

TL;DR
- 从2017年至今3D经历过了3D视觉、元宇宙还有当前的大模型+MR驱动的三波热潮,软件(AI)和硬件(Vision Pro)共振带来的新一波热潮有望带来更持续的3D创新;
- 文字和图像的大模型都已经有了各自的基石模型并进入到应用爆发期,3D生成模型仍处在模型迭代阶段,尚无行业*,但创新速度明显加快,市场在等待属于3D的“Midjourney时刻”;
- 现有3D管线研发成本高、制作周期长,AI+3D正在通过以下几种方式大幅优化3D生产管线:生成式3D建模、纹理生成及绑定、服装布料生成及驱动、Text to action动画驱动、基于大模型的新交互方式(LUI、拖拉拽式交互)、3D资产库+LLM,其中生成式3D*有变革性;
- 现有3D生成模型可以划分成“原生3D”和“2D升维”路线,目前都面临着生成速度、质量、丰富性的“不可能三角”:“原生3D”通常在生成速度和质量上占优,但由于3D数据的匮乏导致生成的丰富性上仍是短板,“2D升维”则继承2D图像生成的丰富性,同时在生成速度和质量上快速追赶;
- “3D原生”的生成式模型更接近商业化要求,会在特定场景下先行商业化,“2D升维”的生成式模型预期未来一年内有机会在元宇宙等对生成质量要求不高的场景落地,真正的3D应用市场爆发尚待XR的成熟渗透,我们认为五年内AI+3D TAM市场的下限是3D资产交易市场的27亿美元,乐观能看到数百亿美元的市场(单游戏的3D研发投入就超过百亿美元)
- 当前阶段有底层技术能力的公司会有显著的竞争优势,而3D应用的爆发仍需至少一年以上的时间,届时竞争要素才会逐渐往产品端倾斜,但优秀的AIGC公司应当是拥有底层技术的同时有自己的爆款C端应用。
目录
引子:三看3D,我们在期待什么?- 一、AI+3D=?
- 二、生成式3D的加速狂奔与“不可能三角”
- 三、生成式3D的商业化路径和市场潜力
- 四、谁能成为3D的“Midjourney”?
- 引子:三看3D,我们在期待什么?
- 最近3D借AI的光又被广泛地讨论起来了。*次记忆中的“3D热”始于2017年iPhone发布了带3D结构光的iPhone X,三年后又发布了基于3D dTOF的Lidar。那是少数苹果没有带起来的“时髦”的新技术,因为友商们最后发现增加了数十美金的BOM成本死磕技术带来的体验提升似乎有点鸡肋,智能手机上迟迟没有等来那个3D的Killer app,*次“3D热”随即进入冷静期。第二次是在2021年,Roblox“元宇宙”*股、Quest销量突破千万“奇点”、Meta加入万亿俱乐部,智能手机接不住的“3D热”用XR可还行?结果VR始终没能突破“游戏主机”的叙事,而下行的经济环境下一台399美元的笨重的游戏主机又难免有些奢侈,22年VR出货量跌破千万、Meta股价打到骨折,3D再次无人问津。而今年开始的这波“3D热”主要是受LLM和Text to image为代表的大模型驱动,叠加6月WWDC中千呼万唤始出来的苹果的Vision pro,似乎在软件和硬件层面又开始有了一些新的变化。
图:近三次3D热潮3D的体验和交互是人自然而然的需求,制约3D的从来都是供给端,而供给端的瓶颈主要有两个:1)适应3D的体验优异的硬件终端;2)丰富且高质量的3D内容。之前两次热潮都由硬件引领,而Vision pro又给硬件创新带来了新的期待,这次大模型创新之于3D则主要是在内容创作门槛的降低,生成式3D、3D copilot等都在日新月异地迭代,期待在硬件和软件共振的创新周期中的新一轮3D热潮能够有更强和持续的生命力。
我们看到文本和图像的大模型都已经有了各自的无论开源还是闭源的基石模型,基于LLM已经诞生了Character AI、Inflection、Jasper等AI native的独角兽,LUI(基于LLM的用户交互)正在席卷和重塑软件行业,而图片生成领域除了Midjourney以外也出现了基于Stable Diffusion等开源模型的Lensa、妙鸭相机等“轻”而爆火出圈的应用。我们不禁想问,3D的“Midjourney时刻”何时到来?
