大模型创业的*结局是卖身?
就问科技圈的创业,谁能不羡慕创业几年、卖身大公司、创始人巨额套现离场,从此过上财务自由的幸福生活呢?
这么说你还真别破防。
之前红极一时的Character.AI被谷歌收购,宣布放弃预训练,转向和第三方模型公司合作,据说还致使1600万美国年轻人集体失恋?AI独角兽Inflection AI被微软收购;Stability AI单季度亏损超3000万美元,一度传出“卖身”消息。
可见海外大模型厂家们在真正走向商业化时,各有各的苦衷。
朱啸虎曾经下了个定论,国内的大模型*的结果就是卖给大厂。
这句话对也不对。
“对”在朱啸虎的眼光老辣,去年的200多个大模型很快进入了收敛期。“不对”在,从融资环境来看,国内大模型企业面临的困境是“弹药”不够,如果弹药更充足,它们的生存会更好。
盘一盘“百模大战”剩下的弹药库,我们发现六小虎(智谱、零一万物、MiniMax、百川智能、月之暗面、阶跃星辰)+DeepSeek的座次渐明,而入局的大厂们,正试图“坐收渔利”。
你们以为大模型的比赛即将结束了?
其实大模型小虎们的“非常6+1”比赛才刚刚开始。
01 六小虎谁是技术派?
大模型看起来深奥,其实可以把它比作做菜。模型结构就像是业界公开的菜谱,数据则是原材料,模型训练过程中对工程细节的把握则是厨艺。
始于2023年年初的百模大战,就像是一场热闹非凡的饕餮盛宴。各方大厨齐登台,但做着做着,有些人依然在坚持磨练厨艺,想要成为厨神;但有些人却已经悄悄放弃了预训练,用起了“预制菜”。
一年多后,零一万物Yi-Lightning在 LMSYS这一全球大模型必争的公开擂台上,实现了中国大模型首度实现“超越OpenAI GPT-4o”的*成绩。DeepSeek、智谱AI的模型也取得了相当出众的成绩。(榜单成绩截止10月26日)
这么看来,“六小虎”中的智谱AI、零一万物,和“编外小虎”DeepSeek是下定决心要冲击“厨神”宝座。但说起做大模型这桌菜,这几位“厨神候选人”的招式却各不相同:
智谱AI:张鹏东拉西扯撑起整个“厨房”
作为清华系首批大模型初创公司,智谱AI CEO张鹏毕业于清华大学计算机系、首席科学家唐杰是清华大学计算机系教授(国内大模型的奠基人)、总裁王绍兰是清华创新领军博士,注定了智谱AI身上的“光环”。
特别是后来,投资方有着社保基金中关村自主创新专项基金的加持,在清华+中关村双保险,让智谱在百模大战里一直都是“别人家的孩子”,发力B、G端也在情理之中。特别是在预训练上,智谱从来没有放松过,面对行业的“预制菜”的现象,张鹏去年就提出过一个观点——预训练模型真正的创新型的学术研究少了,而基于一个强大底座疯狂训练模型的人变多了,只需要加个名字,就成了新的模型。
不久前,张鹏表示现在智谱采取了布局生态链、寻找更大资源支撑来应对竞争。如今智谱AI的估值已经超过200亿,当务之急是验证其商业化能力,否则,寻找更大的资源支撑将会面临诸多挑战。
正因如此,为了更好的商业化,智谱AI CEO张鹏正在东拉西扯“撑起”生态链布局,张鹏+唐杰的清华黄金组合,只争朝夕。
零一万物:总是做“不鸣则已,一鸣惊人”的尖叫鸡
今年前三个季度,零一万物推出了两个模型——Yi-Lightning、Yi-Large,均在LMSYS上排名前列,且均为国产大模型*。
不过零一万物最核心的优势不在榜单上,而是在预训练的成本上,模基共建战略下,训推成本低得能让山姆奥特曼和马斯克都咂舌。
李开复表示,Yi-Lightning的训练只用了2000张GPU,训练周期仅一个半月,成本是马斯克xAI成本的2%左右。训练成本虽然低,但Yi-Lightning的性能并没有打折扣。Yi-Lightning的性能与xAI的Grok-2-08-13模型并列第6,并且超越了OpenAI的GPT-4o-2024-05-13就是一个很好的例证。
但让市场没有拨开的迷雾是,零一万物国外ToC产品神秘兮兮的,ToB只做赚钱的,这样的ToB项目可真不好找。行业里都在说要“逃离项目制”陷阱,但是又转头去做项目。在商汤、智谱AI之后,零一万物就能行吗?
