

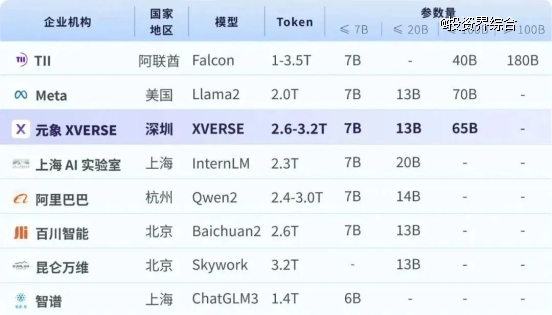
国内此前开源了多个70到130亿参 数大模型,落地成果涌现,开源生态系统初步建立。随着智能体(AI Agent)等任务复杂性与数据量的提升,业界与社区对更“大”模型的需求愈发迫切。
研究表明,参数量越高,高质量训练数据越多,大模型性能才能不断提升。而业界普遍共识是 达到500到600亿参数门槛,大模型才能“智能涌现” ,在多任务中展现强大性能。但训练此量级模型成本高昂,技术要求较高,目前主要为闭源付费提供。
在国外开源生态中,Llama2-70B和Falcon-180B等标杆模型为“有条件”开源,设置了月活跃用户数或收入等商用上限,并因缺乏训练数据在中文能力上有明显短板。此外,美国新近颁布的AI芯片禁令,或将进一步限制中国大模型产业发展的速度。 业界迫切呼吁一个高性能国产“大”模型,填补生态空白, 为中文应用提供更强大的理解、推理和长文生成能力。
为推动国产大模型开源生态繁荣与产业应用快速发展,元象XVERSE公司宣布 开源650亿参数高性能通用大模型XVERSE-65B,无条件免费商用,业界尚属首次。 13B模型全面升级,提高“小”模型能力上限。这将让海量中小企业、研究者和AI开发者 更早一步实现“大模型自由” ,根据其算力、资源限制和具体任务需求,自由使用、修改或蒸馏元象大模型,推动研究与应用的突破创新。
元象XVERSE创始人姚星表示:“面对研发时间紧、算力持续短缺等挑战,团队依靠丰富经验,三个月内研发出多款高性能7B、13B模型,并最早为社区献上一个‘大有可为’的65B模型,为研究、商业及生态创造三重价值。”
具体而言,研发上,65B将为新技术、新工具、性能优化到模型安全提供“大杠杆”,让社区快速累积经验,也有助于推动国家科技自主可控的长远目标。商业上,海量中小企业能以零成本用上“大工具”,可突破局限,推动应用显著创新。元象也能深入了解用例、安全模型部署和潜在机会。在开发者生态上,社区能充分发挥组织协同优势,推动研发应用的“寒武纪大爆发”。
开源可免费商用大模型图谱
全链条自研 多项技术创新
XVERSE-65B底座模型在2.6万亿Tokens的高质量数据上从头训练,上下文窗口扩展至16K,支持中、英、俄、法等40多种语言。XVERSE-65B Chat版也将在近期发布。
元象坚持“高性能”定位,显著提升了65B三方面能力: 一、理解、生成、推理和记忆等基础能力,到 模型的多样性、创造性和精度表现,从优异到强大;二、扩展了工具调用、代码解释、反思修正等能力,为构建智能体(AI Agent)奠定技术基础,提高模型实用性;三、显著缓解7B、13B中常见且可能很严重的幻觉问题,减少大模型“胡说八道”,提高准确性和专业度。
元象大模型系列均为全链条自研,涵盖多项关键技术与研发创新:
- 复杂分布式系统设计:借鉴团队研发腾讯围棋AI“绝艺”、*荣耀AI“绝悟”等大系统上的丰富经验,自研高效算子、显存优化、并行调度策略、数据-计算-通信重叠、平台与框架协同等关键技术,打造高效稳定的训练系统, 千卡集群峰值算力利用率达58.5%,位居业界前列。
