

当前,人工智能大模型发展一日千里。2024年大模型格局有何变化?最近一份来自国家部委的权威报告,揭示中国大模型最前沿动向。
由工信部直属的中国互联网络信息中心,发布了《生成式人工智能应用发展报告(2024)》(下称《报告》),有几个信号非常值得关注。
截至今年7月,中国完成备案并上线、能为公众提供服务的生成式人工智能服务大模型数量,已经高达190多个。随着竞争日趋激烈,一场淘汰赛已经展开。事实上,国内外不少大模型初创公司如Stability AI、Adept、Humane、Reka AI等,都已经在排队寻求“卖身”。
与此同时,生成式人工智能与制造业、农业、医疗、教育等传统行业深度融合,推动产业转型升级,促进新业态、新模式的不断涌现。
《报告》指出,截至2024年6月,中国已经有2.3亿人表示自己使用过生成式人工智能产品,占整体人口的16.4%。哪些产品*?从这份覆盖了全国3万网民的大规模抽样调查结果来看,百度文心一言仍然领跑,在网民中使用率高达11.5%,位居*。
事实上,以百度、阿里、字节跳动等为代表的科技巨头,凭借雄厚的资金、充足的人才等优势,已成为国内大模型的核心玩家,一超多强格局显现。尤其是百度,最早布局了文心大模型,投入力度大,关键成果多,在多个评测维度位列*,*身位明显。
随着大模型进入应用爆发期,在赢家通吃的AI江湖,谁能一举夺魁?这将深刻影响中国人工智能的未来。
1、抓住*的金矿
全球大模型竞赛中,各大巨头的核心竞争力是什么?
天风证券研究所所长赵晓光最近分享了一个观点:中国经历了从劳动力红利到工程师红利的时代,未来*的红利实际上是科研红利。科研产业化,是*的金矿、最核心的源头。
这一判断在人工智能领域已经体现得淋漓尽致。
技术只有走出实验室,才能变成科研红利。对人工智能企业而言,就是要通过科研让技术应用化,让AI对无数普通人更友好。
以百度为例,截至11月初,百度文心大模型的日均调用量已经超过15亿,相较一年前首次披露的5000万次,增长约30倍。这条陡峭的增长曲线,正是过去两年中国大模型应用爆发的缩影。
近日,沙利文发布的《2024年全球AI生态全景概览》,百度和OpenAI、谷歌一起,成为了全球唯三被该机构承认的“AI原生巨头”,也是中国*一个榜上有名的公司。
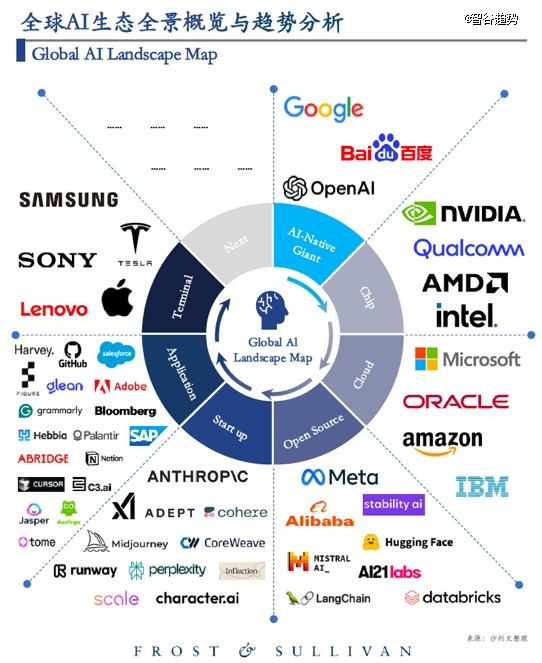
沙利文《2024年全球AI生态全景概览》报告中,百度与谷歌、OpenAI位于AI-Native Giant 同一象限
百度为什么能上榜?其关键原因,就是用多元化AI原生应用,率先推动“科研产业化”,抓住了人工智能领域未来*的金矿。抓住红利的同时,社会千行百业拥抱AI的门槛得以降低,符合国家对发展新质生产力和未来产业的期望。
具体来看,百度降低使用者进入AI的门槛,一个重要方式就是对传统互联网应用进行AI重构。比如百度文库就基于文心大模型重构为“一站式AI内容获取和创作平台”,具备发布智能PPT、智能写作、思维导图、研究报告、拍图生文等上百项多模态AI能力。
据不完全统计,百度这两年推出了不下15款AI产品。这些从传统互联网应用升级来的AI应用,拉近了普通用户与AI的距离。就比如一个没有AI素养的小学生,也可以直接和文心一言用自然语言交流。
从某种程度上说,这才是AI应用该有的样子。因为技术不仅要成为应用,更要成为真正的“有用”。而人类发展史上对不同新技术的孜孜追求,最终目的就是为了“世界应该是平的”。
百度,就是在用这些简单、易上手的AI应用,努力填平AI科技鸿沟。
随着用户对AI应用的接受度越来越高,百度对AI应用有了更进一步的认知。在今年世界大会上,李彦宏强调了AI应用的两个方向:一是智能体,二是产业应用。