从弹药库上来说,不久前,零一万物完成新一轮融资,交易金额达数亿美元,投资方是某国际战投、东南亚财团等等。
而在拉投资和商业化方面,咱还真得相信开复老师多年的积累,现在新融资也有到账,业内都在期待李开复再凭人脉和实力搞来“大单”。
DeepSeek:财大气粗的“价格屠夫”
为什么DeepSeek不在六小虎之列?因为实在是太财大气粗了。
站在DeepSeek背后的是幻方量化,国内首屈一指的私募。这种“财大气粗”直观地体现在了买卡上,2019年,幻方量化成立AI公司,投资2亿元自主研发深度学习训练平台“萤火一号”,搭载了1100块GPU,2021年,幻方量化对“萤火二号”的投入增加到10亿元,并且搭载了约1万张英伟达A100显卡,大厂看了都得说句佩服。甚至在硅谷,DeepSeek被称作“来自东方的神秘力量”。
对了再说个冷知识,今年的大模型降价,其实就是由DeepSeek和部分大厂掀起来的,大家都说,它通过降价方式,实现了部分模型厂商出清,或有利于大模型产业的各类资源(包括人才)集中,可能醉翁之意不在酒啊。
这么来看,三位“厨神候选人”,智谱AI一向有着“清华系国家队”的称号,背后的主导人物唐杰也是中国在人工智能和大模型领域颇具话语权和声量的学术领军人物,找融资、找算力不难;零一万物创始人李开复同样在AI领域深耕多年,早早布局AI Infra(训练的基础设施),近期也宣布了新融资,资金算力也不成问题;DeepSeek背靠幻方量化,坐拥上万张GPU,资金算力都很足,未来要看背后的幻方想怎么应用大模型。
可见这三位“厨神候选人”都没有道理在算力充沛、资金能支持的情况下,转投大模型的“预制菜”。
02 谁又在烧“模型预制菜”?
从模型性能的角度来说,坚持预训练可以把模型的能力上限、模型的安全性掌握在了自己手中,同时也牢牢把握住了推理成本的优化空间。能力与资源并举,是大模型洗牌时代的“硬通货”。
而“小虎”们似乎从预训练开始分道扬镳,有的人开始厨神争霸,有人已经面临着下牌桌。
月之暗面:大模型时代的ofo摩拜?
注意,这里的ofo、摩拜并不是一个贬义词,创业前期的ofo摩拜也是流量的宠儿、市场的焦点、用户的心头好。
月之暗面最著名的产品就是Kimi,网站分析平台Similarweb的监测数据显示。从今年3月在B站加强推广后,Kimi的访问量增幅一度达到402.9%,在B站,Kimi几乎关联了用户可能在B站搜索“AI”的所有词条,比如ChatGPT系列、AI系列、提效系列、助手系列、打工人系列等等……
砸钱投放,但只是砸出了名声和所谓的Kimi概念股,其实市场并不排斥砸钱,但大模型的关键是钱要砸到位:高价买来的用户能留住吗?
36kr在今年8月的报道中曾提及,月之暗面在B站给出的CPA(Cost Per Action,用户转化人均成本)报价,高达30元左右。
IDC中国高级分析师杨雯在今年9月的报告《移动端大模型应用市场竞争力分析研究报告》表示,现有数据显示,即便是率先发布的ChatBot应用,无论它们定位为个人助理或是情感陪伴,普遍面临着30日用户留存率偏低的问题(6%左右)。
一方面烧钱买用户,另一方面用户流失,但是为了融资、给股东交差,又不得不继续烧钱。据英国《金融时报》报道,现在月之暗面的融资似乎也有了新花样,即“用股份换算力券”。
月之暗面的最新一轮融资发生在今年8月,消息称月之暗面获得了由腾讯领投的3亿美元新一轮融资。凤凰网科技的报道则显示:“腾讯投得并不高,只有小几千万就成了领投了,剩下的是很多小基金凑的”。
当然了,面对着“不得不烧钱换增长”的困局,也不意味着月之暗面就会走ofo的老路。有分析认为,从现在的打法上来看,可能月之暗面为自己设想的结局也是被大厂收购,所以才锚定To C应用。
MiniMax:做应用一流,做模型欠火候
MiniMax的应用Talkie,是六小虎中当之无愧的出海应用榜首;还有视频生成应用海螺AI也引起了全球瞩目。
但是就在不久前MiniMax产品负责人、前今日头条用户产品负责人张前川,宣布已淡出公司事务,改任产品顾问一职。画个重点,张前川此前主要负责MiniMax在C端的“星野”和“Talkie”,后参与生产力工具“海螺AI”和部分其他产品的日常事务。这怎么刚做出点成绩来,主将先走了?
