

据台媒报道,台积电近期准备开始生产英伟达最新Blackwell平台架构GPU,同时因英伟达的客户需求强劲,故此对台积电的晶圆订单增加25%;并有可能令本周放榜的台积电上调今年盈利预期。
报道引述业界消息指出,亚马逊、戴尔、谷歌、Meta及微软等都会使用Blackwell架构GPU来建立AI伺服器,令需求超出预期。
英伟达的利好,让大家对人工智能、GPU和AI芯片有了更多的想法,但这能继续持续吗?
01 GPU,销量咋样?
近来,外媒nextplatform还对AI芯片的销售做了预测。
外媒引述AMD CEO苏姿丰的数据表示,到 2023 年,数据中心 AI 加速器的总潜在市场规模约为 300 亿美元,到 2027 年底,该市场将以约 50% 的复合年增长率增长至 1500 亿美元以上。但一年后,随着 GenAI 热潮的兴起,以及 12 月推出“Antares”Instinct MI300 系列 GPU,苏姿丰表示,AMD 预计 2023 年数据中心 AI 加速器市场规模将达到 450 亿美元,到 2027 年,该市场将以超过 70% 的复合年增长率增长至 4000 亿美元以上。
这仅适用于加速器,而不适用于服务器、交换机、存储和软件。
New Street Research 的 Pierre Ferragu 的团队在科技领域做出了许多出色的工作,他曾尝试分析这家价值 4000 亿美元的数据中心加速器的潜在市场规模可能会如何,并在 Twitter 上发布了这一预测:
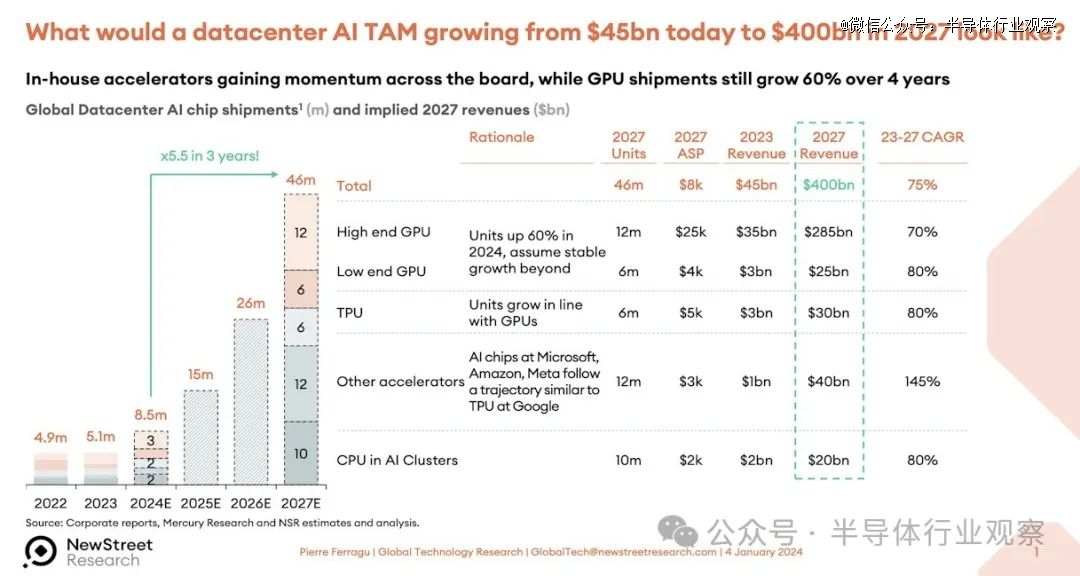
我们仍然认为这是一个非常大的数字,预计在 TAM 预测期结束时 AI 服务器、存储和交换机的销售额将达到约 1 万亿美元。
在 2024 年伊始,我们从富国银行股票研究公司董事总经理兼技术分析师 Aaron Rakers 那里获得了 GPU 销售预测,并进行了一些电子表格操作。该模型涵盖了 2015 年至 2022 年数据中心的 GPU 销售情况,并估计到 2023 年结束(预测时尚未结束)并延伸到 2027 年。富国银行的模型也早于AMD 最近几个月做出的修订预测,AMD 表示 2024 年的 GPU 销售收入将达到 40 亿美元。(我们认为会是 50 亿美元。)