图:文字、图像、3D大模型发展脉络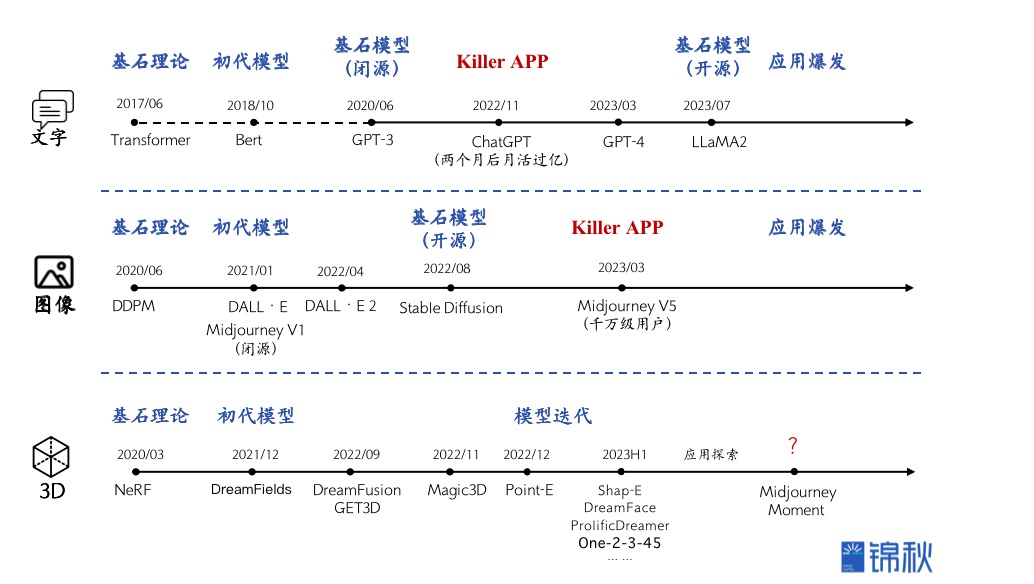
一、AI+3D=?
1)现有的3D管线周期长、高度依赖人工现有的3D资产生产管线大致包括概念设计、原画制作、3D建模、纹理贴图、动画驱动、还有渲染。
其中3D相关的环节制作周期长、高度依赖人工,往往是研发投入的大头。以*的游戏市场为例,全球市场来看3D游戏约占全部游戏的60%以上,而在3D游戏中3D美术相关的支出通常会占到研发成本的60%-70%以上,包括3D建模、纹理贴图、驱动动画等,一款*3D游戏在3D研发上的投入可以高达数亿美元,整个游戏行业每年在3D相关的研发投入~75亿美元。以3D游戏中的人物建模举例,一个十万面以上的3D高模资源,厂商如果要委托外包团队生产该模型,则价格至少需要3万元起步,时间为30-45天。即便是通过3D资产库购买的方式,除了面临可选的资产有限的问题以外,通常也需要花5-10人*天进行清洗才可以使用。全球*3D内容公司Sketchfab显示,3D模型生产周期在数小时到数天,生产成本平均高达千元以上。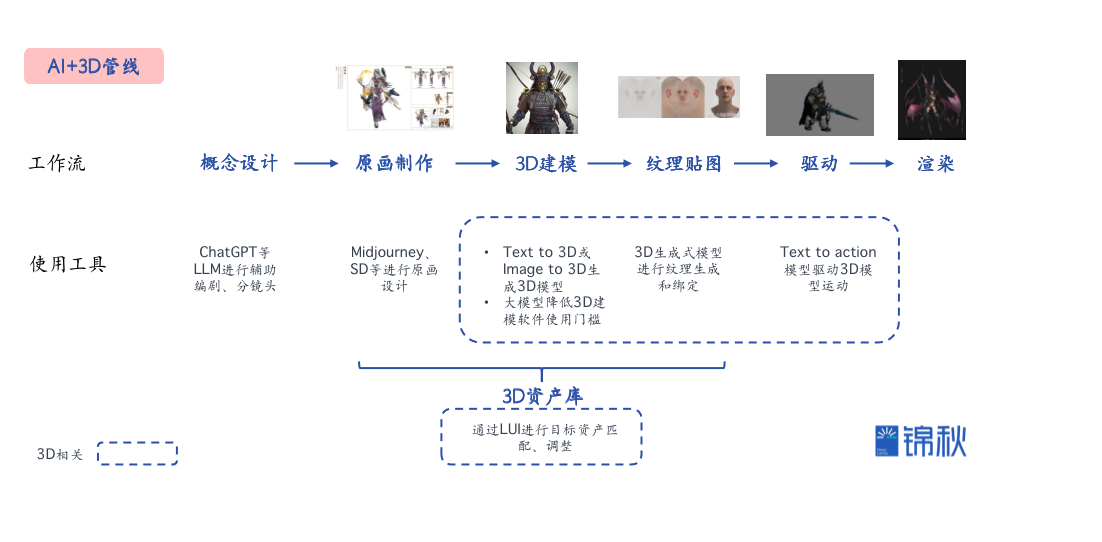
图:全球生产3D模型的费用,数据来源:Sketchfab除了3D模型资产以外,模型的动作、表情驱动也是耗时耗力的环节,特别在影视动画、数字人领域动画驱动的投入占比更高,都是有机会通过AI大幅提效的环节。2)基于生成式AI的3D管线可实现效率飞跃生成式AI几乎可以在所有3D管线的环节中发挥作用,提高生产效率、缩短制作周期。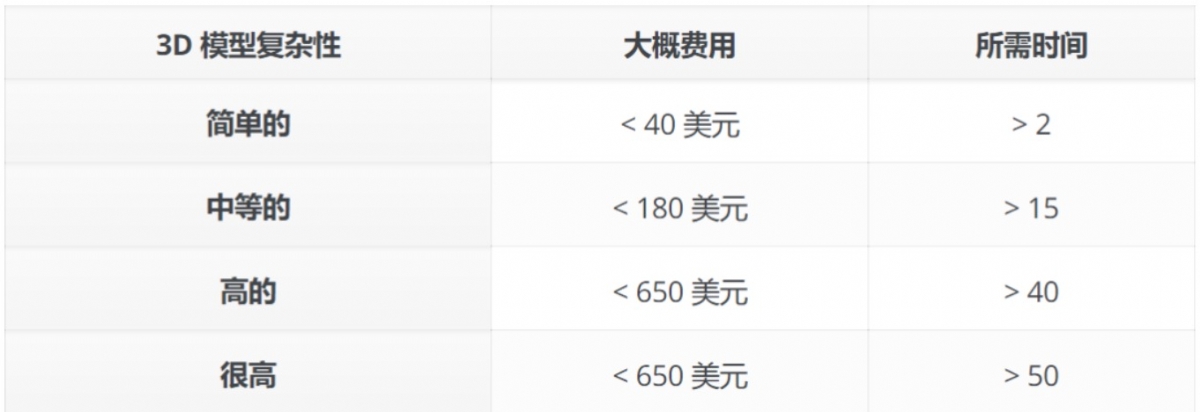
上图的管线中目前应用最广泛的还是文生图在原画制作环节,很多游戏工作室目前已经是美术人手一个Midjourney再加一些特定风格微调的Stable Diffusion,LLM能够在概念设计环节帮助编剧提升一定效率但更多还是创意辅助。相比之下3D与大模型结合则仍处在非常早期的探索阶段,但以5年维度来看,我们认为整个3D管线能够做到70%以上的成本、时间优化,意味着3-4倍的效率提升。目前我们关注到的AI+3D主要包括以下几种方式:- 生成式3D建模:类似Midjourney的文生图或图生图模式,以一段文字或者图片作为prompt输入,由生成式模型生成所需的3D资产,包括3D的虚拟人、物品、场景等,将原本高门槛、长周期的3D建模环节简化成只需要一句“咒语”或者一张“原画”就能够完成3D建模,生产效率有质的飞跃。由于3D生成模型对3D管线效率的极大提升,也是目前3D创新最为活跃的领域,下文将会展开重点介绍。
图:从左到右依次为Dreamfusion(Google)、Shap-E(OpenAI)、ProlificDreamer(生数科技)