虽然曾经MiniMax的创始人闫俊杰说“我们没有一块 GPU ,虽然我们应该是中国公司里实际用 GPU 数量最多的创业公司。” 但是没有一张卡的缺陷是,以Talkie、海螺AI为代表的国产AI产品,虽然走出了一条出海新路,但在用户实际使用时,成本还是难以覆盖。
例如现在MiniMax 的ABAB大模型很久没更新了,MiniMax困于没有自有算力,没有AI Infra(AI基础设施),从时间线来看来,原本是MiniMax和智谱AI同时起步做大模型,但是很遗憾地,MiniMax错过了双巨头格局。
百川智能:估值高达200亿,却被疑技术掉队
从2023年8个月发布8款模型,到2024年仅发布3款模型,百川智能在基座模型上的脚步在不断降速。
其实百川应该是百模大战之初最有流量的小虎,拿的融资也不少。但是一年多后,百川最新一代基座大模型Baichuan 4只选择打榜国内商业化榜单SuperCLUE。LMSYS ChatBot Arena、AlpacaEval等有学术背景、相对公正的国际权威榜单上,Baichuan 4却从未上榜。
在应用端,据七麦数据显示,百川智能的应用百小应近30日iPhone端日均下载量仅3次(是的你没看错,是3次)。
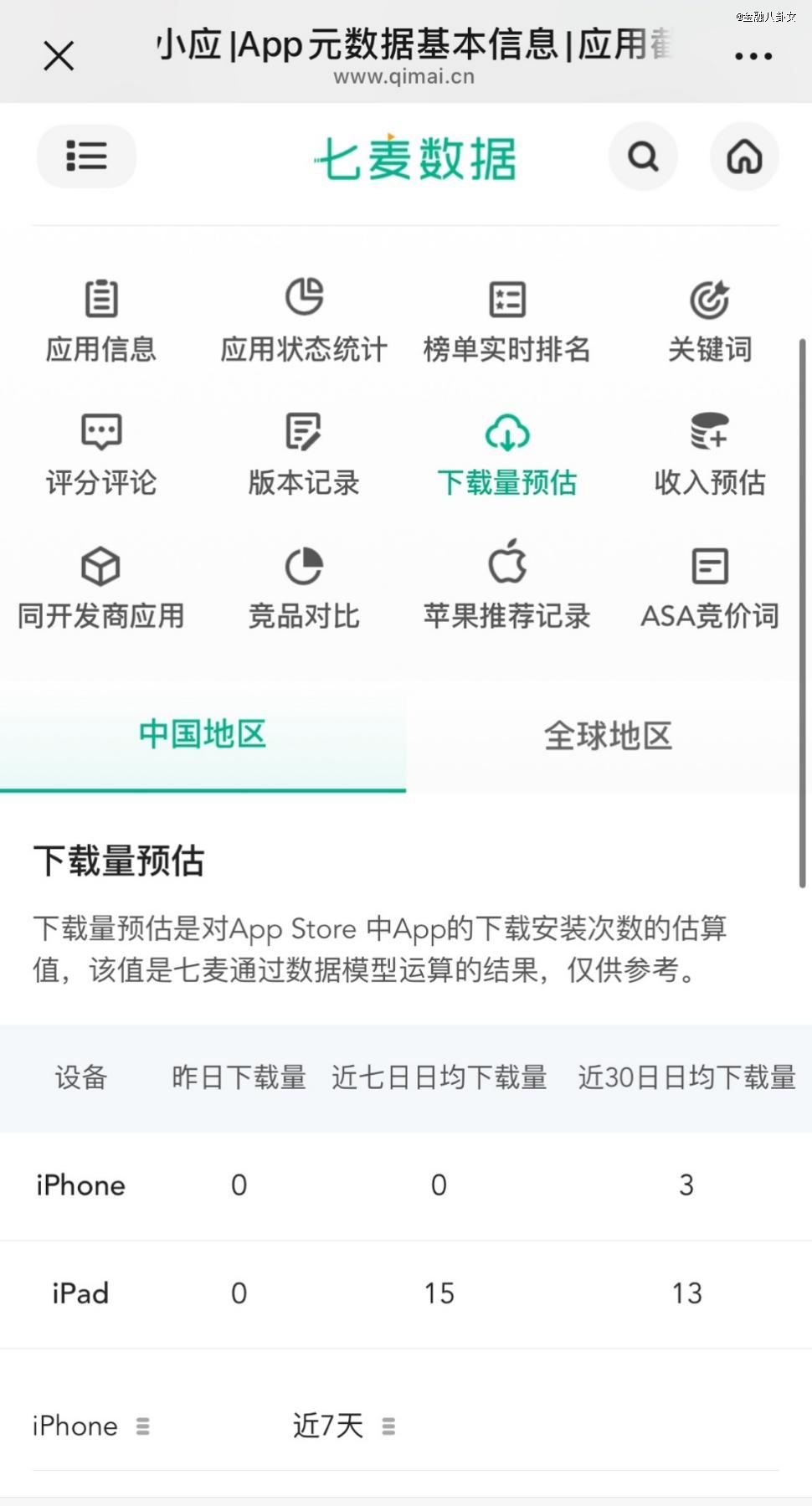
百川的ToB落地,也不是很理想。据腾讯《深网》不完全统计,今年前9月百川中标项目仅2个,而智谱中标项目为21个。另一方面,百川花14亿元购买的未来三年算力交付服务的稳定性也引发关注,算力合作方鸿博股份公告显示,由于GPU服务器未能按时到货,旗下英博数科向百川智能算力履约进展与实际情况存在延后。另一份公告则显示,英博数科与紫光晓通科技有限公司解除了高达4.94亿元的购销合同。作为紫光股份旗下公司,紫光晓通业务就包含了英伟达产品的中国区销售业务,这一定程度上影响了英博数科的GPU采购进度。

▲截图自鸿博股份《关于2023年年报的问询函回复的公告》第三部分
之前业内盛传,百川会逐步放弃预训练模型,缩减预训练算法团队人数,将业务重心转向AI应用。百川的回应是,预训练团队稳定,预训练工作正在稳步推进,并不存在放弃预训练一说。
虽然王小川在接受《人物》采访时说自己发自内心的“不焦虑”。Sora他不跟,长文本他不卷,价格战他不参与,大家都在焦虑商业化,他到底在不在乎?
在小川哥看来,公司账上有钱,融资正常,钱没乱花,现金流不成问题。但是百模大战都到洗牌阶段了,咱太“佛系”就会被比下去啊!
阶跃星辰:百米赛跑让了别人50米
阶跃星辰背靠上海国投,和智谱AI一样,都不缺资源。但入局太晚,如果百模大战是场百米赛跑,人家都跑了半程阶跃星辰才入局,不管是模型还是应用都在追赶状态。
