

招*秀的人才,打最硬的仗,出手即打破传统。
这就是华为最新揭秘的大模型领域最新动作,剑指AI存储,一口气发布两产品:
OceanStor A310深度学习数据湖存储与FusionCube A3000训/推超融合一体机,性能密度刷新业界纪录。
它们由华为数据存储团队推出,华为“天才少年”张霁正是其中一员。

2020年,博士毕业于华中科技大学的张霁,以“天才少年”身份入职华为、加入数据存储产品线。如今是华为苏黎世研究所数据存储首席科学家。
在发布会上,他还进一步揭开华为天才少年的神秘面纱,透露了自己正在推进的工作:
围绕以数据为中心的未来存储架构关键技术,包括向量存储、数据方舱、近存计算、新应用场景下的数据存储新格式、硬件加速等。
显然,不只是大模型本身,在大模型相关的数据、存储等领域,华为也早已开始积极布局,启用最*人才。
而面对大模型时代的数据存储问题,华为作为存储市场头部厂商,究竟如何看待?
从最新发布的两款产品中,就能窥见答案。
面向大模型的存储应该长啥样?
此次发布的新品有两款,分别是:
OceanStor A310深度学习数据湖存储
FusionCube A3000训/推超融合一体机

虽然都是面向AI大模型,但是两款新品对应的具体场景有所不同。
首先来看OceanStor A310,它面向基础/行业大模型数据湖场景,可以贯穿AI全流程,同时也具备面向HPC(高性能计算)、大数据的同源数据分析能力。
它不光性能强大,而且支持混合负载、多协议无损融合互通、近存计算等,可极大程度上提升效率。
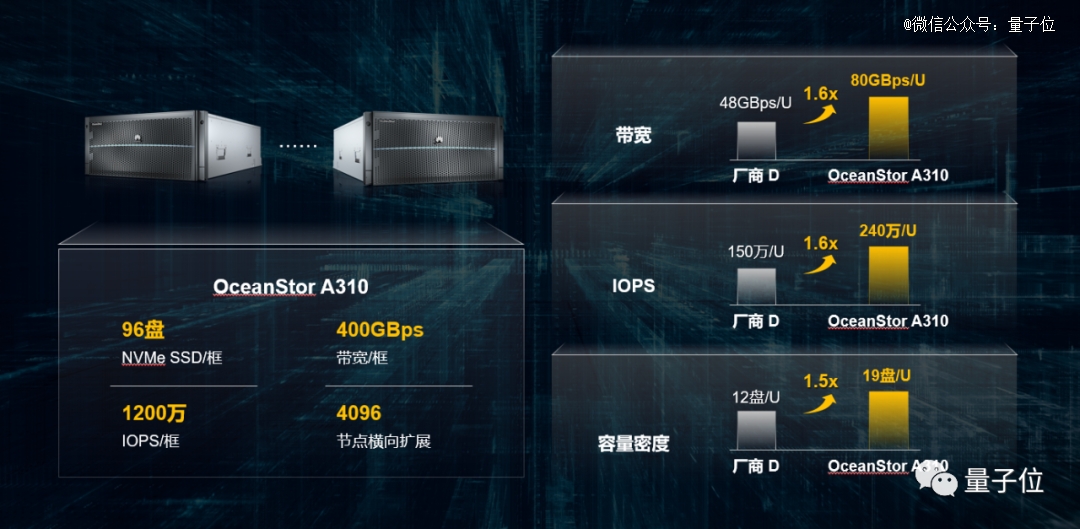
具体性能方面,OceanStor A310支持单框5U 96闪存盘,带宽可达400GB/s。通俗理解,就是每秒钟能传200多部高清电影。
IOPS(每秒进行读写操作的次数)能达到1200万。
由此OceanStor A310的性能密度也达到了目前全球最高:
每U带宽性能达到80GB/s及每U的IOPS达到240万,均达到业界标杆1.6倍;
每U容量密度为19盘位,达到业界标杆1.5倍。
