难以捕捉的蝴蝶
世界范围内通行的对天气预报的方法被称为数值计算,采集足够多、足够丰富的气象数据后,把它们代入复杂方程,得到的结果就是所谓预测,重复这个过程,预测就连续了起来。
这些方程背后是一些坚固的理论,比如流体运动方程,热力学方程和不同介面,气、水、陆冰物质能量交换方程等等,它们代表的物理、化学规律是经过严密的计算和验证的。
但天气预报依然做不到*的准确。这种数值预测,是通过已经发生的气象要素的变化推测未来的趋势,它的准确程度严重受到观测数据精度的影响。
更何况,随着时间、空间尺度的变化,气象系统的复杂性将会剧烈增长,分析气象的成因时一方面会挂一漏万,另一方面数据的误差也会更多,这又反过来影响了预测的结果。
而当尺度大到一定程度时,气象会进入一种混沌状态。这不是比喻,气象系统是典型的混沌系统,混沌理论最早就是气象学家在1963年提出的。
混沌系统意味着系统非常小的扰动也可能造成巨大差别的后果——它的另一个名字叫蝴蝶效应,加利福尼亚的蝴蝶扇动翅膀,德克萨斯和墨西哥湾将掀起一场风暴。
这就要求对数值最开始的测算必须非常精确,然而我们都知道*的精确是不存在的,更何况面对如此复杂的气象运动,要采集的数据种类和数量实在太多。
人类对天气的预测就像努力学习蝴蝶的翅膀同风暴眼移动轨迹之间的关系那样,既壮丽,有时又有些绝望,甚至还带有一种玄奥的成分。
一面在精确度上构建越来越复杂的函数方程组,尽可能收集更多、间隔更短的数据,另一面则依赖一种近乎是“直觉”的经验。
时至今日,所有的天气预报结果依然由两部分决定——数值计算的结果,加上预报员的判断。天气预报依然高度依赖人的经验。
某种程度上,人类在用自己的感觉,对抗大自然的混沌。
超级计算机
因此气象预测呈现出一种诡异的特质——因为只要依靠人类的经验感觉,那么总会遇到失灵的时候,在一些极端气候中更是如此,因为有关极端气候的数据太过稀少,导致人对它无法形成连贯的经验。
但随着数值预测精度几十年来的提升,目前的天气预报在许多时候已可以达到相当准确的程度,中期可用性预报时效已经接近10天,而短期的预测——比如说冷空气什么时候到来,会降温多少度,人类已能判断的十分精准。这是因为尽管总体上全球的气候环境变化是混沌的,但在许多微观层面,比如气团的形成,气压的变化,云层运动的轨迹,正在被越来越多的函数和公式形象而准确的描述。
比如最近在京津冀肆虐的暴雨。
7月29日到8月1日,台风杜苏芮带着丰富的水汽北上,在华北遭到高压拦截,京津冀地区出现了历史罕见的极端暴雨。
极端体现在几个方面,首先是量大。河北邢台临城县降雨量超过1000毫米,也就是1米,等于这里原本两年降水量的综合。其次是时间长,从7月29日开始一直绵延了近四天,连北京都连续下了83小时的雨。河北、陕西、河南等地也连续两天出现大暴雨。最后是影响范围广,整个华北都被阴雨笼罩。
天气预报几乎完全准确地预告了这场极端降雨的到来。这背后是天气预报几十年来的巨大进步——数值计算已经从简单的方程组发展成世界上最复杂的算法之一,毕竟,对莫测的天气的捕捉,数据和算法都是越多越好,而为了处理这海量的数据和复杂的算法,超级计算机被引入。
许多人可能对气象数据的庞大没什么概念,在这里可以举一个数字:每一天,中国的气象数据增长高达40TB。我国建立的一整套立体的天气观测网络,有7万多个气象观测站覆盖全国99.6%的乡镇,这些数据传输的时间从过去的1小时近年来缩短为1分钟。
