

万万没想到,B站崩了,让全互联网经历了一次深夜狂欢。
7月13日23时左右,B站主站、App、小程序均出现访问故障,无法正常使用,页面提示“正在玩命加载数据”。而B站的邻居A站,以及晋江、豆瓣也出现不同程度的故障,加载显示404、502等。
B站崩了,才让大家发现原来“小破站”的流量如此惊人。上不了网站、没得看视频直播的“B站难民”冲向知乎、微博以及著名游戏网站NGA。“b站崩了”“陈睿”“豆瓣崩了”等词迅速走红,甚至连B站名梗“蒙古上单”也一同霸榜微博热搜,传遍全网,颇为壮观。
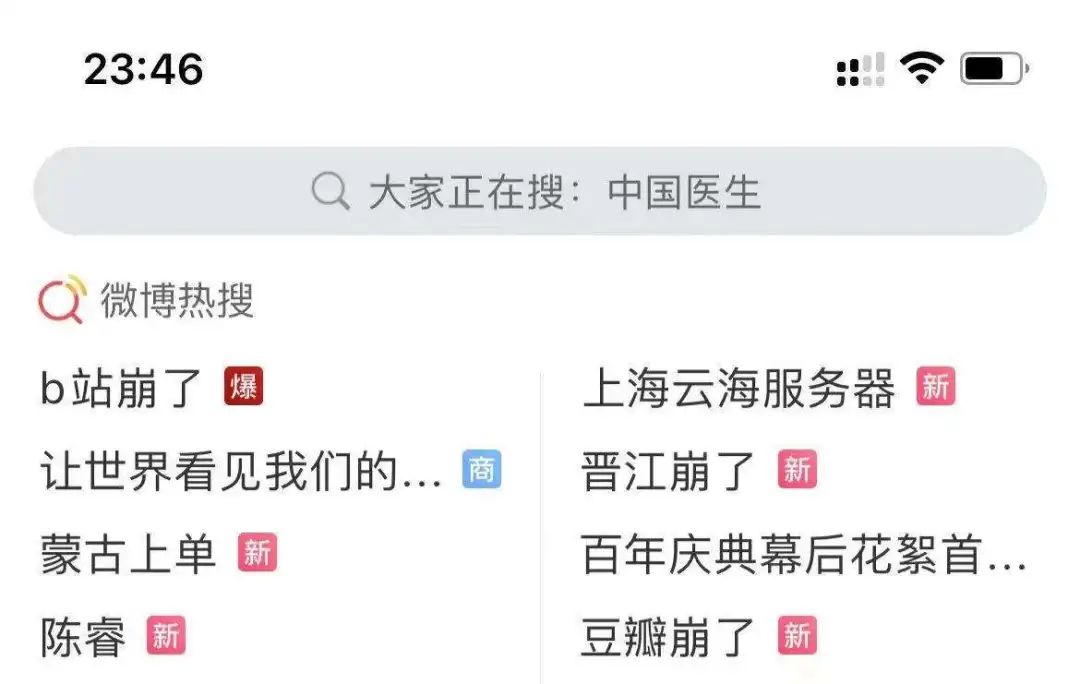
微博热搜
23时45分,B站网页端和App才初步恢复正常访问,但像直播、会员购等板块,以及一些站内互动、评论、投币功能,还无法正常使用。
B站崩溃后,许多故障页面截图在网上流传。但具体是什么导致服务器故障,多种说法迅速出现。不过,无论是最初的停电说,还是后面的B站大楼/上海云海服务器中心着火说,都被迅速辟谣。
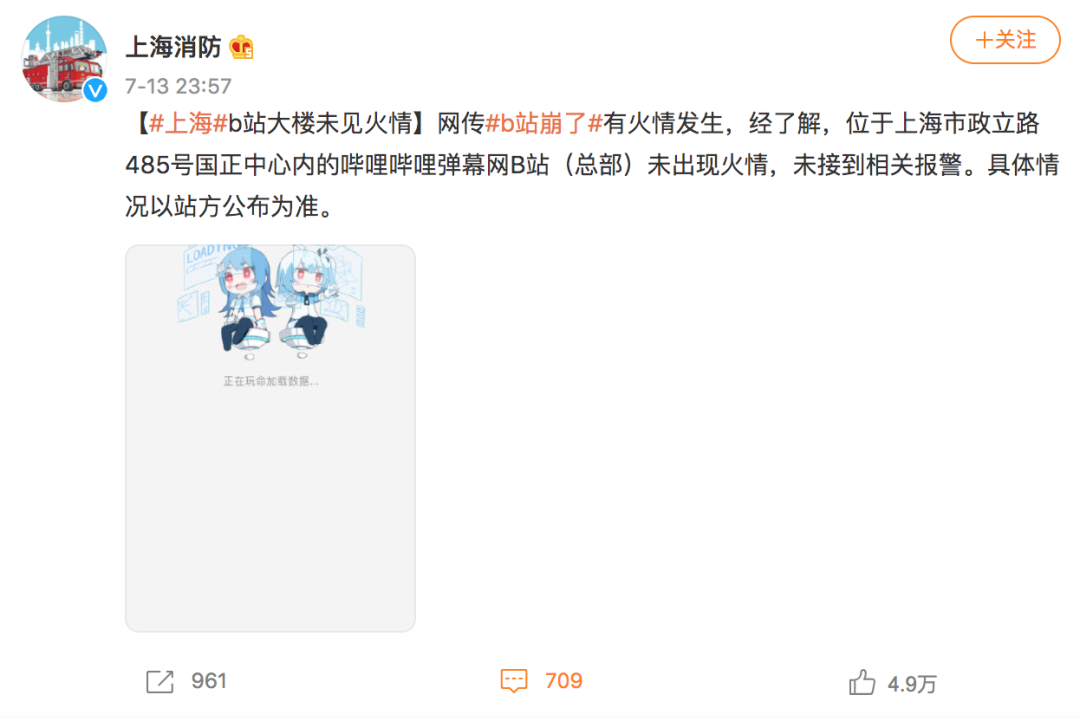
上海消防对B站总部大楼着火一事辟谣
直到凌晨2点20分,B站正式发布声明,表示因部分服务器机房发生故障,造成无法访问,经过排查修复后,现已陆续恢复正常。不过,更具体的原因是什么,B站还未披露。
服务器崩溃数小时,灾备没做好?
企业IT架构越来越复杂,这也意味着故障原因往往是系统性问题,难以单一归因。此次B站崩溃,除了服务器出问题,补救的备份方案大概率也没有快速应用到位。
故障通常可从硬件故障和软件故障两方面来分析——硬件故障即是机房、服务器等物理因素;而软件故障则有可能来自版本升级、代码bug等带来的影响。
尽管不同行业有差异,但大互联网平台的技术架构,核心组件基本不会少。最简单的访问路径就是客户端和网站直接交互,比如一个视频访问请求从客户端发出,经过一系列处理后到达B站的前端、后端服务器、分布式存储等多个组件,B站处理完请求后再返回。
而当晚的情况是,B站崩溃,网友们收到的页面大多显示502,基本可以确定是服务器故障导致。