而且OceanStor A310具备*水平扩展能力,*支持4096节点扩展。
可以实现对AI全流程海量数据管理(从数据归集、预处理到模型训练、推理应用);实现数据0拷贝,全流程效率提升60%。
除此之外,OceanStor A310还通过存储内置算力,减少无效数据传输。实现数据编织,也就是通过全局文件系统GFS来支持AI大模型分散在各处的原始数据,实现跨系统、跨地域、跨多云的全局统一数据调度,简化数据归集流程。
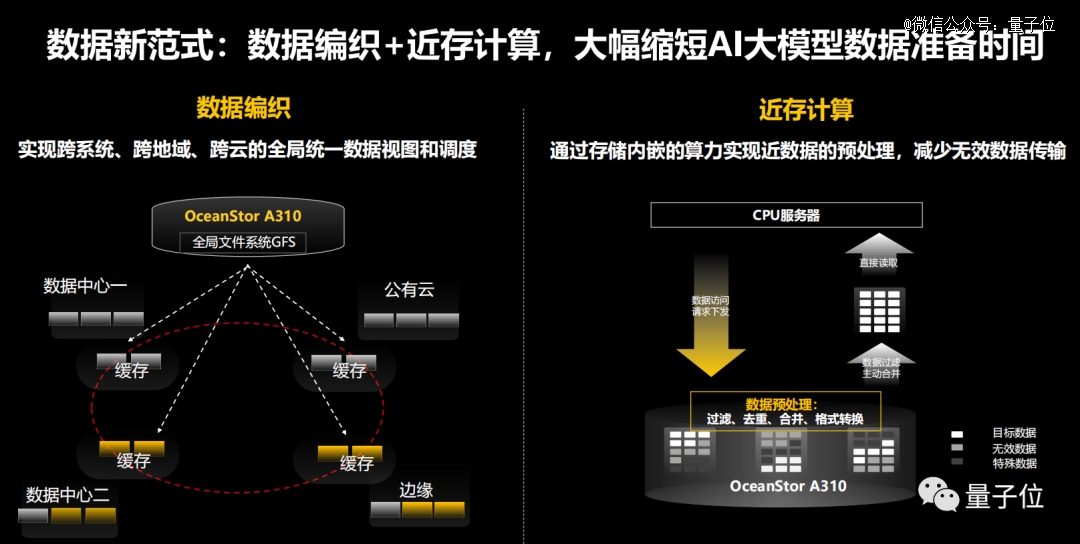
基于近存计算,OceanStor A310还能通过内嵌算力实现数据预处理,避免数据在传统的系统当中存储、服务器、GPU之间的无效搬移,降低服务器等待时间,预处理效率提升至少30%。
另外,OceanStor A310能直接使用到当下的HPC中,如果之后企业需要将系统升级到面向大模型时,就不再需要数据搬迁。
再来看FusionCube A3000训/推超融合一体机。
相对而言,它面向的场景是行业大模型训练、推理一体化,主打降低企业使用AI大模型的门槛。
它主要针对百亿级模型的应用,当然也可以水平扩展后支持更大规模模型。
内置的存储节点是华为的OceanStor A300高性能存储节点。它双控支持180万IOPS、50GB/s带宽。

结合训/推节点、交换设备、AI平台软件与管理运维软件一起,FusionCube A3000可以实现一站式交付、开箱即用。2个小时内可完成部署、5秒故障检测、5分钟故障恢复。

在实现边缘部署多场景的训练/推理应用业务的同时,它也能定期对模型进行调优。
通过高性能容器实现多个模型训练推理任务共享GPU,FusionCube A3000将资源利用率从40%提升至70%以上,能够很好支持多应用融合调度和管理、不同大小模型融合调度。

商业模式方面,FusionCube A3000有两种选择。
其一是基于华为自研的OceanStor A300高性能存储节点、网络、昇腾计算与管理运维软件,即华为昇腾一站式方案;另外也支持第三方一站式方案,可以集成第三方的GPU服务器、网络节点以及AI的平台软件。