他将智能体视为“AI原生时代,内容、信息和服务的新载体”。《报告》也指出:“以智能体为代表,正成为未来人工智能应用的主流形态”。
目前,百度已经布局了公司类智能体、角色类智能体、工具类智能体和行业类智能体四大类。
在企业运营领域,比亚迪等企业将智能体应用于销售、售后领域,为用户提供专业、高效的咨询服务,其销售线索转化率大大提升;
在政务服务领域,中卫慧通利用基层政务智能体帮助村民们解答生活中的各种问题,已覆盖20个区县,约3万名基层政务工作人员正在用大模型服务超千万居民。
如果说“智能体”降低了我们作为AI产品开发者的门槛,那么产业应用则拓宽了科技企业技术应用的想象边界。
截至目前,百度发布了基于大模型的100大产业应用,涵盖制造、能源、交通、政务、金融、汽车、教育、互联网等众多行业。比如在智慧能源领域,深圳燃气与百度合作探索将大模型应用于燃气行业,首次在行业引入视觉大模型,建设智能视频中台,解决燃气企业运营场景复杂、识别困难等难题。目前已应用在68个场站、58个营业厅,一期接入视频超过1000多路,在一线实践中取得显著成果。
人工智能向千行百业深入,这符合国家关于发展未来产业和新质生产力的期望。《报告》中指出:“生成式人工智能与实体经济的深度融合,将打造‘人工智能+千行百业’的产业新格局,形成现代化、智能化的产业体系,促使传统生产力向新质生产力转型”。
向新质生产力转型过程中,科技巨头必须承担技术赋能的角色。以人工智能的底层技术和AI原生应用支撑,做各行各业的智能应用和算力供应商,从而带来生产方式的变革和生产质效的提升。
这样的融合,对千行百业的发展太重要了。拥抱大模型,就是拥抱新质生产力。
2、模型升级,始终先行一步
为什么各行各业的网民,使用文心一言的比例最高?除了应用层的丰富,背后还有很重要的一个原因,从底层模型架构来看,百度模型层的升级始终先行一步。
简单来说就是,百度具备技术和应用“双重*”的竞争优势。
比如,沙利文发布的《2024年中国大模型能力评测》中,百度文心一言拿下数理科学、语言能力、道德责任、行业能力及综合能力等五大评测维度的四项*,稳居国产大模型首位。
泛摩尔定律行业有一条不成文准则:由于技术迭代周期缩短,*者并不以进场先后顺序和资金规模为转移。后来者通过押注更新技术,完全有可能超越先行者。但百度似乎打破了这一定律。它不仅是全球*个推出生成式AI的企业,技术水平也保持*。
在百度2024世界大会上,李彦宏还提到:大模型的幻觉正在基本消失。
也就是说,一年前,你向聊天机器人提问,不管是查资料、订票、历史,你都不敢完全相信它的答案。因为AI有幻觉,可能“已读乱回”。但今年,我们再提问文心一言,可以明显感知到AI准确度和可信任度在优化。哪怕是技术含量更高的文生图,也多了一层写实感和真实感。
技术水平和应用体验的双重提升,带来用户端的认可与信赖。
再比如自动驾驶之于多模态模型。《报告》指出,多模态能力拓展了生成式人工智能的应用边界。自动驾驶是新质生产力典型代表,也是多模态大模型的典型应用场景,更是我们观察百度多模态大模型实力的*窗口。
而今年以来,百度的无人驾驶汽车萝卜快跑已经掀起了好几轮热议浪潮。从最开始被无人驾驶车震惊,再到在行业中深究,百度作为“自动驾驶”技术*者的身份才完全展露在大众面前。
很多人都感叹:“我以为百度还是个搜索引擎,没想到玩起了自动驾驶。特斯拉没做到的,竟然百度做到了”。
实际上,萝卜快跑已经覆盖全国10余个城市,并在多个城市提供了自动驾驶出行服务,在超1亿公里实际道路测试里程中,实现0重大伤亡事故。
梳理完百度在大模型应用上的成绩,新的问题随之而来:
为什么百度在大模型的各个发展阶段都能*,为什么一众科技大厂里,百度*吃到了“科研产业化”的红利?