如此巨量的数据本身处理起来就已颇有难度,而把它们同数值计算的方程结合起来,则几乎是不可能完成的任务——复杂的偏微分方程和浮点计算都需要消耗大量的算力,特别是天气预报还要求极高的时效性,种种条件约束下,只有超级计算机能够满足需求。
所幸,中国在这方面走在世界前列。
超算一直是一张中国名片,比如全世界最快的500台超级计算机,中国就占了162台;再比如我过三次获得国际超算应用最高奖——戈登·贝尔奖,其中的两次获奖内容“大气动力框架”和“地震模拟”都和气象有关。
目前中国使用的超算名叫“派—曙光”,它峰值运算速度达到每秒8189.5万亿次,存储能力达到23088TB,这套完全国产的超算2018年开始服务后,我国高性能计算机系统总体规模已经跃居气象领域世界第三位。
这还不算完,随着数据量快速增长和硬件的磨损,超算的服役年限多在6到8年,因此在“派—曙光”之后,新的超算也在陆续上马,今年*批新国家级高性能计算(HPC)子系统1已经安装建设完成,它的性能相比“派—曙光”进一步提升,达到13PFlops,储存能力也增长到了76PB。
更多的超算还在路上。
国产高性能计算机系统“派—曙光”概念图,图片来自国家气象信息中心。
“停滞”与新路
总的来说,成百上千颗CPU组成的超算构成了天气预报坚实的基础,但它仍有不能做到、或者很难做到的事情。
比如台风。我们对台风杜苏芮的预测,远没有达到对特大暴雨预测的精准程度。国际上主流的台风预测方式均采用了动力模型,它根据大气物理定律,包括流体动力学和热力学等来模拟大气运动,进而预测台风的变化。
动力模型有许多不准确之处,这让大家一开始对杜苏芮的路径预测五花八门,这个领域公认比较权威准确的欧洲中期天气预报中心一度认为杜苏芮会直冲珠三角。
事实上,台风预报一直是个世界性难题,因为台风在很短时间内可以发生剧烈的强度变化,而它的路径又由于处于非常大的时空尺度上,受多种因素影响而显得变幻莫测。
它是一个典型的混沌系统。
由此数值预测为主的天气预报成为了一种矛盾的综合体,这让它能提升的空间尽管巨大,但又十分受限——人们逼近准确性的方法除了积累经验,只有尽可能多地收集数据和构建越来越复杂的函数,但它的边际效益正在越来越强的显现,更多的数据并不能大幅度、全面地提升天气预报在宏观和微观尺度上的准确性,而通用计算的成本却在持续增长。
到此处,情况仿佛陷入了一个僵局。海量数据,复杂算法以及高算力需求,让数值计算某种程度上走向瓶颈,但这三个条件看上去是不是有点眼熟?
似乎有点像大模型的三个要素?
实际上,在品玩看到的某个气象技术内部研讨会资料上,有专家直接宣称:人工智能和气象工作在方法论上是相通的。
既然数值计算的公式实际上并不能穷尽整个混沌系统里的所有因果,为什么不用神经网络的方法,把海量的数据导入其中,让计算机自己来寻找和学习其中的规律?
这看上去像是一种不可言说,又异常玄妙合理的解释。
人类的*台电子计算机ENIAC埃尼阿克和*台根据冯·诺依曼结构打造的计算机EDSAC实际上都用来进行过气象学相关的科学计算,气象学的发展始终和计算机科学的进步紧密连接——高性能计算推动了气象科学的复杂问题的解决,而跳出通用计算的思路后,神经网络和大模型看上去是气象学和天气预报的一个非常有趣且合情合理的方向。
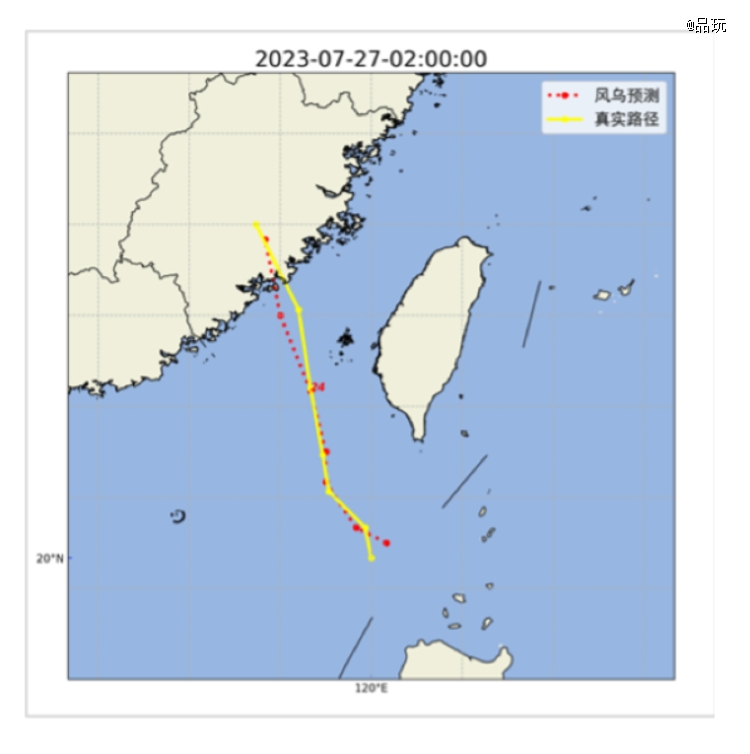
实际上,这次对杜苏芮台风轨迹的预测,中央气象台就参考了人工智能大模型的结果。
另辟蹊径
气象大模型并不是随着去年底生成式AI的火爆才出现的,一直以来利用强大算力、巨量数据和各种深度学习架构来预测天气的大模型就有很多,在国外比较有名的有英伟达FourCastNet,DeepMind和谷歌的GraphCast以及微软的ClimaX,国内最近出圈的则是华为盘古大模型和上海风乌大模型,后者来自上海人工智能实验室。