- 纹理生成及绑定:目前基于NeRF(Neural Radiance Fields,神经辐射场)的3D生成模型通常是一步到位生成带贴图的3D资产,而没有单独进行纹理的生成和绑定,而非NeRF路线的生成模型通常会对几何和纹理进行分别生成,再进行绑定和驱动,比如英伟达的GET3D,上海科大的影眸科技提出的Dreamface,以及来自美国的Synthesis AI等。

图:英伟达GET3D模型图:Dreamface模型中的纹理材质生成环节
- Text to action动画驱动:类似OpenAI在图像领域提出的CLIP模型,通过大量的文本动作数据对进行预训练,形成大模型对于动作表情的理解和生成的能力,例如在虚拟人场景中根据对话文本生成合适的肢体动作和表情。
在action方面,字节旗下的朝夕光年在今年3月的游戏开发者大会(GDC)上介绍了将文本转化成全身动画的技术,并将应用在即将推出的游戏《星球:重启》;腾讯联合复旦于今年6月在Arxiv上发布了MotionGPT模型的研究;北京大学团队在7月份提出GestureDiffuCLIP用于语音语义到手势的生成;国内初创企业中科深智也基于多年文本动作对数据集的积累推出了CLLAP模型。
而表情驱动上比较有代表性的是英伟达的Audio2Face和多伦多大学的JALI模型,尝试通过对输入文本的理解生成恰当的口型和表情,目前在嘴型匹配上有比较好的进展,但整体表情生成上仍有待突破。
图:朝夕光年于GDC介绍Text to action技术
图:复旦联合腾讯发布的MotionGPT
- 服装布料生成及驱动:服装布料生成也是3D模型里比较重要的环节,在3D场景下不同布料工艺的服装如何生成、如何适配avatar体型、怎么解算服装的动画都是服装布料生成需要回答的问题。目前这块的相关研究尚处在早期,我们看到有凌迪科技Style3D通过diffusion+图形学仿真来实现生成和动画驱动,也关注到米哈游和伦敦大学等在2019年的Siggraph上联合发布了关于服装动画半自动生成的研究,而在米哈游的虚拟人鹿鸣新近的直播中我们看到其服装动画的实时解算渲染已经达到了较高的水平。
图:凌迪科技Style3D模型
图:米哈游、伦敦大学等半自动生成服装动画的研究
- 基于大模型的新交互方式降低使用门槛
- LUI:基于LLM,融入对话式的交互,实现类似微软office copilot式的软件交互,大幅降低3D建模软件的使用门槛,比如Unity在6月发布的Unity Muse。LUI已经在逐渐成为各类软件的标配,3D软件也不例外。
- 拖拉拽式交互:3D作为基于视觉的内容,很多时候通过Chat来进行微调不如通过拖拉拽的所见即所得来得高效,5月份的DragGAN模型实现了通过拖拉拽把图片中的大象P转身惊艳了整个行业,紧接着也马上有人基于DragGAN和3D生成模型Get3D缝合出了Drag3D模型,可以通过拖拉拽的方式对3D资产的几何形状和纹理进行编辑,也是有意思的探索方向。