无论如何,富国银行的模型显示,2023 年 GPU 销售额将达到 373 亿美元,全年出货量为 549 万台。出货量几乎翻了一番——包括所有类型的 GPU,而不仅仅是高端 GPU。GPU 收入增长了 3.7 倍。预测 2024 年数据中心 GPU 出货量为 685 万台,增长 24.9%,收入为 487 亿美元,增长 28%。2027 年预测 GPU 出货量为 1351 万台,推动数据中心 GPU 销售额达到 953 亿美元。在该模型中,Nvidia 在 2023 年的收入市场份额为 98%,到 2027 年仅下降到 87%。
Gartner 和 IDC 最近都发布了一些关于 AI 半导体销售的数据和预测。
近一年前,Gartner 发布了一份关于 2022 年 AI 半导体销售的市场研究报告,并预测了 2023 年和 2027 年的销售情况,几周前,它又发布了一份修订后的预测报告,其中预测了 2023 年的销售情况,并预测了 2024 年和 2028 年的销售情况。第二份报告的市场研究报告中也包含一些统计数据,我们将其添加到下表中:
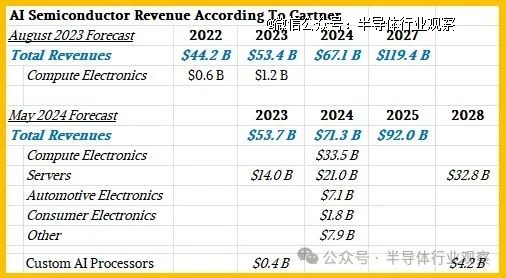
我们假设计算电子产品包括个人电脑和智能手机,但就连建立这些模型的 Gartner 副总裁兼分析师 Alan Priestly 也知道,到 2026 年,所有销售的个人电脑芯片都将是人工智能个人电脑芯片,因为所有笔记本电脑和台式机的 CPU 都将包含某种类型的神经网络处理器。
