有B端了。
那么,B端就比C端更容易跑通商业化之路吗?
在金融、工业、协同办公等领域,帮助企业私有化部署大模型,看起来是个好生意。但同样更多B端场景,客户连信息化、数字化都还没有完全适应,更不要说再加个大模型。
而且,做B端就要深入嵌入企业业务流程,看起来拿下了客户关键业务入口,但客户对大模型的确定性要求也更高了。来个幻觉问题,怎么办?那就需要更多的人机协同,客户发现投入越来越重,也会有所顾虑。
B端不好做,C端又不好付费,大模型创业,也更容易死亡在这种夹缝之中。
未必死于缺卡一定死于缺钱
投资人朱啸虎前段时间还在接受腾讯新闻《潜望》栏目专访时给中国大模型产业泼了冷水,表示不看好国内大模型创业,认为大模型最终还是大厂的机会,和看好大模型创业的傅盛也在朋友圈观点激辩。
争辩未必分对错,都是为了流量。不过,当很多人觉得缺卡会影响国内大模型创业时,其实,缺卡的大模型创业企业,未必就活得不好。反倒是一些不缺卡的大模型企业,其体验未必能赢显卡没有那么宽裕的创业企业。
关键是不能缺钱。
不缺钱的大模型初创企业,目前至少都活得风生水起。比如阿里投资的月之暗面、MiniMax、智谱AI、百川智能和零一万物五家大模型独角兽企业,当然,阿里、腾讯、字节等巨头在五家独角兽的投资上也都有所争夺和取舍。其中月之暗面、智谱AI和百川智能都非常活跃,月之暗面作为创业企业,还凭借超长文本能力在行业掀起了一场长文本军备竞赛。
使用体验上,据一些同事分享,智谱AI等创业企业的大模型,使用体验并不输给一些巨头旗下的大模型。
而笔者个人在测试月之暗面Kimi时,如果对话窗口输入过多文字,整个浏览器(Chrome)崩溃的概率就会提高很多倍,笔记本风扇也因此“呜呜”转起来。超长文本如果容易导致网页崩溃,那产品依然还需要优化。在网页界面上,月之暗面kimi似乎并不够精致,跳动的对话机器人头像也过于卡通(当然,审美偏好仅限于个人体验)。
如果超长文本带来的热度不能让团队更进一步去优化迭代,那企业很可能又要陷入某一种大模型创业的艰难宿命中。
长期10年后会怎样,谁也无法预测。但只要不缺钱,短期三两年内,这五家估值均超过10亿美元的独角兽必然有能够跑出来的。而这几家独角兽,也并不以显卡多为核心竞争力。
所以,缺卡不可怕。买不到*进的英伟达,国内也不是不能购买替代卡或者租用算力,只不过或许没有那么顺手而已。
缺卡,被行业渲染得过分可怕了。
当然,所有原因,归根到底都是缺钱。不过,相比于缺卡、缺钱,未来大模型产业发展要面临的更大问题,是缺电。
据斯坦福人工智能研究所(HAI)《2023年人工智能指数报告》数据,OpenAI的GPT-3单次训练耗电量高达1287兆瓦时(1兆瓦时=1000千瓦时)。如果跑费一辆特斯拉需要100万公里,那么单次训练的耗电量能跑废大约1000辆特斯拉电动车。随着模型参数越来越大,大模型企业训练、推理需求进一步上升,耗电量还将几何级上升。未来,或许还会有大模型企业,会不得不为电费折腰。
会输给AI PC吗?
由英特尔牵头发起、面向商用领域的AI PC硬件产品与商业应用已经于3月正式发布,当然,除了英特尔之外,AMD、苹果同样重视个人电脑的AI化,都在探索CPU+GPU+NPU的多硬件加速器架构。酷睿Ultra、锐龙8040、苹果M3等系列处理器均对AI有特异化设计。
AI PC会影响大模型创业者吗?毕竟消费者自己有了适合的端侧的本地算力,可以运行十亿、甚至百亿级别参数的大模型,还需要使用付费的云端大模型吗?
或许这一点不用担心。以手机的端侧大模型为例,目前vivo、OPPO、小米等最新的旗舰手机都搭载了端侧大模型,使用手机算力进行推理。但受限于算力有限,目前效果,和发布时的“卖家秀”相比就是“买家秀”,原来没有那么惊艳。
反倒是基于云端算力的一些大模型APP、官网,在手机、电脑上的表现会更好。
据了解,由于合规问题,苹果手机的AI功能不能使用谷歌的Gemini,而苹果自研AI由于造车的耽搁,目前落后于对手,至少目前苹果要想推出有竞争力的AI功能,只能与国内企业合作。有爆料指出,苹果此前曾三家公司洽谈合作 AI 大模型,其分别有百度的文心一言、阿里的通义千问、月之暗面的 Kimi,但分析称目前概率*的还是百度。
不过,端侧的一大优势,就是最接近使用者,一旦端侧大模型进一步优化,或者类似苹果寻找百度合作推出手机端侧大模型,在效果可与云端算力比拼的时候,非巨头的大模型创业者又该如何应对?
毕竟,端侧大模型使用本地算力,长期也不会收费。而现在免费使用的很多大模型,在C端终将有一天要走向收费,或者免费模式仅可使用表现一般的模型版本。
大模型创业者们如何比拼才能避免死亡?
我们没有答案。但大多数时候,大模型行业整体都是缺钱的,都是刺刀见红的,算力都是紧张的,C端都是一将功成万骨枯的,B端都是难以憋出大招瞬间制胜的,通用大模型都是投入巨大的,专业大模型都是缺乏贯通行业的优质数据的,场景和市场都是千变万化的……死因何止七种?
千难万难,只有在有限的资源内做出更加*的产品,才能在未来的激烈竞争中占据一席之地。
【免责声明】:本文不构成任何投资建议。市场有风险,投资需谨慎。
如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。










