

马斯克(Elon Musk)真的实现了他的承诺——把大模型Grok-1开源了。
钛媒体App获悉,北京时间3月18日早上,“硅谷钢铁侠”、亿万富翁马斯克旗下AI初创公司xAI宣布,其研发的大模型Grok-1正式对外开源开放,用户可直接通过磁链下载基本模型权重和网络架构信息。

xAI表示,Grok-1是一个由xAI 2023年10月使用基于JAX和Rust的自定义训练堆栈、从头开始训练的3140亿参数的混合专家(MOE)模型,远超OpenAI的GPT模型。而此次开源的模型是是Grok-1预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。
对此,英伟达科学家Jimfan评价称,这是有史以来最 大的开放大型语言模型,由世界级团队训练,通过磁力链接发布。Apache 2.0。314B,专家混合(8个活跃中的2个)。就连活动参数仅(86B)就超过了最 大的Llama。迫不及待地想看到基准测试结果以及人们用它构建的内容。
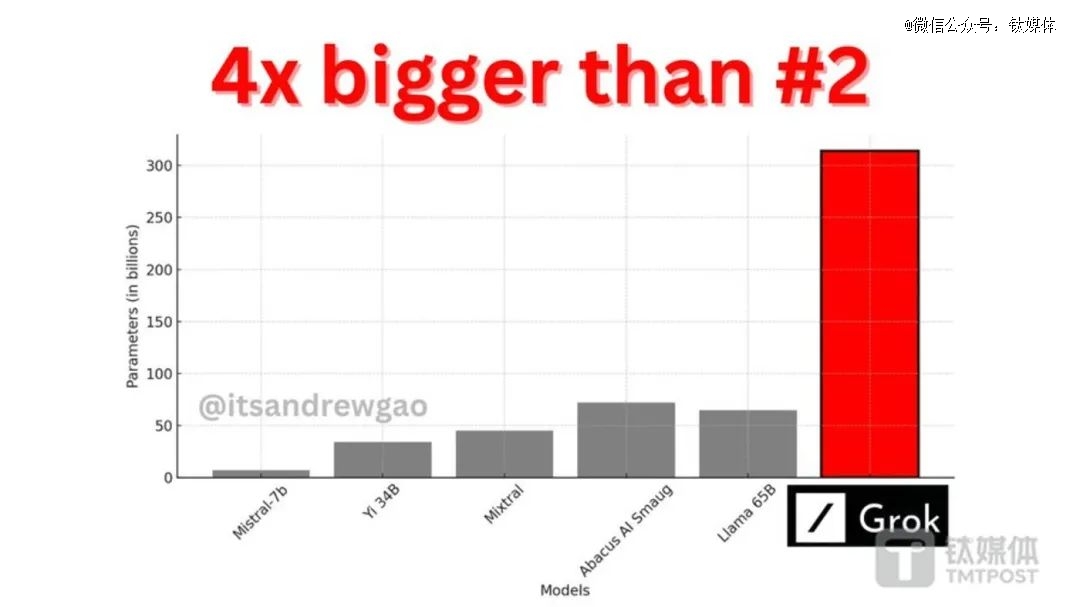
langchain的Andrew Kean Gao评论认为,“Grok是有史以来最 大的开源大模型,是llama2尺寸的4倍。”
ChatGPT则和马斯克在评论区互相嘲讽。
马斯克随后发推文表示,“告诉我们更多有关OpenAI的‘开放’部分的信息”。他直言,xAI这个平台“已经是迄今为止最透明和最求真的平台(说实话,门槛并不高)”。
截至发稿前,Grok上线GitHub后狂揽了6000星,586个Fork。
据悉,2023年7月,特斯拉CEO马斯克宣布成立一家新的人工智能公司xAI,新公司使命是“了解宇宙的真实本质”,目标是打造OpenAI的竞争对手。
作为OpenAI创始人之一,也是最新的OpenAI批评者,马斯克此前已表示,OpenAI已偏离了其预期目的,成为了一个以利润为导向的实体。他直言,OpenAI最初是作为一个非营利性开源组织创建的,目的是抗衡谷歌。但此后它变成了微软控制下的一家闭源、以利润为导向的公司。“OpenAI已经成为一家利润最 大化的公司……这根本不是他的初衷。”
马斯克还谴责OpenAI遭到微软的控制。他表示,世界需要一个替代GPT的AI技术选择。
去年11月,马斯克正式发布xAI旗下首 个大模型和应用成果方案Grok,并将Grok AI助手内置在社交平台X上。马斯克曾表示,“在某些方面,它是目前存在的最 好的(AI技术)。”
当时马斯克表示,调优之后的Grok大模型具有330亿个参数,性能基准上接近Llama 2-70B,在HumanEval编码任务、MMLU基准上的结果分别为63.2%、73%。
今年2月,马斯克向美国旧金山高等法院提起诉讼,起诉OpenAI和公司联合创始人、CEO奥特曼(Sam Altman),公司总裁Greg Brockman以及 OpenAI 的若干实体,控告OpenAI团队违约、出尔反尔(“允诺禁反言”)、不正当竞争等。
马斯克在46页、1.4万字诉讼文件中声称,OpenAI违背初衷,背叛了OpenAI这家AI公司成立时达成的一项协议,即开发技术的目的是“造福人类”而非利润。他认为,OpenAI最近与微软的密切关系损害了该公司最初对开放、开源通用人工智能(AGI)领域的贡献,他要求OpenAI开放技术并寻求偿还他提供的资金。
