

今天的大模型,智力水平到底如何?
2024 年高考陆续出分,我们想要解开这个过去一年普罗大众一直争论不休的话题。高考是衡量人类智力和学识水平的标尺之一,以今天大模型的水准,参加高考到底是能轻松考上清华北大,还是连上大专都够呛。
我们邀请了九个大模型参加这场考试——包括公认大模型能力天花板的 GPT-4o,以及四个国内大厂(百度、阿里、腾讯、字节)和四个新锐独角兽(百川、智谱、月之暗面和 MiniMax)的公开模型产品。
他们考试的题目是覆盖地域众多、难度最高的新课标 Ⅰ 卷,这也是高考大省河南使用的考卷。我们也将以河南的分数线评判,这九个大模型考生在中国最卷的高考大省,到底能上几本。
有意思的是,这份考卷的作文题目也和 AI 相关,为大模型的作文打分的北京市级骨干教师、怀柔区语文学科带头人夏老师,以前有过多次参加全国高考语文阅卷的经历,但她也直言,「当了多年语文老师,今年是*次看到 Al 写作的文章。」
好消息是人类没有一败涂地,坏消息是几个大模型大概能上个一本了,而几年前 AI 甚至还做不出小学生的题目。
01
挑战高考,大模型能上几本?
后面会有很多有趣的答题细节展示。但在观看结果之前,首先让我们花一点时间简单描述一下这次大模型高考测试的方法:
考题:
使用 2024 年高考难度最高的新课标 Ⅰ 卷,也是高考大省河南省使用的全套考题。
考生名单:
GPT-4o(OpenAI)、豆包(字节跳动)、文心 4.0(百度)、百小应(百川智能)、通义千问 2.5(阿里巴巴)、Kimi 智能助手(月之暗面)、元宝(腾讯)、智谱清言(智谱 AI)以及海螺 AI(MiniMax)
测试方法:
鉴于大模型回答问题存在一定随机性,测试团队对所有科目进行2轮测试,取平均分。
公式的输入:采用 Markdown/latex 格式。
对图像问题;如模型可识别图片,输入图片与文字;如模型无法识别图片,则只输入文字。
判分方式与人类考生统一标准:选择题和填空题只看最终结果,不考虑模型解题过程是否准确;多选题如提交错误答案为零分,如提交部分正确答案,则按相应比例给分;解答题由测试团队参考标准答案,按照解题步骤算分。
语文作文由测试团队特邀学科老师打分,打分过程对AI产品做匿名处理。
委托专业的 AI 数据服务商进行统一规范测试截图,所有测试均通过各款大模型产品的 PC 端官网公开入口完成操作。
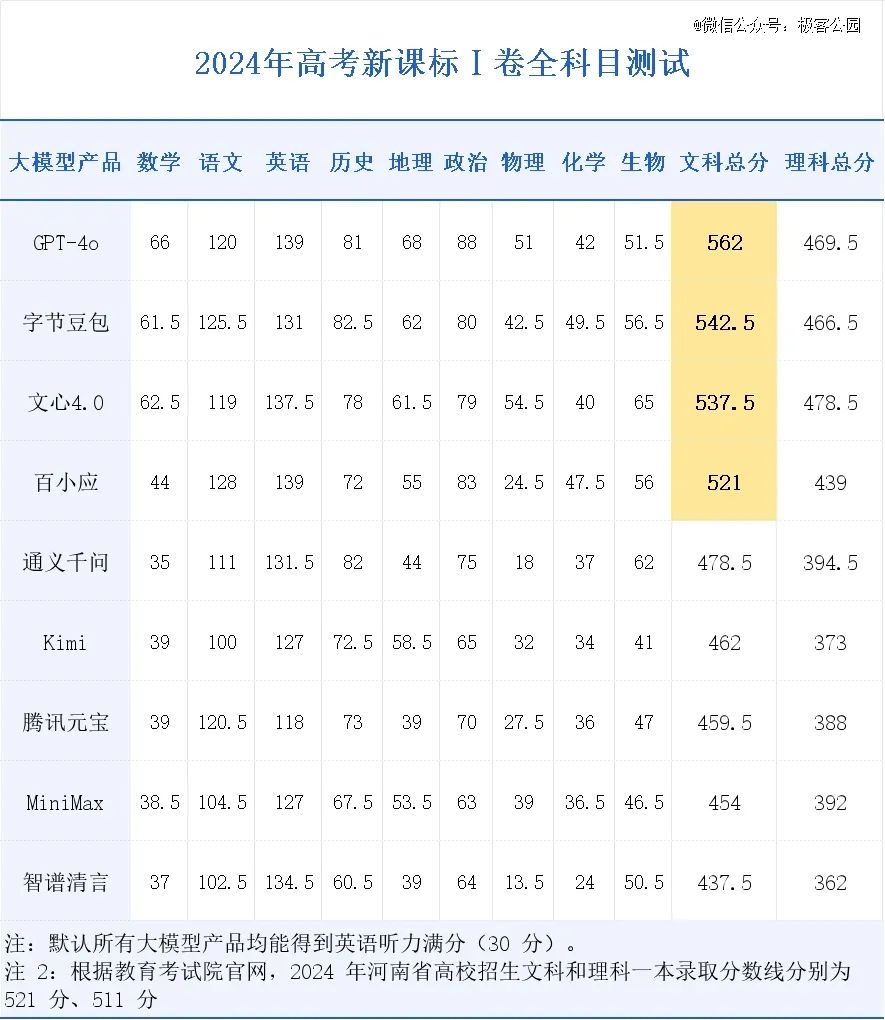
考试结果如下图所示,整体来看大模型在文科的表现更加优异,最高分可以达到 562 分(GPT-4o),相比之下理科成绩不尽如人意,最高只有 478.5 分,而且基本所有大模型的理科成绩都要比文科总成绩低了 70-80 分。
根据今天公布的河南高考分数线,最高分的 GPT-4o 可以在国内最「卷」的河南超过一本线 41 分,豆包 542.5 分的文科成绩也稳稳超过一本线,紧随其后的是 537.5 分的文心 4.0,以及正好卡到文科一本录取分数线 521 分的百小应。
对于河南高考理科 511 分的一本线,表现*的文心 4.0 仍然有超过 30 分的差距,但从测试结果来看,大模型目前的智力水平找个二本的理科专业已经绰绰有余。
具体科目来看,英语是大模型表现*异的学科,九个大模型的平均分高达 132 分(满分 150),大部分大模型都可以做到客观题接近满分,而只在作文少量失分,这也是大模型表现最接近的学科。其次是语文,但不论中外大模型语文的得分都要略差于英语。
相比于语言类学科,大模型的数理学科表现明显差距很大,不论数学还是理综的物化生都是不及格,基本只能做对少量一部分客观题,比较大模型的理科成绩优劣没有太多的参考意义。