用于加速服务器的 AI 芯片是我们在The Next Platform上关注的重点,这些芯片的收入(我们假设不包括附带的 HBM、GDDR 或 DDR 内存的价值)在 2023 年为 140 亿美元,预计到 2024 年将增长 50%,达到 210 亿美元。但预计 2024 年至 2028 年期间服务器 AI 加速器的复合年增长率仅为 12% 左右,销售额将达到 328 亿美元。Priestly 表示,定制 AI 加速器(如 TPU 以及亚马逊网络服务的 Trainium 和 Inferentia 芯片)(仅举两个例子)在 2023 年仅带来了 4 亿美元的收入,到 2028 年也只会带来 42 亿美元的收入。
如果 AI 芯片占计算引擎价值的一半,而计算引擎占系统成本的一半,那么这些相对较小的数字加起来可能会带来数据中心 AI 系统相当可观的收入。同样,这取决于 Gartner 在哪里划定界限,以及你认为应该如何划定界限。
现在,让我们来看看 IDC 如何看待 AI 半导体和 AI 服务器市场。该公司几周前发布了这张有趣的图表:
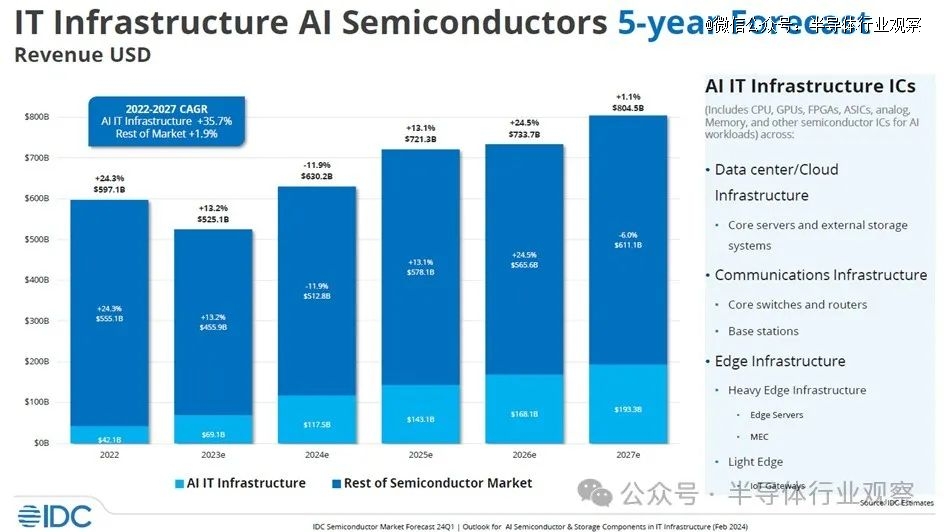
在此图表中,IDC 汇总了数据中心和边缘环境中使用的 CPU、GPU、FPGA、定制 ASIC、模拟设备、内存和其他芯片的所有收入。然后,它扣除了计算、存储、交换机和其他设备的收入,因为这些设备适用于 AI 训练和 AI 推理系统。这不是所有系统的价值,而是系统中的所有芯片的价值;因此它不包括机箱、电源、冷却、主板、转接卡、机架、系统软件等。如您所见,此图表包含 2022 年的实际数据,并且仍在估算 2023 年至 2027 年的数据。
在 IDC 的分析中,半导体市场中的人工智能部分从 2022 年的 421 亿美元增长到 2023 年的 691 亿美元,这意味着 2022 年至 2023 年之间的增长率为 64.1%。今年,IDC 认为人工智能芯片收入——这不仅仅意味着 XPU 的销售,还包括数据中心和边缘人工智能系统中的所有芯片内容——将增长 70%,达到 1175 亿美元。如果你计算 2022 年至 2027 年之间的数字,IDC 估计数据中心和人工智能系统中的人工智能芯片内容的物料清单总收入将以 28.9% 的复合年增长率增长,到 2027 年达到 1933 亿美元。