简单来说,阶跃星辰基座模型性能与头部国内模型有差距Step-1千亿参数语言大模型性能仅对标GPT-3.5;Step-2 万亿参数语言大模型性能仅对标 GPT-4;划个重点,前文提到了“技术派”零一万物、智谱AI、DeepSeek可都是逼近或者超越了OpenAI今年5月发布的 GPT-4o。
其次,跃问、冒泡鸭等 ToC 产品的表现也仍有提升空间。七麦数据显示,冒泡鸭周下载量仅808;Similarweb数据显示,跃问9月访问量仅7万。业内都在讨论,阶跃你手里有那么多卡,你得好好做啊。
所以,这场热闹的厨神争霸里,有人自信领跑“钻研厨艺”,有人奋起直追“研究菜谱”,有人转换赛道用起“预制菜”,有人干脆熄火躺平……
小虎们需要意识到,模型预训练是衡量大模型公司技术实力的重要指标,也是最为显著的技术壁垒。而从模型预训练角度来看,六小虎的技术差距一旦被拉开,掉队后再追赶难度极大。
03 大模型的大厂创新窘境:小创新大厂赢,大创新小厂赢
但话又说回来了,六小虎中谁赢都不是结束曲,真正的对手还是在大厂。
随着大模型预训练的赛道上基本进入了终局,一场创业公司与大厂也即将“决战光明顶”。
之前AI行业的很多人认为,只有大厂玩得起的“烧钱游戏”。
大厂的优势在于商业生态、资金、流量、庞大的团队,在调动资源方面,大厂有着天然的优势,随时能号令天下“华山论剑”。但是小厂人家也是东邪、西毒、南帝、北丐帮派里的厉害角色,完全能在某些方向上和大厂过招有来有回。
就像红衣大叔和百川智能王小川说的,在大模型界一直有句箴言——“小创新大厂赢,大创新小厂赢。
过往的PC互联网和移动互联网时代,确实不乏小厂做出水花后被大厂并购,或者干脆被大厂抄袭,最终导致创业失败的案例。
但是大模型热潮与以往技术浪潮存在着本质的不同。
一方面是技术迭代周期。大模型太强了,大模型时代下基座模型仍然在以4-6个月为周期快速迭代,推理成本也在以一年十倍的速度快速下降。今年的诺奖物理学奖和“一半”化学奖颁给了人工智能,其中一个获奖者甚至不到40岁,可见年轻的“小虎”们更有活力去迭代。“大力未必出奇迹”,大厂堆资源、搞并购的饱和式攻击打法,在大模型时代并不能完全奏效。
另一方面,则是人才战略。大模型的落地需要人的紧密配合,并不是由单个算法高管、单个技术天才掌握的。研发基座模型是一个极其复杂的系统性工程,既需要算法人才,也需要AI基础设施人才,还需要懂大模型的产品和工程人才。
各小虎都意识到了人才的重要性,月之暗面近日宣布微软亚洲研究院前首席研究经理谭旭正式加入;某小虎此前也曾传出接触某头部房地产中介平台算法高管的消息,双方随后向媒体否认,至于人才能否顺利融合,业界都在观望。