图:Unity发布的Unity Muse工具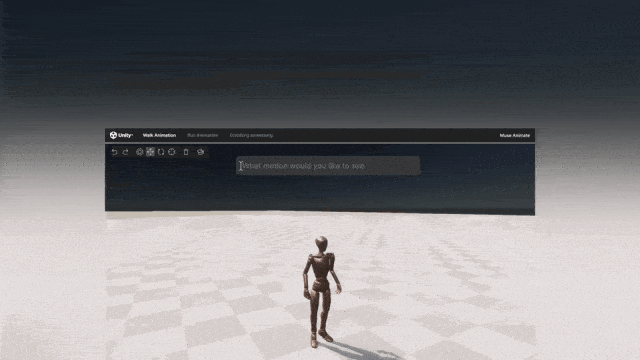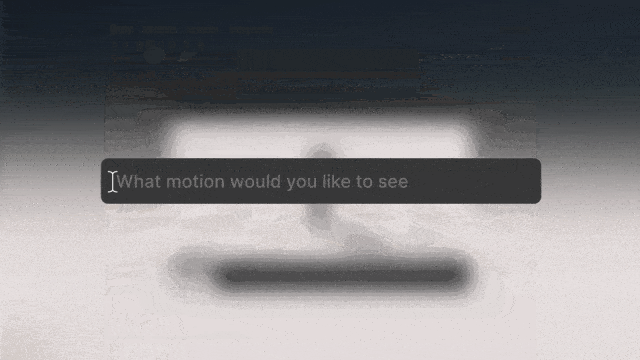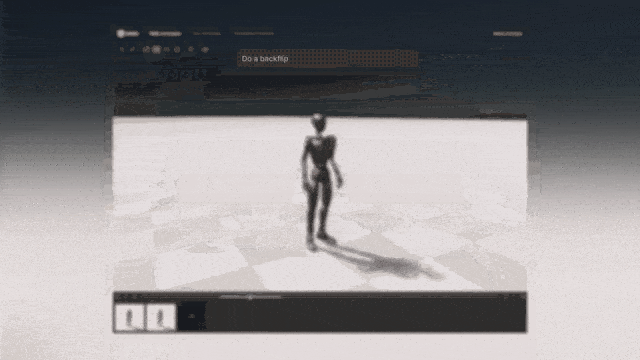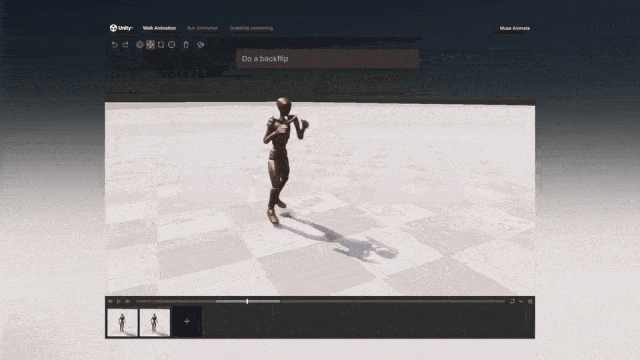
图:DragGAN模型效果图:Drag3D模型效果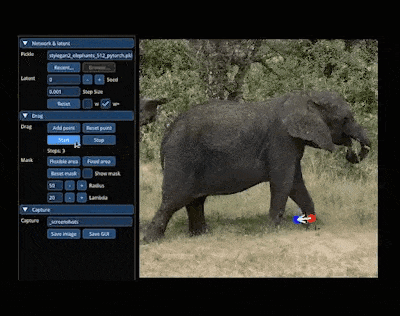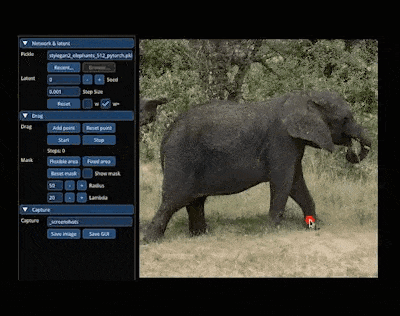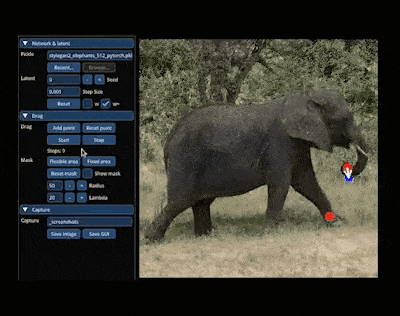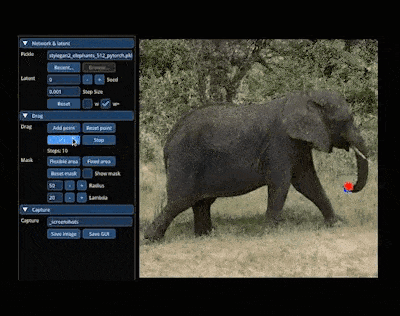
- 3D资产库+LLM:3D资产库可以基于LLM进行3D资产的快速匹配、参数调整,从而在资产库的范围内实现“Text to 3D”。美国老牌的3D资产库Tafi在6月份发布了惊艳的Text to 3D引擎demo,可以帮助用户在极短时间内“生成”想要的3D资产,并可导入到Unity等引擎进行后续的编辑和商用。
二、生成式3D的加速狂奔与“不可能三角”
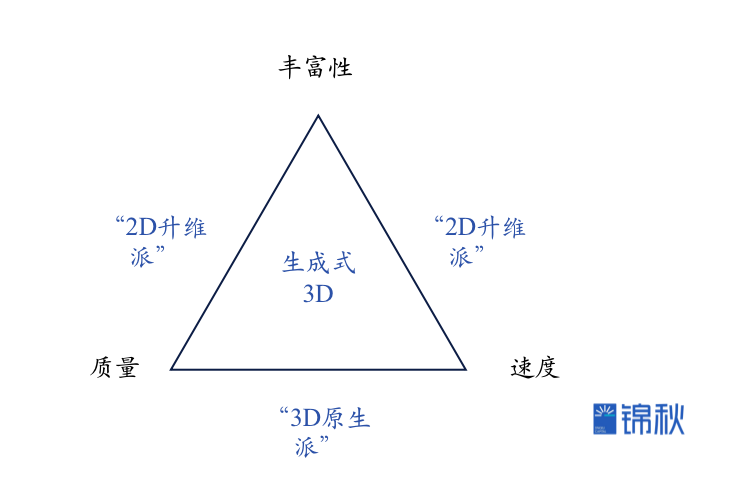
尽管大模型正在以多种不同的方式在改变着3D管线,但通过生成式3D模型实现3D资产的生成是本文的关注重点,包括3D建模和纹理贴图。一方面是3D资产建模和贴图研发投入占比最高,而生成式3D有望带来真正的生产力变革,另一方面是生成式3D是一个更加“3D native”的事情,相比之下LUI或者检索匹配已经在2D图像等领域快速渗透。生成式3D建模可以从“远古”的3D-GAN(2016)说起,而奠基最近一波3D生成的基础是NeRF模型(2020)和diffusion模型(关键成果~2020年),催生了到2022年底前诞生的Dreamfield、Dreamfusion、Get3D、Magic3D、Point-E等经典的3D生成模型,而进入2023年,随着大模型进一步成为显学,3D生成领域也开始进入了新的加速车道,半年多时间我们看到了包括Shap-E、DreamFace、ProlificDreamer、One-2-3-45等在生成质量或者速度上表现惊艳的模型。NeRF模型:NeRF(Neural Radiance Fields,神经辐射场),利用深度学习技术从多个视角的图像中提取出对象的几何形状和纹理信息,然后使用这些信息生成一个连续的三维辐射场,从而可以在任意角度和距离下呈现出高度逼真的三维模型。