盘古和风乌都使用了欧洲气象中心名为ERA5的气象再分析数据集,它提供了过往60余年,覆盖地表37个等压面的各种气象数据共2000TB。
这些数据给大模型提供了发挥的空间——不再使用精准对应的数值计算,而是让AI更灵活地去挖掘数据之间的各种复杂关系。
盘古构建了一个3D transformer 结构,让海洋、大气和陆地的复杂交互物理过程融为一体,而过往的气候大模型,比如英伟达的FourCastNet则都采用的2D结构——每个等压面为一层,显然,2D平面没有办法更好反应气象变化的过程。
根据品玩看到的材料,华为在这个3D 结构中使用了*位置编码,由此明显加速了模型的收敛,此外,华为训练了四个基础模型分别对应1小时、3小时、6小时和24小时的预测,通过时域融合的方法显著减少了过往模型中由于小步长、多次迭代造成的误差。
对于预测老大难台风,盘古使用了平均海平面气压作为预测基准,其结果比欧洲气象局更好。
风乌大模型的思路则是用6个独立的编码器对不同的气象参数(湿度、风、温度等)进行编码解码,不同变量之间用独立的transformer网络进行学习。
同华为时域融合减少误差的方式不同,风乌设计了一个缓存空间用来储存和回放训练过程中的结果,以让神经网络适应其误差,从而实现了更好的预测效果。
这些新的气象大模型预测的效果,尽管目前的成果还很初步,公布的成绩也是在一些具体指标上好于传统数值预测方法,尚需全面的测试和优化,但毋庸置疑它们代表了一种迥然不同于传统气象预测的新范式。
目前,华为的盘古大模型已经在欧洲中期天气预报中心实现了初步业务运行,而风乌则宣称是目前最精准的全球高分辨率AI气象预报模型,提前24小时对杜苏芮预测的误差值为38.7公里,精确度优于欧洲中期气象预报中心的54.11公里。
漫漫前路
变革即将来临。气象大模型在许多方面都很有可能颠覆气象预报模式,比如说速度。风乌用一张GPU在1分钟内就能生成未来14天全球所有地区37个层级高精度高分辨率气象预报结果,而盘古的7天天气预报生成时间只需要9.8秒。
为数值计算所建立的实时天气数据传输系统和通用算力基础设施将会因此改变。根据品玩了解到的气象局内部人士观点认为,尽管短期内还仅仅作为一种预报参考,但中长期看,气象大模型潜力无疑十分巨大。
现在,这些气象大模型主要面对的问题或许有两个方面,首先是调优。极端气候等数据如何在大模型中被正确标注是一个问题,AI模型的拟合能力很强,因此在长期预报中有可能出现错误,这或许可以称之为气象大模型的“幻觉”。
另外,目前的大模型还没有更深的行业 know how 储备,模型的构建都由计算机科学家,而不是气象专家完成,也就是说这些垂直大模型还缺乏“人类反馈”调优。
另一个问题则是老生常谈的算力,虽然我国在超级计算机发展方面位居世界前列,但大模型所使用的并不是传统超级计算机的通用算力,深度网络的运行需要大规模的并行计算,也就是高性能GPU,在这方面我们仍处于卡脖子状态。
所幸气象大模型所直接涉及的算力成本并不高,根据品玩了解到的情况,几十张英伟达显卡(甚至不需要*进型号)就可以在几周,至多2个月的时间内完成模型的训练。这也成为它相较于传统数值预测模式的一个优势。
在气象大模型加持下,“天有不测风云”这句话或许很快将成为一个伪命题,而有一天,或许我们真的可以同时预测那扇动的蝴蝶与狂暴的飓风究竟来自何处,又要去往何方。