但具体是哪些服务器故障,目前还不清楚。B站这般体量的视频平台,上云是肯定的,也都会采用公有云+私有云架构。也就是说,出故障的服务器有可能在B站自己或托管的机房,也有可能在公有云服务商的机房。
若自家机房出问题,一个可能原因是,版本升级、网站维护失败,导致用版本回滚紧急解决。若没上云的刚好是核心业务,还需要运维人员手动修复,耗时就很长了。知乎答主“k8seasy”就认为,B站核心业务恢复时间在30分钟左右,并且几乎100%恢复,说明应是B站某个核心组件崩溃,导致核心服务不可用。有可能的原因是B站上线新版本时有bug,不可用后,紧急回滚到老版本也没扛住访问压力,最后网站环境崩溃。
若公有云厂商出问题,那么同一个服务器集群服务的其他企业,也会出现类似问题。但当晚的A站、晋江、豆瓣等大流量app都很快恢复了服务,故障程度和B站也不是同一个量级。再者,为B站提供云服务的厂商包括阿里云、腾讯云、京东云、华为云等,公有云厂商一起出问题的概率是极小的。
分析完原因,再来看补救措施。服务器崩溃后的*道防线,是企业的容灾和备份,这能够保证核心业务尽快恢复,*程度减少损失。
B站当晚故障数小时也没完全恢复,显然灾备起的作用不太大,这道防线没能好好守住。
灾备等级一般可按同城/异地、备份中心数量等划分等级高低,选择不同备份方式(如热备/冷备/温备份,成本均不同),也会对恢复时间有所影响。一位云计算从业者对36氪表示:“B站这种体量的平台,灾备肯定有做,但就是没经受住考验。比如数据备了但机器没备,或者机器备了但链路没备,差一个环节,就难以在短时间内恢复。”
作为视频直播平台,B站对高可用/高并发的要求是很高的。企业灾备服务商、英方软件市场总监黄亮对36氪表示,高可用架构主要有异地容灾、负载均衡两种,此次故障很有可能是B站只重点做了负载均衡,但没有做太多异地容灾。“当前企业做负载均衡,通常是采用同城数据中心的架构,如在上海的同一个数据中心里进行。”他表示。
灾备没及时起作用,可能是出于成本考虑。黄亮表示,负载均衡对实时性要求高,如果要上异地灾备,成本是很高的。比如,A企业在上海有数据中心,同时在贵州设立异地灾备中心。当上海机房宕机,贵州可以接管。对稳定性要求较高的行业,如银行、医院等,监管会有强制要求,其他企业一般是量力而行。
脆弱的企业IT架构,未来要如何演变?