以上就是华为最新面向AI存储发布的新品。
此外在模型层,他们还联合了讯飞星火、ChatGLM、紫东·太初等大模型伙伴共建生态。
但华为的雄心不止于此,在发布会现场,华为数据存储产品线总裁周跃峰特意和华为天才少年张霁,聊了聊华为存储未来的事。

据张霁介绍,为了应对当下大模型提出的数据归集新挑战,他及所在团队正在研究一种名为“数据方舱”的技术。
这种技术实现了让数据和它的相关凭证、隐私、权限等信息一起流转,当数据达到数据归集地后,进入方舱执行和保护,从而保证数据的安全。
周跃峰博士透露,这一技术目前正在和中信银行、云上贵州等客户做联合的技术创新和实践。
此外,为了应对AI大模型快速接入数据的需求,张霁等也在基于“万物皆可向量”的理念,研究向量存储技术。
他表示目前这种技术还处于早期萌芽阶段,但是发展迅速,华为已做了非常前沿的布局。比如他们联合华为海思硬件团队一起,在近存计算方面做了很多攻关,利用软硬协同的方式加速向量检索。同时华为也在和苏黎世联邦理工大学等*高校合作。
目前,张霁与其团队正在瑞士苏黎世研究所与苏黎世联邦理工大学Onur Mutlu教授等*科学家们开展研究与合作。
Onur Mutlu教授曾带领团队荣获2022年奥林帕斯奖,这一奖项颁给全球在数据存储领域取得突破性贡献的科研工作者。
正如张霁所说,他们的目标是希望在以数据为中心的体系结构变革背景下,利用算法和架构协同的方式,释放数据的真正价值,卸载部分GPU、CPU的算力,节省无效数据搬移产生的能耗,从而最终推动数据新范式的快速发展。
所以,为什么是以数据为中心?华为存储看到了哪些行业趋势?以及在大模型趋势下,华为为何如此重视存储问题?
存储:大模型生态的重要一环
在大模型时代下,有这样一句话广为流传:数据以及数据质量的高度,决定着人工智能智力的高度。
的确,大模型所谓的“大”,核心体现就在数据方面。
当下企业开发及实施大模型面对的几大挑战也都与数据有关:
数据准备时间长
训练集加载效率低
训练易中断
企业实施门槛高
首先在数据准备阶段,往往需要从跨地域的多个数据源拷贝PB级原始数据。原始数据经常是多种格式、协议,导致这一流程一般十分复杂。
接着,爬取好的数据在训练前需要进行清洗、去重、过滤、加工。
相较于传统单模态小模型,多模态大模型所需的训练数据量是其1000倍以上。一个百TB级大模型数据集,预处理时间将超过10天。
其次在训练阶段,大模型训练参数、训练数据集呈指数级增加,其中包含海量小文件。而当前小文件加载速度不足100MB/s,效率不高。
另外大模型频繁的参数调优、网络不稳定、服务器故障等多种因素,导致训练过程平均约2天就会出现一次中断,需要Checkpoints机制来确保训练退回到某一点,而不是初始点。
但这种恢复往往也需要1天以上时间,直接导致大模型训练周期拉长。而面对单次10TB的数据量和未来小时级的频度要求,减少Checkpoints恢复时间也是一个需要解决的问题。
最后一方面挑战来自大模型应用。
在应用门槛上,系统搭建难、资源调度等对于很多企业来说还是太难了,企业传统的IT系统GPU资源利用率通常不到40%。
更何况目前趋势还要求企业尽可能快速更新大模型知识数据,快速完成推理。
那么该如何解决这些问题?
华为已经给出了一种答案,从存储入手。
华为数据存储产品线总裁周跃峰博士表示,数据中心三大件“计算、存储和网络”,密不可分、可以互补。
华为分布式存储领域副总裁韩振兴更是给出了明确观点:加强存力建设可以加速AI训练。
得出这样的结论,华为表示主要看到了技术、行业等多方面趋势。
首先在技术方面,大模型时代下,冯·诺依曼架构难以满足当下需求。
它要求数据在计算、训练或推理过程中发生非常多搬移动作。在数据量非常庞大的情况下,这样操作不合适。