螳螂捕蝉黄雀在后。六小虎间的人才战正火热,大厂已经开始出手。典型的例子是字节跳动更是在今年频繁招揽大模型人才,组建大模型研究院。
但这次,“官宣”之外,静水深流。
技术团队们始终保持神秘的智谱AI、零一万物、DeepSeek反而在权威的LMSYS上取得世界*的成绩,受到《金融时报》等知名外媒的关注,但是这几家一直对自己的配置三缄其口。
背后的原因其实也很好理解。多位高端猎头透露,大模型“尖端人才”的争夺战已经打响,真正的技术leader总是藏于幕后的,就像是“秘密武器”,不轻易对外。“担心露头就被秒啊。”
同时,大厂自己也上演着“屠龙勇者成恶龙”的戏码。
市场环境对于大厂的要求是财报必须漂亮,进入IPO管道的更是如此。这把上悬的“达摩克利斯之剑”迫使他们必须将更多甚至全部精力放在传统优势市场的延续性上,对新业务的投入可能一时声势浩大,但持续性方面面临着财报的灵魂拷问。新业务甚至有可能还没出现可能内部站队就给站没了,别说决战光明顶、华山论剑了。
能够聚拢各方人才,并且能够以高效的组织架构实现多方协同的大模型初创企业,洽洽成为了搅动一池春水的“创新鲶鱼”。
毕竟当年提出Transformer架构的是Google不假,这个架构如今已经逐渐收敛成了中外大模型的架构基座,但真正做出震惊世界的ChatGPT的,却是当时还是初创公司的OpenAI。
如此看来,专注模型预训练的智谱AI、零一万物、DeepSeek保留住了初创公司的“核心科技”,正为后续与大厂的竞争继续积蓄实力。要想*程度上盘活国内的大模型创新,这些公司会是重要力量。仅靠山头林立,“偶像包袱”又重的互联网大厂们,是远远不够的。
04 写在最后
其实,做好大模型还有更重要的使命。
据路透社10月21日报道,美国政府禁止对中国人工智能(AI)领域部分投资的相关规定目前正在进行最终审查,这些限制措施很快就会出台。
懂得都懂,中 美科技竞争格局越来越明晰,双方一直在互相比拼,从前些年的贸易、到芯片,再到现在的AI,大模型会成为各方英雄逐鹿中原的焦点。
现在,我们有庞大的、坚实的产业基础,有各种丰富的应用场景,只要训练的基础打得好,应用层面会形成一个强大的数据循环闭环,这是中国AI产业落地的天然优势。
虽然对于大模型初创公司来说,这是最坏的时代,因为巨头已经意识到大模型的重要性纷纷下场。
但是也是*的时代,因为只要把握住基座模型训练的自主权,打牢技术底座,初创公司就始终有突围的机会。
【免责声明】:本文不构成任何投资建议。市场有风险,投资需谨慎。
如有任何疑问,请联系(editor@zero2ipo.com.cn)投资界处理。