由此看来,GPU似乎还是一致的赢家,但曾在英特尔工作的Raja Koduri最近发布了一篇文章,分析了GPU的影响。
02 GPU没有对手?
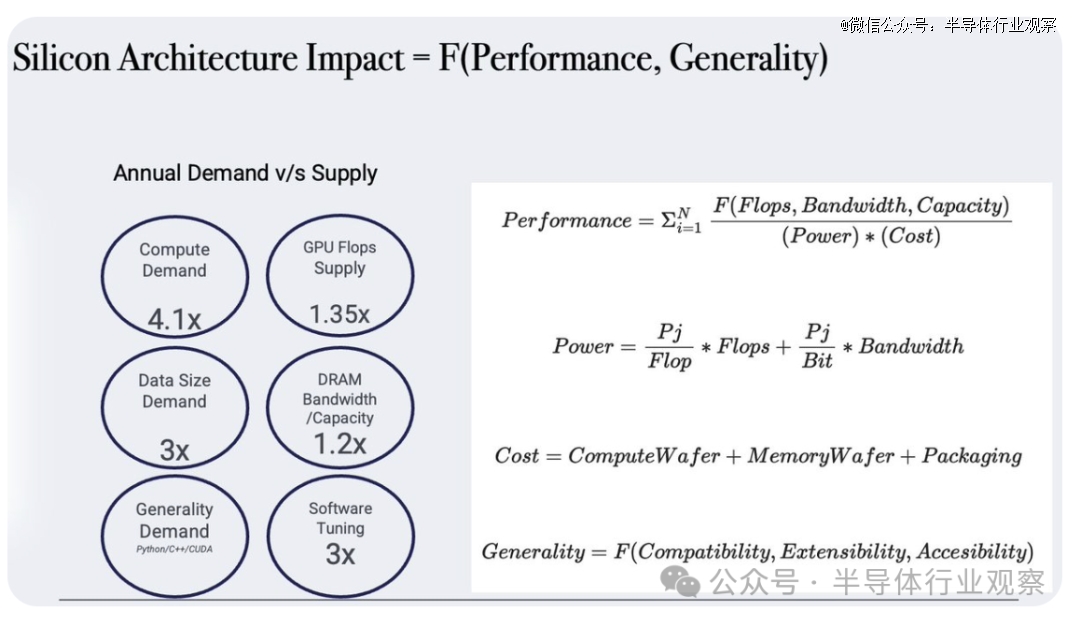
首先,Raja Koduri先分享了一系列的公式。

接下来,他一步步分析了这些公式:

首先看上面这个公式,Raja Koduri强调,您可以将此等式应用于 CPU 架构,因为这在设备、PC 和云上都取得了成功。而对于 AI 和其他浮点 + 带宽密集型工作负载,GPU 在此等式上得分最高 - 尤其是 CUDA GPU。而今天NVDA的天文估值就是一个很好的方程式形式。
在Raja Koduri看来,有抱负的竞争对手应该注意这个等式,并确定你的方法在你所针对的工作负载领域与现有企业的价值。
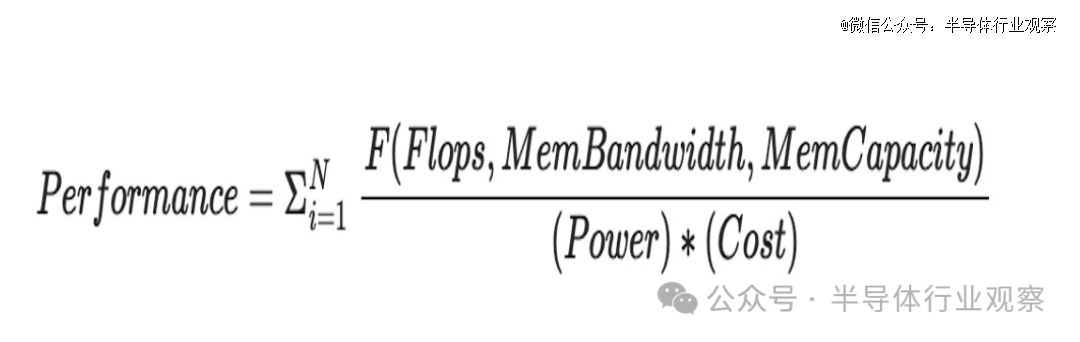
再看上面这个公式。
按照Raja Koduri所说,前面的西格玛(sigma)表示每个工作负载。对于不同的型号/工作负载,浮点运点的比率、带宽和容量要求可能不同。训练与推理是生成不同比率的一个例子。
Raja Koduri同时强调,我们不要忘记,在推理和训练循环之外,还有加速计算的需求 例如:图像和语音处理以及众所周知的并行数据分析和模拟算法。您的通用性会影响“N”的大小。此 N 对于 CUDA GPU 来说意义重大。对于 CPU 来说,N 甚至更大,但随后等式的其余部分开始发挥作用,它们的性能弱点占主导地位。
分子有 3 个参数 Flops、Bandwidth 和 Capacity。
Raja Koduri重申,Flop 需要通过宽度 (64,32,19, 16,8,4..) 和类型 (float, int..) 进行限定,工作负载可以混合使用这些。同样,带宽和容量也具有许多层次结构 - 寄存器、L1、L2、HBM、NVlink、以太网、NVME......