- 全面提升性能:65B训练中采用 FlashAttention2加速计算, 3D并行基础上采用虚拟流水线(virtual pipeline)技术,降低较长流水线产生过高气泡率,提升计算推理效率; 上下文窗口长度从8K逐步提升到16K,使其不仅能出色完成复杂任务,包括长文理解、长文生成和超长对话,还拓展了工具调用、代码解释及反思修正能力,能更好构建智能体(AI Agent)。
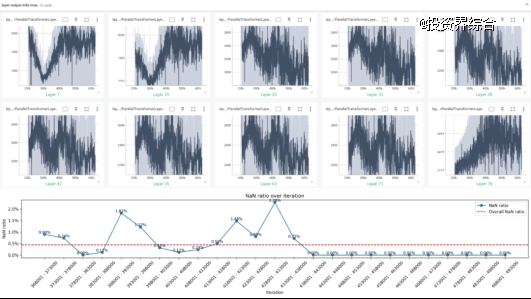
- *提升训练稳定性:因计算量庞大,通信拥塞、芯片过热或计算节点故障成为65B训练常态,初期出现过一周最高八次故障的情况。通过集群基础设施运营、资源调度、训练框架和调度平台协同等持续优化,元象打造出高稳定、低中断、强容错的训练系统,将每周有效训练率提升至98.6%。
此外,在接近1.6万亿Tokens的模型训练中期,损失函数产生了NaN值,可能导致训练中断。通常情况下,业界一般会在分析后删除与之相关的数据区间。而团队根据经验判定这是模型自然演化,选择不删除数据,直接跳过相关参数更新,最终 NaN值 问题解决。后期对 参数值、激活值、梯度值等中间状态的进一步分析表明,该问题可能 与模型最后一层transformer block激活值的*值变化有关,并会随*值的逐渐降低而自行解决。
解决NaN值问题研发经验
全面测评 65B性能媲美G PT3.5
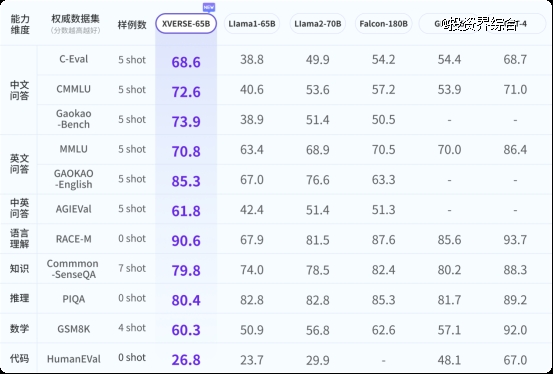
为确保业界能对元象大模型性能有全面、客观、长期认知,研究人员参考了一系列权威学术测评,制定了涵盖问答、理解、知识、推理、数学、代码等六个维度的11项主流权威测评标准,将持续使用并迭代。
XVERSE-65B在 国内尚无同量级模型可对比,在与国外标杆对比测评中,部分指标超越、综合性能媲美GPT3.5;全面超越开源标杆 Llama2-70B 和Falcon-180B ;与GPT4仍有差距。
XVERSE-65B评测
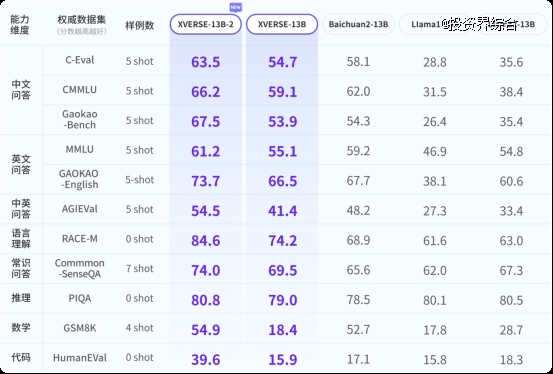
全面升级的XVERSE-13B-2,比同尺寸模型增加大量高质量数据,训练数据高达3.2万亿, 极大提升了“小”模型的能力上限。它 文理兼修,保持了文科优势,问答提升18%,理科长足进步, 代码提升149%、数学提升198%,在测评中全面超越了Llama2、Baichuan2等国内外开源标杆。
升级版XVERSE-13B-2测评
开启 大模型应用新时代
元象大模型可在Github、Hugging Face、魔搭ModelScope等多平台搜索“XVERSE”下载,简单登记后即可无条件免费商用,能满足中小企业、科研机构和个人开发者绝大部分的应用与迭代需求。
元象同时提供模型训练、推理、部署、精调等全方位技术服务,赋能文娱、金融、医疗等各行各业,帮助在智能客服、创意写作、精准推荐等多场景打造行业*的用户体验。2023年10月, ,共同推出lyraXVERSE加速大模型、全面升级其音乐助手“AI小琴”,未来还将持续探索AI与3D前沿技术,引领音乐娱乐创新方向。
姚星表示:“真实世界的感知智能(3D),与真实世界的认知智能(AI),是探索通用人工智能(AGI)的必由之路,也是元象持续探索前沿科技的动力。XVERSE开源系列致力于推动大模型 国产可替代与持续 技术创新, 为实体经济、数字经济发展注入强劲动力。我们期待与企业和开发者携手,共同开启 大模型应用新时代!”







