芯桥半导体发布智枢 E200 具身智能算力控制单元:以“端云同构”赋能具身智能新应用
2026 年 6 月 27 日,在 2026 ARCE亚洲机器人大会暨展览会现场,国内新兴高性能通用GPU芯片企业芯桥半导体正式对外发布其最新硬件产品——智枢 E200 具身智能算力控制单元。

作为一款专为具身智能端侧复杂作业场景量身打造的算力中枢,智枢 E200 通过深度定制的边缘计算架构,为各类机器人本体厂商提供了可量产落地的全新算力选项,加速具身智能设备从实验室原型向真实应用场景迈进。

芯桥半导体解决方案副总裁 张鑫
“大小脑”融合:打通从认知决策到实时执行全链路
作为一款立足于解决边缘复杂场景痛点的算力终端,智枢 E200 创新性地实现了 GPU、CPU“大小脑合一”的异构协同计算体系,一机整合具身智能从认知决策到实时执行的算力链条:
大脑层以高性能 GPU 为核心计算载体,负责高负载运行 VLM、LLM 等参数大模型,实现对复杂环境的深度理解与自主决策;小脑层多核 CPU 与 GPU 紧密协同,高效完成对视觉、激光等多维传感器并发数据的融合分析与避障规划;运动执行层依托高能效 CPU 实时核集群,实现微秒级伺服运动控制与电机驱动反馈;连接层通过大容量共享内存机制消除数据搬运的物理延迟;系统保障层则在底层提供实时健康监测与安全冗余备份。
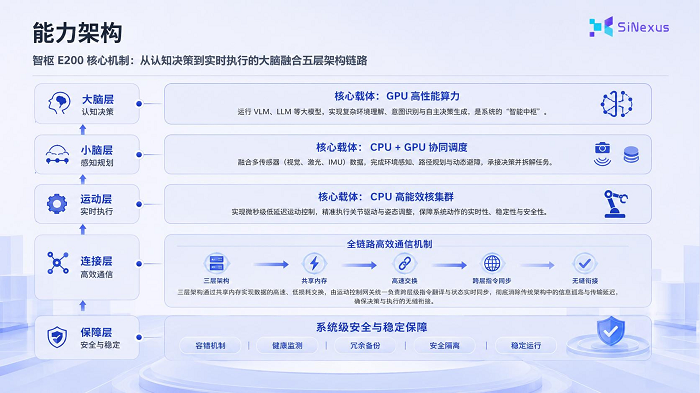
模块化架构:破解"大小脑"算力博弈
传统机器人算力方案依赖统一内存集成架构,将CPU与GPU固化一体,虽具备体积优势,但也存在算力升级需整体替换设备的显著短板,迭代成本高昂,难以适配高速迭代的具身智能应用需求。
针对行业痛点,芯桥半导体智枢E200采用核心板与MXM GPU板分离设计,打破传统一体化板贴架构的桎梏。智枢E200搭载英特尔® Core™ Ultra处理器与芯桥Sinexus S200 GPU,依托模块化设计优势,设备可实现CPU、GPU模块独立迭代升级,无需更换整机硬件,有效降低机器人企业硬件更新、长期部署的综合成本,为边缘具身智能设备的持续升级提供了高效、高性价比的算力解决方案。

场景适配:落地具身智能真实应用
依托超高算力配置、丰富接口拓展能力与紧凑机身设计,智枢 E200 可高效匹配机器人、智能装备、工业控制等各类嵌入式终端集成需求,兼顾算力性能、实时联动能力与空间适配性,为端侧智能感知、集群协同运算提供高集成度一体化硬件解决方案。
1、*算力与处理性能: 在核心计算指标方面,智枢 E200 提供高达 352 TOPS INT8的强劲融合算力,并配备 128GB 容量 LPDDR5显存,保障多任务流畅处理。
2、全维度外设接口:覆盖感知、控制、通信全场景接口需求,支持视觉、语音、激光雷达、IMU等多传感器数据实时融合。配备千兆 EtherCAT 实时控制网 +高速管理网架构,支持机器人集群协同调度与分布式计算。
3、适配机器人嵌入场景:整机尺寸190mm×170mm×95mm,机身结构紧凑小巧,可灵活适配各类内嵌式安装工况;接口采用抗震动设计,保障机器人动态作业等场景稳定运行。
云边协同:打造芯桥全栈算力底座生态
作为一家由智算产业资深人士于2025年3月创立的芯片企业,芯桥半导体依托“热启动”模式及产业链资源整合优势,已快速建立起从芯片架构到解决方案的全栈技术能力。公司推出的SiNexus X200和SiNexus S200 系列国产高性能通用GPU已在国内千卡集群点亮,产品综合性能经客户严苛认证。围绕具有自主知识产权的芯片产品,芯桥持续打造全栈式国产智算集群解决方案,以工程化、体系化能力为核心,助力构建国产算力底座。
智枢 E200 的正式发布,不仅是芯桥在单一硬件产品的上新,更标志着公司的产品矩阵正从云端数据中心向端侧节点延伸,*契合了当前算力网络 “边云协同” 的技术演进趋势。芯桥通过将自有 GPU 能力下沉到具身智能领域,不仅极大拓宽了其芯片的应用场景与商业变现渠道,更是打通了从云端大模型训练、推理,到端侧机器人推理、执行,再到数据回传的完整闭环。

目前,国产芯片竞争已从聚焦于单颗芯片的跑分比拼全面转向系统级交付、场景化适配与工程化能力的竞争。智枢E200正以端云同构的底层优势,在虚拟大模型与真实物理世界之间架起了一座高效、可靠的算力桥梁。
相关资讯
- 京东助推爱仕达、星巴克新品首发告捷 连创品类、品牌销量新纪录
- 全固态电池进入体系化竞争元年!高能数造补齐硫化物粉体核心短板,建成行业完整装备工艺全链条闭环
- 实验室进口液相色谱仪预算吃紧,国耀融汇仪器租赁方案进入视野
- 艾德金融:普赢创新科技正式向香港交易所递交上市申请表
- 艾德金融:齐云山食品(02797.HK)启动招股,为中国南酸枣食品行业领军企业
- GEO自动化营销系统vs传统SEO/重型营销云:技术架构与效果验证对比
- 东鹏直接报警,中国品牌不能被谣言“安排”!
- 泰国最 大零售集团,为何把“亲生品牌”交给科丝美诗?
- 以运动联结邻里,以善意温暖社区|邦泰2026绽FUN运动季启幕,读懂房企运营的人情味