3、全栈自研的技术底色
这一问题的答案,可以追溯到百度在人工智能研究上的时间起点。
2013年,百度深度学习研究院成立,成为*个把模拟人脑神经网络的深度学习提到核心技术创新地位的中国互联网企业。两年后,OpenAI的创始人山姆·奥特曼才和马斯克讨论,要成立一家实验室来抗衡谷歌刚刚收购的DeepMind。
最早入局,奠定了百度在大模型竞赛中的先发优势,持续性的巨大投入则带来高于时代的技术产出。
从2013到2024的11年里,百度在人工智能研发上的投入资金超过1700亿元,是中国科技公司中对人工智能研发时间最长、投入资金最多的公司。
近期,许多业内人士还爆料,为AI大模型研发提供理论基础和实操指导的Scaling Law最早源于百度。“大多数人不知道,关于Scaling Law的原始研究来自2017年的百度,而不是2020年的OpenAI”。
换句话说,百度在人工智能领域的起跑时间,甚至早于OpenAI,这也为它后来成为全球*家推出生成式AI产品的企业提供了解释逻辑。
早入局、高投入,最终所追求的目标是产品技术的全链路自研,这决定企业在AI竞赛上能否不依附外界,独立自主搞AI。
从芯片层的昆仑芯、框架层的百度飞桨、到模型层和应用层,百度的AI全栈布局拥有中国*全栈自研的基础设施,也是*个拥有全栈AI技术架构的企业。
完全自主可控的技术让百度在大模型的核心战场上有更大的自信和行业不可比拟的优势,这也是为什么在许多关键技术节点,*个实现突破的中国大模型企业往往是百度。
比如,2024年最火热的大模型技术“慢思考”能力。今年9月,OpenAI发布的o1大模型,可以处理相对复杂的推理任务,带来全球AI行业的新高潮。但是,早在o1发布将近1年前,百度已经预判性提出“慢思考”能力,提出以内容生成即时性为主导的系统1,搭配以具备理解、规划、反思和进化能力系统2的技术路线。
今年,多智能体写作已经在文心大模型体系中有了技术落地。
再比如,“消除大模型幻觉”,是催生AI应用爆发的技术前提。几乎所有大模型厂商都想攻克这一难题,但在IDC、沙利文和中国软件评测中心等多家机构的调研数据里,位居*、国际*梯队的始终是百度文心大模型。
百度为解决“大模型幻觉”,研发了“理解-检索-生成”协同优化的检索增强技术(iRAG技术)。李彦宏还在世界大会现场发布了最新成果——检索增强的文生图技术iRAG,将百度搜索的亿级图片资源和强大的基础模型能力结合,可以生成各种“去掉了机器味”的超真实图片。
为什么百度在今年大家都卷类Sora产品的时候,选择先解决模型幻觉问题?
这也是因为百度在AI布局上的全栈自研,让它获得更大的自主选择权。在全行业都朝着一个赛点竞争的时候,百度有实力也有余地去做它所认为的“更值得去做的事”。
在今天内卷加剧的大模型赛道,也只有技术完全自主可控并保持*的企业,可以选择不随波逐流。因为它们不是跟随者,而往往是革新者。
所以,入局早奠定基础、高投入输送动力,由此持续*的自研技术,才是百度文心一言强势领跑大模型领域的最核心要素。
4、结语
行业洗牌期,*的自研技术其实也是决定中国大模型能否弯道超车的关键。
科技巨头们从不缺少资金,但真正*的自研技术如同厚重绵延的长城,绝不是一天能建成的。未来AI应用的大爆发,更需要强大的技术实力探路铺路。而随着西方国家对中国高新技术的“围追堵截”,注定中国大模型产业不能再走“市场换技术”的老路。
弯道超车的办法,唯有自力更生。
从这个角度来说,百度用超过10年的科研深耕、技术积累,为中国的大模型企业闯出了一条新路——依靠完全独立自研,也能向世界一流水平看齐。这种十年磨一剑的科研精神与核心技术,才能够真正带来属于我们的AI自信。
正因如此,不论是起步的大语言模型,还是今天主流应用形态的智能体,亦或是未来具有无限应用场景的自动驾驶,在多个评测维度位列*的百度,都可以说是大模型战场上具有*实力的核心玩家。
从它的布局中,我们能看见中国大模型潮水涌动的方向。