周跃峰博士表示,比尔·盖茨在很久以前说给一台电脑128k的内存,它能做所有事。
但是当下情况显然不是如此,数据量还在不断增加,存储与计算的增配需求差异随之扩大,这时存储资源和计算资源就需要拆分成独立模块建设,以实现灵活扩展并提高资源利用率,因此计算架构需要发生改变。
这也就是近年比较火热的“存算分离”概念,在存和算之间做出更好的划分,这样才能实现更高效的计算、匹配海量数据下的大架构创新。
大模型时代下数据量*增加,如果构建充足的存力让数据能快速在各个环节流转,可以充分利用算力、提高训练效率。比如华为在AI存储新品中强调的近存计算,正是这样来互补算力。
再来看行业方面。
海量数据预处理是当下面临的一大挑战。
周跃峰观察到,有人提出用训练的GPU资源去处理这部分任务,“但这样会给GPU提出更高要求,更何况目前还面临供应问题。”
目前国内的存算基础设施建设中,算力中心建设相对完善,但在存力建设方面仍然短缺。这就导致在数据预处理等阶段中,为了等待数据处理,算力闲置的情况,造成资源浪费。
所以当下需要去重视存力,以在行业内形成一个*的存算比。
此外,华为还观察到对于一些中小企业、科研院所、大学对训练AI大模型有着很大的需求,他们对存力设施搭建,还提出了更加简易、灵活的要求。
由此也就不难理解,为什么华为在大模型趋势下会锚定存储方向发力,而且率先推出OceanStor A310和FusionCube A3000。
而且对于AI大模型的存力需求,华为看到的时间也更加早。
据透露,两款产品的筹备研发都是在2、3年前就已经启动的,当时千亿级参数大模型才刚刚问世不久。
并且除了推出自家新存储产品外,华为格外强调了生态建设。
正所谓:独行快,众行远。
华为表示,在提供AI存储的过程中,坚持硬件及软件生态的开放。
硬件方面,华为未来会全面支持业界主流CPU/GPU厂商设备,做好性能适配与调优,并提供不同形态硬件的统一管理能力,兼容用户现有硬件生态。
软件方面,广泛与业界优秀软件伙伴合作,提前完成方案适配调优;模型层支持业界主流的通用大模型软件,同时支持面向具体应用场景的垂直行业模型入驻;平台服务层支持主流AI开放平台软件和AI服务链软件,包括昇思MindSpore、PyTorch等;IAAS层开放支持第三方容器软件和开源K8S。
一言以蔽之,当下的最新动作,是华为存储在大模型时代下掀开的*页。
所以,如今已经站在起跑线上的华为,究竟如何看待大模型时代下的存储?
中国不重视存力,AI会被制约
大模型趋势演进到当下,“百模大战”、算力焦虑先后成为业内的热议话题。
还有一大基石,则是数据,如今也已被逐渐推至台前。
周跃峰博士分享到,对于ChatGPT来说,英文数据训练的效率要比中文高。
原因不在于中文不适合科学语言表达,而是数字化时代下,被记录下来的中文资料远远少于英文资料。
所以周跃峰提出:如果中国不重视存力,将会对未来我们挖掘人工智能潜力、发展人工智能产业,造成巨大制约。
如果更进一步解释的话,他认为机器和人一样,它需要有脑力,即算力;还要知道方法论,即算法。
回顾人类从猿猴发展到智慧人类的过程中,文字的产生让人类文明飞速发展。
如果对应来看,机器的数据可以堪比人类发展史中的文字。
因为有了文字后,信息得以被记录、交流和传承,人类开始可以自我学习和进化。机器也是一样的,如果世界没有被数据记录下来、让机器去读,它也只是一个冰冷的机器而已。
总之,大模型趋势下,关于数据、计算、存储都正在经历一轮新变革。
高性能计算的“木桶效应”,使得用上了先进的芯片,并不代表具备先进算力,计算、存储、网络三个环节缺一不可。
由此也就不难理解,华为为什么要在进军大模型领域后,率先在存储领域布局。
只有从基础入手,才能走得更稳,走得更远。