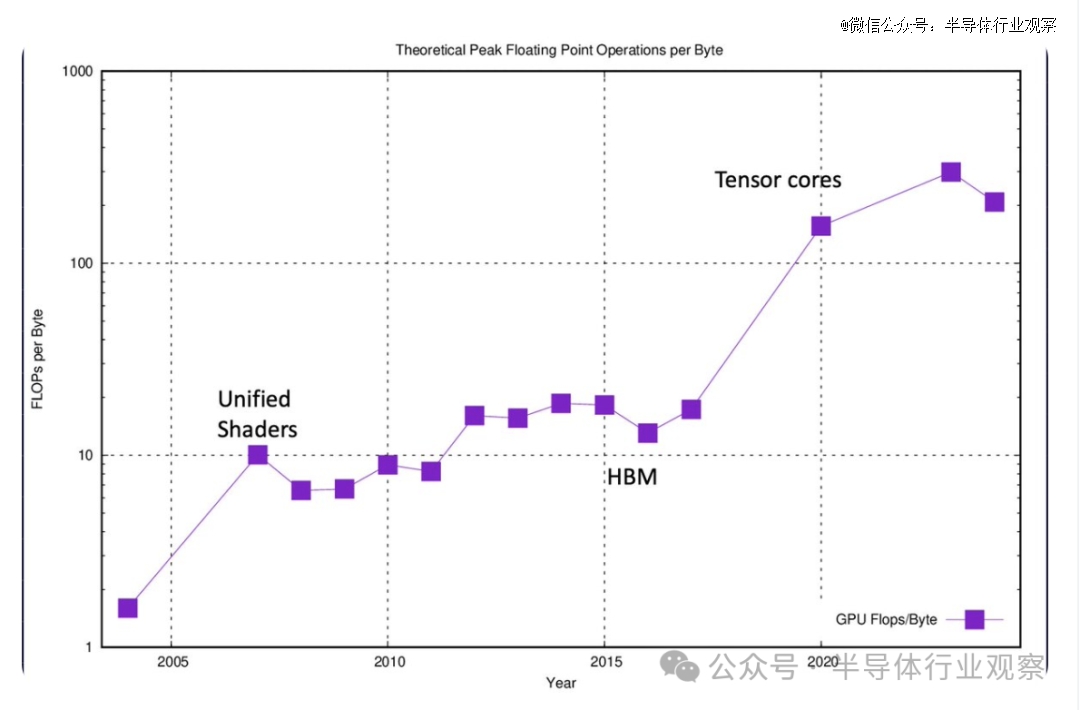
Raja Koduri在文章中还对现代 GPU 性能优化策略的简要介绍。
他表示,当我们首次在 GPU 中引入浮点可编程着色器时,浮点运算与 DRAM 带宽的比率为 1:1。在最新的 GPU 上,对于 16 位甚至更高、精度更低的格式,该范围超过 300:1。现在,对于更接近计算的内存(如寄存器、L1、L2 等)来说,这个比率变得更好。如果你研究一下最近关于转换器的大多数优秀的GPU优化工作,它归结为最小化这个比例。使用关闭内存层的次数越多越好。
在Raja Koduri看来,其他策略包括利用未充分利用的浮点点数以异步(Async)方式运行下一个 ALU 受限阶段。运气和技巧在寻找漂亮的“overlappable”代码块方面起着重要作用,这些代码块不会破坏彼此的缓存。
不过Raja Koduri强调,异步不适合胆小的人。您可以对代码进行的每一个百分点的flop-utilization改进都可能节省数十亿美元。
其他常见问题包括——为什么 CPU 人员不投入更多的 FLOPS 和 BANDWIDTH 并赢得 AI 战争?是否存在基本的架构限制?