Diffusion模型:在深度学习中,Diffusion模型是一种以Markov链和噪声驱动的逆过程为基础的生成模型。该模型通过模拟噪声的慢慢消散过程,逐步形成想要的数据分布,常用于生成高质量的图像和其他数据类型。从实现路径上,生成式3D可以粗略划分为“原生3D”和“2D升维”两种不同技术路线。核心区别在于是直接文字到3D,还是先到2D图像再进一步通过扩散模型或者NeRF生成3D。两种路径的选择对于模型的生成质量、速度和丰富性有决定性的影响。
图:3D生成技术路线及典型模型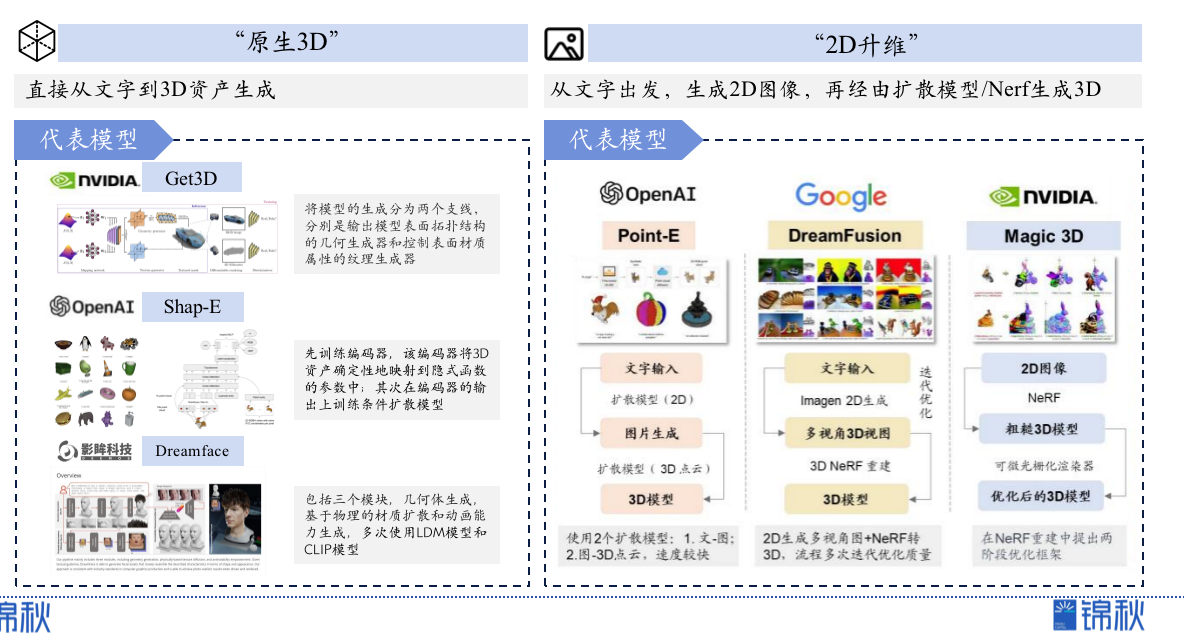
- 原生3D派:原生3D 路线主要特点是使用3D数据集进行训练,从训练到推理都基于 3D 数据,通常也是基于diffusion模型和transformer模型的方法进行训练,实现从文字/图片输入直接到3D资产的生成。
- 优势:
- 生成速度快:2D升维通常利用 2D 扩散生成模型来指导 3D 表示(如 NeRF)的优化,需要很多步迭代导致非常耗时,而3D原生的生成通常可以在1min以内完成,类似2D的文生图;
- 生成质量高:在特定范围内能够生成质量较高的3D资产,比如通过高质量的3D人脸数据可以训练出4k以上高质量的3D人脸,同时避免了2D升维的多面等问题;
- 兼容性好:通常有几何和纹理的分别生成,可以直接在标准图形引擎中进行后续编辑。
- 劣势:
- 丰富性不足:原生3D生成的问题在于缺乏高质量、大规模的3D数据集,目前比较大的3D数据集基本在百万级别,相比于十亿级别的图像数据集有三个数量级的差距,并且数据质量和一致性较差,制约了模型的“想象力”,比如没有见过的物品或者组合,对目前的原生3D模型往往比较挑战。
- 典型模型:Get3D(Nvidia)、Shap-E(OpenAI)、Dreamface(影眸科技)
图:Get3D(Nvidia)模型原理图
- 优势:
- 2D升维派:通过 2D 生成模型(如 Imagen、diffusion model)生成多个视角的 3D 视图,然后用 NeRF 重建。背后核心逻辑是3D数据集的匮乏难以满足丰富的3D生成需求,在2D的文生图红红火火的背景下开始越来越多的研究者试图基于海量的2D图像数据来实现3D的生成,并取得了飞速的进展。
- 优势:可以利用大量的2D图像数据进行预训练,数据的丰富性使生成的3D模型复杂度提高,富有“想象力”;
- 劣势:
- 生成速度慢:NeRF的训练和推理过程都需要大量的计算资源。因为需要对3D空间进行密集的采样,这也导致了生成速度较慢,不过最近的One-2-3-45模型提出了 “2D 多视角预测 + 3D 可泛化重建”将生成时间缩短到了45s,生成速度上在追赶3D原生派;