3月初,OpenAI“反击”称,“当创始团队讨论以营利为目的的结构以进一步实现使命时,马斯克希望我们与特斯拉合并,否则他想要完全控制。马斯克离开了OpenAI,表示需要有一个与Google/DeepMind相关的竞争对手,而他将自己做这件事。他说他会支持我们找到自己的道路。”而且该公司驳回马斯克的所有主张,并称为事情发展到这一步感到遗憾。
马斯克则直接回应,OpenAI并不开源,Grok要直接开源(Open)。
如今,Grok-1正式开源,其拥有3140亿参数,具备先进MOE架构,远超GPT-3.5、llama2等,是迄今为止参数量最 大的开源大语言模型。
xAI称,这个版本包含了Grok-1在2023年10月完成预训练阶段时的基础模型数据。根据Apache 2.0许可协议,向公众开放模型的权重和架构。以下是钛媒体App梳理的关键信息:
该基础模型通过大量文本数据训练而成,未专门针对任何具体任务进行优化。
3140亿参数构成的混合专家模型,其中25%的参数能够针对特定的数据单元(Token)激活。而xAI团队利用定制的训练技术栈,在JAX和Rust的基础上,从零开始构建了此模型,完成时间为2023年10月。
模型参数数量高达3140亿,具备混合专家模型(Mixture of Experts, MoE)8架构,每一个数据单元(Token)由2位专家处理,共64个处理层,用于处理查询的有48个注意力机制单元(attention heads),用于处理键(key)/值(value)的有8个注意力机制单元,嵌入向量(embeddings)的维度为6,144,采用旋转式嵌入表示( RoPE) ,使用SentencePiece分词系统处理,包含131,072种数据单元,支持激活数据分布计算(activation sharding)和8位数字精度量化(8-bit quantization)
最 大序列长度为8,192个数据单元,以处理更长的上下文信息
纽约时报点评道,开源Gork背后的原始代码,是这个世界上最富有的人控制AI未来战斗的升级。
Meta CEO扎克伯格刚刚也对Grok做出了评价:“并没有给人留下真正深刻的印象,3140亿参数太多了,你需要一堆H100,不过我已经买下了”。
值得一提的是,近期南加州大学的论文称,OpenAI发布的GPT-3.5-turbo 的参数规模也在7B(70亿)左右,除非是MoE 架构可能不同,并估计gpt-3.5-turbo的嵌入大小为 4096,称花费不到1000美元就把最新版gpt-3.5-turbo模型的机密给挖了出来。
有网友形容,马斯克对于模型技术这么大方,中国企业终于有福了。
3月17日,北京师范大学新闻传播学院教授、北京师范大学传播创新与未来媒体实验平台主任 喻国明在一场演讲中表示,别人一开源中国 AI 模型就使用是不正确的做法,对于安全性有所影响,必须国内要解决数据开源的规则问题。同时,大模型算力不足下,中国不应该“一窝蜂”做300多个大模型,而是应该做一些垂直行业、边缘计算的小模型,从而解决实际应用问题。
“模型的价值不在于数据、算法、算力的大小,而在于能否为人创造真正的价值大小,并且在价值链条中扮演关键角色。价值的最终实现,取决于大模型与小模型之间的融合与协同。”喻国明表示。