Raja Koduri表示,关于这个问题的简单物理学答案是“否”。 但是,要将更多带宽引入 CPU,需要对 CPU 结构基础设施进行多次升级(和妥协)。一般来说,折衷方案是延迟。如果有人向您展示他们可以以更低的延迟、更低的功耗和成本提供更高的带宽。那么尼可站起来,加入他们的宗教。
CPU 设计人员倾向于优先考虑延迟而不是带宽,因为通常根据延迟来判断他们的工作负载集。像英特尔 Sapphire Rapids+HBM 这样的产品提供了很好的带宽提升,但不足以挑战 GPU。
接下来看下面与功耗和成本有关的公式:

首先看功耗方面,从图中可以看到,Pj/Flop 在主流半导体工艺方面并没有显着改善。你*可以玩的游戏是flop的定义,我们把它从64降低到4..现在可能是1.5。今天 FP16 的 pj/flop 在 0.5-0.7 的范围内。
peta-flop GPU 的快速计算,10^15 * (0.7*10^-12) = 700 瓦。带宽的功率计算起来有点棘手,并且可能会踩到供应商的一些专有信息,在这里就不深入分析了。
Pj/Bit 是我看到架构师可以利用的重要 (10 倍) 机会的地方。我认为本十年的下半年将看到许多有趣的尝试,包括围绕近内存、内存计算、共封装光子学等的举措。
再看成本方面,每个节点的计算晶圆成本都比较昂贵,内存人员也在利用人工智能的需求。
Raja Koduri表示,在10 年前,他不会将“封装”作为主要成本要素,但现在这是一件大事。除了先进的封装外,与热能和电力输送相关的成本也大幅上升。部分成本在物理上是合理的 - 但其中很大一部分是由生态系统驱动的,试图在英伟达贪婪的利润率下支撑他们的利润率。
在Raja Koduri看来,使用替代封装方法可以显著(2-3 倍)降低成本,避免昂贵的有源中介层 + 2.5D/3D 堆叠。但目前尚不清楚它们是否会很快成为消费者的利益,直到人工智能需求与供应达到更合理的水平。
最后,看看公式的其他部分。

首先看Compatibility(兼容性),这里涉及有趣的 GPU 历史。
Raja Koduri介绍,在2002 年,GPU行业引入了 24 位浮点的可编程着色器(与非凡的 ATI R300 一起),并引入了高级着色语言(HLSL、GLSL、Cg),这些语言主要是基于 C 的语言,具有关键约束和扩展。这对游戏引擎开发人员来说是一个福音,我们见证了 2002 年至 2012 年间实时渲染的指数级进步。但是对于熟悉本机 C/C++ 的通用程序员来说,这些语言很尴尬。因此,GPU 主要局限于游戏开发者。
到了2005 年,高性能 IEEE FP32 的推出引发了 GPGPU 的热潮——这要归功于 Mike Houston、Ian Buck 等斯坦福大学校友,他们推动了早期的 GPGPU 语言,如 Brook 和 ATI 提出了一种称为 CTM(Close to the metal)的汇编级抽象。虽然这些努力对于演示来说很棒,但它们并没有越过“兼容性”的门槛,在学术研究之外获得任何严肃的兴趣。
而CUDA(以及出色的 Nvidia G80 架构)是*个将“指针”(pointers)引入 GPU 语言的,并为 C 程序员提供了更舒适的抽象来使用 GPU。正如他们所说,休息是历史。指针和虚拟内存支持也是将 GPU 作为一流的协处理器集成到所有操作系统中的关键。这是硬件加速器设计经常忽视的一个方面,这使得为这些加速器编写驱动程序成为软件工程师的噩梦。
Raja Koduri认为,CUDA的另一个方面没有得到广泛的赞赏。如她所说,CUDA 编程模型是 NVIDIA GPU HW 执行模型的真正抽象。硬件和软件是共同设计的,并系在HIP(原文:The hardware and software are co-designed and tied at the hip)。虽然许多像 SPMD 这样的 CUDA 模型都具有可移植性(OpenCL、Sycl、OpenMP、HIP-RocM...),但实现性能可移植性几乎是不可能的(除非您的架构是精确复制的 CUDA GPU 执行模型)。鉴于涉足 GPU 的程序员将加速作为主要目标,无法帮助您高效地实现良好性能的语言和工具无法获得 CUDA 的吸引力。