- 生成质量较低:NeRF更擅长合成视角而非精确重建,受限于采样数量、视角数量及计算资源的平衡,目前2D升维生成3D在分辨率、纹理细节都还比较粗糙,以及2D升维3D过程中的一些非理想效应的存在,导致整体的生成质量还有较大提升空间;
- 兼容性问题:NeRF格式无法直接在Unity等3D引擎中进行后续的编辑,也可以通过Matching cubes等方法转换成3D网格再到3D引擎中进行编辑,也有一些2D升维3D模型已经可以实现Mesh格式的导出,兼容现有3D管线,整体兼容性有所改善;
- 典型模型:Dreamfield、Dreamfusion(Google)、Point-E(OpenAI)、Magic3D(Nvidia)、ProlificDreamer(生数科技)、One-2–3–45
图:Dreamfusion(Google)模型原理图
能看到目前的3D生成模型存在一个明显的在生成质量、速度、丰富性之间的“不可能三角”: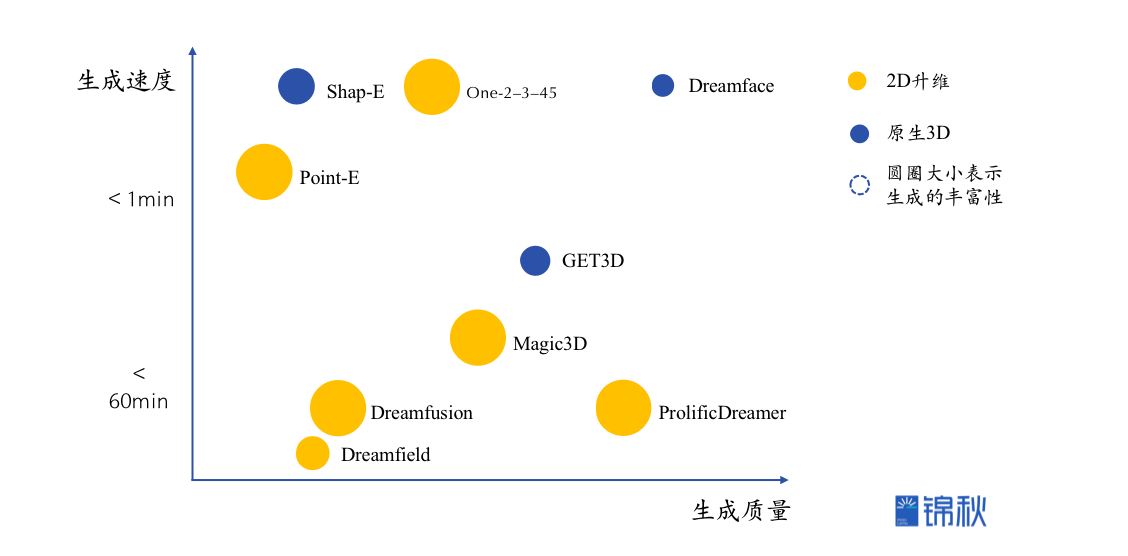
- “3D原生派”基本上保证了质量和速度,但是在丰富性上由于3D数据的匮乏导致了明显的短板,后续的重点发展方向就是通过自主采集或者开源共享的方式,在更多的场景、类型上丰富3D数据,逐步提高丰富性;
- “2D升维派”继承了2D图像生成的丰富性,而在第二个角上,我们看到既有ProlificDreamer这样生成质量让人亮眼的,也有One-2–3–45这样在生成速度上追求*的模型出现,生成质量和速度都在不断提升。
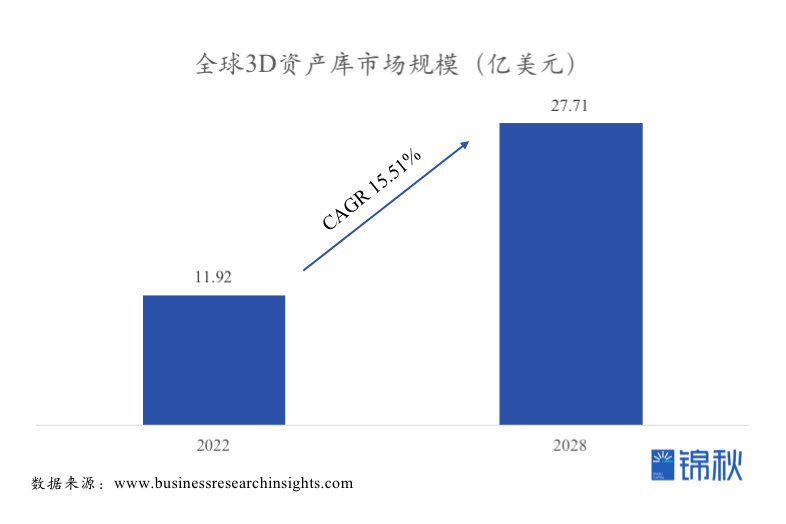
- 生成相比于购买在成本、效率上都能有很好的提升,技术成熟的情况下基本可以做到完全的替代,一如文生图对图库市场发起的进攻。假设五年时间做到技术成熟水平,可替代的3D资产交易市场规模~27亿美元。
- 通过公开数据和行业调研,我们大致假设:1)3D游戏占游戏类型的60%;2)美术占3D游戏研发成本70%(3D游戏美术成本通常比2D高);3)3D美术在3D游戏美术费用中占60%
单位:亿美元 2022A CAGR(%) 2028E 全球游戏市场规模 2000 5.5 3D游戏占比 60% 游戏研发占比 15% 美术费用占比 70% 3D美术占比 60% 3D研发成本 75.60 104.24 可以得到游戏在3D相关的研发投入当前大约在75亿美金,到2028年将会超过100亿美金,是AI+3D有机会触及的市场。除了游戏以外还有影视以及未来的XR都有大量的3D内容需求,综合来看AI+3D有机会触及的市场将达到数百亿美元。我们认为Midjourney的出现不会干掉Photoshop,我们看到的是Photoshop也在拿起AI的武器升级自己,同样的未来生成式3D的数百亿美金市场力里也少不了现有的Unity、Unreal、3ds Max等的身影,但我们更期待3D领域的“Midjourney”出现。 - 技术:当前仍处在3D生成的技术创新周期,技术上的创新能够带来产品上的极强竞争力。我们观察到目前跑出来的或者得到资本市场认可的AIGC应用几乎都是具备较强底层技术能力的团队,包括ChatGPT(OpenAI)、Midjourney(自研模型)、Runway(stable diffusion共同作者)、Character AI(Attention is All You Need的核心作者)等,技术在生成式3D的当前阶段仍然是核心竞争要素,缺乏底层技术能力的公司有可能会在未来出现Jasper AI的窘境;
- 产品能力:Midjourney在11人的情况下通过discord做到千万级用户、过亿美金年收入是被津津乐道的成功产品案例,Lensa、妙鸭也都是并不复杂的技术+成功的产品定义而在短时间成为爆款应用,面对一个新的技术物种,怎么去做好产品定义对于团队来说也是重要考验。
AIGC的产品面临几个重要的产品决策:1)如何设计User in the loop的数据反馈回路;2)自研模型的公司是选择闭源还是开源,产品型公司选择什么样的大模型底座;3)做生产工具还是做内容平台。让人兴奋的是过去半年多时间,我们已经看到越来越多在移动互联网时代操刀过千万甚至亿级DAU产品的产品经理也开始加入AIGC浪潮,让笔者对接下来的AIGC产品创新充满了期待。
最后一个绕不开的商业化问题是:对于3D生成的企业,2C or 2B?to C依然是AIGC最理想的商业模式,大家都希望像ChatGPT、Midjourney用自己的C端应用、有数据飞轮、再反哺底层模型的快速迭代。但受限于硬件终端,C端消费者能够直接消费3D的场景非常少,不像Midjourney用户会生成图片再到社交媒体进行展示,3D的内容消费需要通过游戏、影视等内容载体,因而短期来看更容易的路径是2B2C,通过游戏、元宇宙等B端场景触达C端,但往往数据回路在B端应用这里就被切断了;或者选择自研C端泛游戏类应用,比如“AIGC版roblox”、“3D版抖音”等,确保了对用户、数据的掌控,但对团队的产品及运营能力提出了比较高的要求。而还是那个观点,随着XR的发展,会有越来越多的游戏影视以外的3D native的应用可以被大众直接消费,而生成式3D将会从大幅降低3D内容生产门槛的角度,一起助推3D成为The next big thing。作为多年XR投资人和果粉,最后再放两张图带大家一起憧憬一下不远处的3D数字世界👇🏻
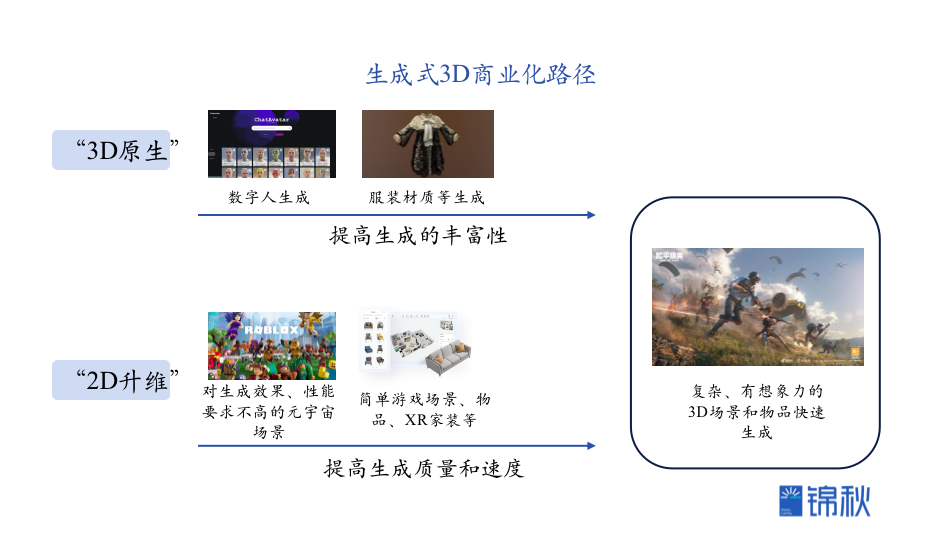
三、生成式3D的商业化路径和市场潜力
当前的生成式3D存在的问题好比一年前的文生图,V1、V2的Midjourney的生图质量、可控性和可编辑性离商业化看似遥不可及,而短短一年多时间设计师们就要开始惊呼“失业”了。笔者认为上述“不可能三角”的问题同样有机会在未来一年内逐渐取得突破,并开始生成式3D的商业化之路。