B站此次故障,从虽然恢复时间达数小时,但幸运的是,故障发生在深夜的流量低谷,网友们的助推则让B站再次出圈:一个网站崩溃,其巨大流量竟能让其他网站也跟着出现故障。
这让市场看到了B站用户可怕的冲浪能力。7月13日,B站股价经历短线走低,盘中一度涨幅收窄,*至3.26%。截至收盘还能保持涨幅3.18%,报110.38美元/股。截至发稿,B站市值为417亿美元。
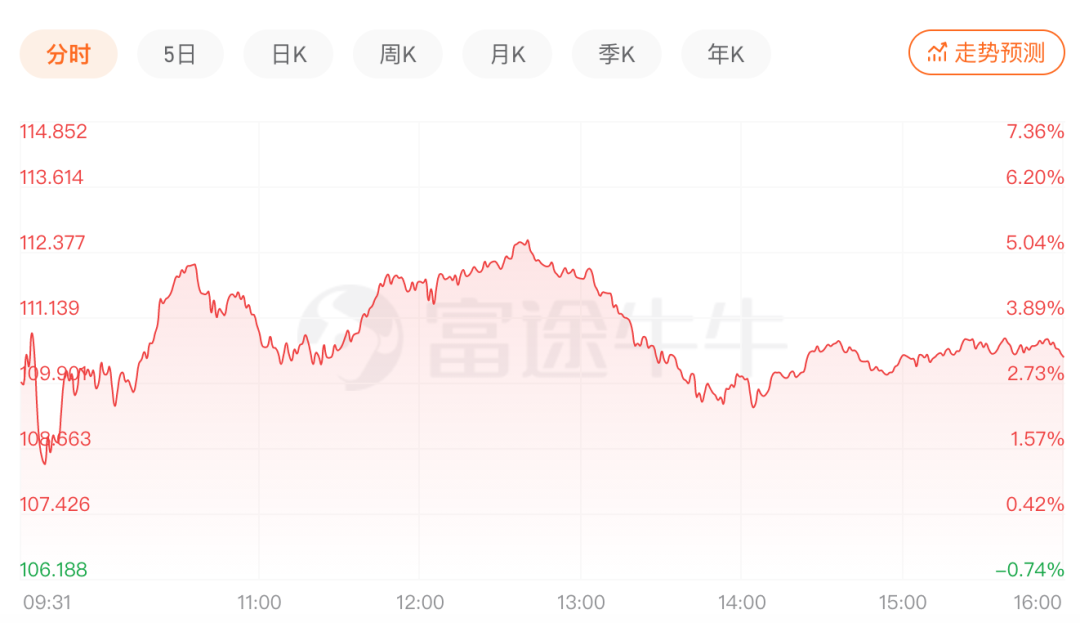
7月14日B站股价走势 来源:富途牛牛
类似这样的宕机事件,突显出当下企业IT架构的脆弱。随着数字社会越来越成熟,企业IT架构一环扣一环,一个环节出现问题,就有可能一发而动全身,造成巨大损失。
信息安全问题也是防不胜防。2020年,微盟一核心运维员工对核心生产环境和数据进行删除,最后微盟公司花费超过2260万元用于支付数据恢复、商务赔偿、员工加班费用等。因删库事件,微盟股价跌幅超过8%,一夜损失将近11亿元。而2019年3月,谷歌云、阿里云、腾讯云就相继发生大规模宕机,腾讯云宕机的4小时内,仅腾讯游戏就损失高达千万元。
企业安全是实战出来的。经过微盟删库一事后,恐怕当前国内企业不会再给运维人员如此核心的权限。阿里云也是在经历支付宝527光纤挖断事件后,痛定思痛将可用性再提升一个数量级。
那么,如何考虑放在灾备中的运维成本?企业首先需要根据自身条件开始计算——哪些物理威胁或灾难企业无法承受,并对资产价值进行分析,确定恢复的优先级顺序,确定灾备方案。
灾备演练也很重要。以B站事件为例,数据和系统的恢复进度和灾备预案熟悉程度息息相关。黄亮表示,如银行、证券、医院等关键单位,基本定期做容灾演练,才能保证服务的稳定性。随着网络安全法、数据安全法的进一步推动实施,以后企业的IT架构合规要求只会越来越严,企业要想偷懒也不太可能了。
企业与各种故障和威胁搏斗的故事无止境。灾备一事,丰俭由人,本质还是看公司如何算账,愿意投入多少。B站崩了对各大企业的*启示,也就是把“重视企业IT安全”写在明面上了。