“CUDA 程序员与 Python/Pytorch 程序员之间有一个有趣的对比 - 但这是另一个时间的线程”,Raja Koduri说。
Raja Koduri承认,CUDA 改进了 GPU 通用性以吸引 C/C++ 程序员。
“对于诞生于python时代的下一代硬件架构师来说,下一个成功的软硬件协同设计会是什么?”Raja Koduri接着说。
来到Extensibility(扩展)方面。
Raja Koduri表示,GPU 架构以增量方式扩展了很多次。我发现令人惊讶的是,我们仍然可以在现代 GPU 上运行 20+ 年前构建的游戏二进制文件。虽然在微观架构方面取得了许多进步,但宏观层面看起来仍然是一样的。我们添加了许多新的数据类型、格式、指令扩展,同时保持兼容性。甚至在保留 SPMD 模型的同时添加了张量单元。这种可扩展性使 GPU 能够快速适应新的工作负载趋势。
一些专家批评 GPU 对于纯张量数学来说非常“低效”——提出并构建了与 GPU 架构不兼容的替代架构。然而,我们仍在等待这些架构之一产生有意义的影响。
再看Accessibility(可及性)方面。
在Raja Koduri看来,这是 GPU 最被低估的优势。您的架构需要可供所有地区的广大开发人员访问。在这方面,游戏GPU对Nvidia来说是一个巨大的福音。我们经常看到世界各地的年轻大学生通过笔记本电脑或台式机中的 3060 等中端游戏 GPU 开始首次体验 GPU 加速。Nvidia 在使其开发人员 SDK 可在装有 Windows 和 Linux 的 PC 上访问方面做得非常出色。
但Raja Koduri认为,对计算和带宽的需求每年增长 3-4 倍。根据这里列出的*个原则,CUDA GPU 硬件将被中断。*的问题是“谁”和“何时”?
在回答读者的问题时,Raja Koduri表示,Python 和内存是他认为CUDA GPU将会被颠覆的底气。
03 软件将成为新焦点
而在AMD最近收购 Silo AI之后,有分析师认为,软件已成为焦点,人工智能芯片战场发生变化。分析师认为,这一战略转变正在重新定义人工智能竞赛,其中软件专业知识变得与硬件实力一样重要。
分析师表示,AMD 最近收购了欧洲*的私人 AI 实验室 Silo AI,这体现了这一趋势。Silo AI 在开发和部署 AI 模型方面拥有丰富的经验,尤其是大型语言模型(LLM),这是 AMD 关注的一个关键领域。
此次收购不仅增强了 AMD 的 AI 软件能力,也加强了其在欧洲市场的地位,Silo AI 在欧洲市场以开发文化相关的 AI 解决方案而享有盛誉。
Counterpoint Research 合伙人兼联合创始人 Neil Shah 表示:“Silo AI 填补了 AMD 从软件工具(Silo OS)到服务(MLOps)的重要能力空白,帮助定制主权和开源 LLM,同时扩大其在重要欧洲市场的影响力。”
AMD 此前已收购 Mipsology 和 Nod.ai,进一步巩固了其致力于打造强大 AI 软件生态系统的承诺。Mipsology 在 AI 模型优化和编译器技术方面的专业知识,加上 Nod.ai 对开源 AI 软件开发的贡献,为 AMD 提供了一套全面的工具和专业知识,以加速其 AI 战略。
Cyber media Research 行业研究组副总裁 Prabhu Ram 表示:“这些战略举措增强了 AMD 为寻求跨平台灵活性和互操作性的企业提供定制开源解决方案的能力。通过整合 Silo AI 的功能,AMD 旨在提供一套全面的套件,用于开发、部署和管理 AI 系统,广泛满足不同客户的需求。这符合 AMD 作为可访问和开放 AI 解决方案提供商不断发展的市场地位,充分利用行业对开放性和互操作性的趋势。”
这种向软件的战略转变并不局限于AMD。其他芯片巨头如Nvidia和Intel也在积极投资软件公司并开发自己的软件堆栈。