四、谁能成为3D的“Midjourney”?
大模型的创新下文字和图片的生成都已经进入到应用蓬勃创新的阶段,也出现了很多从收入和融资上都很优秀的公司,即便是尚未大规模商业化有PMF的视频生成领域也有Runway这样受到市场高度认可的独角兽企业。但反观生成式3D从商业化和市场认可角度这样的公司市场仍旧在虚位以待。

图:Vision Pro演示的3D交互画面

参考资料:
- 《DreamFusion: Text-to-3D using 2D Diffusion》
- 《GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images》
- 《Magic3D: High-Resolution Text-to-3D Content Creation》
- 《Shap-E: Generating Conditional 3D Implicit Functions》
- 《Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold》
- 《Drag3D: DragGAN meets GET3D》
- 《MotionGPT: Human Motion as a Foreign Language》
- 《GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents
《无需任何3D数据,直接文本生成高质量3D内容,清华朱军团队带来重大进展》机器之心
《3D AI生成出新玩法了:无需数小时,只要45秒,单张图片即可生成 3D模型》机器之心
《Learning an Intrinsic Garment Space for Interactive Authoring of Garment Animation》米哈游等,服装动画解算
《游族称AI让2D美术降本25%、明年发布三体游戏,上市公司密集谈AI》GameLook
《次世代3D游戏角色的制作流程》游鲨游戏
《一句话实现3D内容制作,Unity上线AI工具「Muse Chat」,美股飙升15%》机器之心
《惊艳!全球*文本生成高质量3D模型,效果媲美玛雅、C4D!》AIGC开放社区
《Synthesis AI可通过文本提示创建逼真虚拟数字人》映维网
《关于3D AIGC 的务实探讨——从学术研究到商业落地》太极图形
《生成式AI对于游戏的研发变革以及产业要义》广发证券
《苹果Vision Pro开启新时代,计算机从2D到3D,三维内容生态迎万亿蓝海》36氪
《AI+游戏会议纪要》腾讯手游助手
《凌迪科技Style3D:让AIGC走上秀场背后,是打造服装产业模型的决心 》