Shah 表示:“如果你看看 Nvidia 的成功,你会发现它不是由硅片驱动的,而是由其在计算平台上提供的软件(CUDA)和服务(带有 MLOps、TAO 等的 NGC)驱动的。”“AMD 意识到了这一点,并一直在投资构建软件(ROCm、Ryzen Aim 等)和服务(Vitis)功能,为客户提供端到端解决方案,以加速 AI 解决方案的开发和部署。”
Nvidia 最近收购了 Run:ai 和 Shoreline.io,这两家公司均专注于 AI 工作负载管理和基础设施优化,这也凸显了软件在*限度提高 AI 系统性能和效率方面的重要性。
但这并不意味着芯片制造商会遵循类似的轨迹来实现目标。Techinsights 的半导体分析师 Manish Rawat 指出,在很大程度上,Nvidia 的 AI 生态系统是通过专有技术和强大的开发者社区建立起来的,这使其在 AI 驱动的行业中站稳了脚跟。
Rawat 补充道:“AMD 与 Silo AI 的合作表明,AMD 将集中精力扩展其在 AI 软件方面的能力,在不断发展的 AI 领域与 Nvidia 展开竞争。”
另一个相关的例子是英特尔收购实时持续优化软件提供商 Granulate Cloud Solutions。Granulate 帮助云和数据中心客户优化计算工作负载性能,同时降低基础设施和云费用。
芯片和软件专业知识的融合不仅是为了赶上竞争对手,还为了推动人工智能领域的创新和差异化。
软件在优化特定硬件架构的 AI 模型、提高性能和降低成本方面发挥着至关重要的作用。最终,软件可以决定谁主宰 AI 芯片市场。
Amalgam Insights 首席执行官兼首席分析师 Hyoun Park 表示:“从更大角度来看,AMD 显然正在与 NVIDIA 争夺 AI 领域的霸主地位。归根结底,这不仅仅是谁制造出更好的硬件的问题,而是谁能够真正支持部署高性能、管理良好且易于长期支持的企业级解决方案。尽管 Lisa Su 和 Jensen Huang 都是科技界最聪明的高管之一,但只有其中一人能够最终赢得这场战争,成为 AI 硬件市场的*。”
软件专业知识与芯片公司产品的整合正在催生全栈 AI 解决方案。这些解决方案涵盖从硬件加速器和软件框架到开发工具和服务的所有内容。
通过提供全面的 AI 功能,芯片制造商可以满足更广泛的客户和用例,从基于云的 AI 服务到边缘 AI 应用。
例如,Shah 表示,Silo AI 首先带来了经验丰富的人才库,尤其是致力于优化 AI 模型、量身定制的 LLM 等。Silo AI 的 SIloOS 是 AMD 产品的一个非常强大的补充,允许其客户利用先进的工具和模块化软件组件来定制符合其需求的 AI 解决方案。这对 AMD 来说是一个巨大的差距。
Shah 补充道:“第三,Silo AI 还引入了 MLOps 功能,这对于平台参与者来说是一项关键功能,可以帮助其企业客户以可扩展的方式部署、改进和运营 AI 模型。这将帮助 AMD 在软件和硅片基础设施之上开发服务层。”
芯片制造商从单纯提供硬件转向提供软件工具包和服务,这对企业科技公司产生了重大影响。
Shah 强调,这些发展对于企业和人工智能开发人员微调他们的人工智能模型以增强特定芯片上的性能至关重要,适用于训练和推理阶段。
这一进步不仅加快了产品的上市时间,而且还帮助合作伙伴(无论是超大规模企业还是管理内部部署基础设施)通过改善能源使用和优化代码来提高运营效率并降低总拥有成本 (TCO)。
“此外,对于芯片制造商来说,这是一种很好的方式,可以将这些开发人员锁定在他们的平台和生态系统中,并在其基础上通过软件工具包和服务获利。这还可以带来经常性收入,芯片制造商可以再投资并提高利润,投资者喜欢这种模式,”Shah 说。
随着人工智能竞赛的不断发展,对软件的关注必将加剧。芯片制造商将继续投资软件公司,开发自己的软件堆栈,并与更广泛的人工智能社区合作,打造一个充满活力和创新的人工智能生态系统。
人工智能的未来不仅在于更快的芯片,还在于更智能的软件,它可以释放人工智能的全部潜力并改变我们的生活和工作方式。
综上所述,大家认为GPU主导的市场,会被颠覆吗?