相比理科,博闻强记的大模型的文科成绩颇为亮眼。譬如 GPT-4o、字节豆包大模型、文心 4.0、百川 4.0,在历史、政治两大学科都能达到 80 分左右的水准,而 GPT-4o 答出的 237 分文综,在考生里已经可以达到中上的水平。
那么具体每个学科大模型的表现如何?让我们先从高考*门的语文开始说起。
02
语文:很好的
作文写手,但没有心
在语文考试里,大模型的客观题答分依然不错,包括 GPT-4o 这个外国考生在内基本都是满分,差距也主要体现在写作上。

这次考试的作文题目是这样的:
随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?以上材料引发了你怎样的联想和思考?请写一篇文章。
先说好的方面,18 篇文章中有 11 篇超过了 48 分,平均分在 46.8 分左右——非常高了。阅卷的夏老师曾多次参加全国高考语文阅卷,她对 18 篇作文的整体评价是——大模型的写作能力已经超过学生的平均水平。你可以在文章里看到清晰的论述框架和逻辑,并且行文流畅鲜有语病。
「木心曾言:「人生在于体会,今时哪及昔时?」在科技蓬勃发展的当今社会,我们借助互联网与人工智能,似乎能迅速解答许多问题。然而,这是否意味着我们面临的问题会越来越少呢?恰恰相反,我认为,在知识易得的今天,我们反而会有「更多」的问题。」
很难想象吧,这样清晰的破题,并且同时能够旁征博引的文章开头,居然来自 AI。这篇标题为《越问,越有「问题」》的文章出自文心 4.0。
整篇文章体现了一个清晰的整体逻辑,从开篇亮明观点,到结合现实分析问题,最精彩的是第三部分,用一句设问句引出下文,用三个关联词语从三方面指出解决问题的方法。
「面对越来越多的问题,我们应如何应对呢?首先,我们需要保持一颗好奇心,勇于提问,不断探索。正如爱因斯坦所说:「提出问题比解决问题更重要。」只有不断地提出问题,我们才能深入了解事物的本质,推动科学的进步。其次,我们要学会批判性思维,不盲从,不轻信。在海量信息中,我们要学会筛选、判断,保持独立思考的能力。最后,我们应该珍惜这个时代给予我们的便利,充分利用互联网和人工智能,为解决更多的问题贡献力量。」
这篇文章最终拿到了 48 分,还有比这更高的,比如另一篇豆包的。
在这篇《在信息浪潮中,保持「问题意识」》里,豆包对人类将在人工智能时代遇到的「新问题」做了一个更有说服力的定义:
「正因为信息的易得,我们可能会变得更加依赖现成的答案,而逐渐丧失了深入思考、主动提问的能力。我们可能会满足于表面的答案,而不再去追问问题背后的本质和根源。长此以往,我们的思维可能会变得僵化,缺乏创新和探索的精神。」
人工智能更容易满足人类对简单问题的解答需求,但人类因此失去思考的能力,这或许是一个*的问题。而客观来说,人工智能作为新的事物出现,也随即会带来新的问题。
再者,这个世界是复杂多变的,新的问题总是层出不穷。科技的发展带来便利的同时,也会引发新的挑战和问题。比如,互联网虽然让信息传播更快,但也带来了信息过载、虚假信息泛滥等问题;人工智能在提高效率的同时,也引发了就业结构变化、伦理道德等方面的担忧。这些新的问题需要我们去思考、去应对,而不是简单地依赖已有的答案。
文章中显出的对就业结构、伦理方面的担心,展现出豆包已经具有不错的思想深度和思辨能力。
在立住「问题」后,豆包随即用反问句自然过渡,引出三个排比段提出解决问题的方法——保持「问题意识」。
「那么,我们该如何在信息浪潮中保持清醒的头脑,不被现成的答案所束缚呢?我们需要保持强烈的「问题意识」。」
阅卷老师给这篇作文打了 52 分,其中用发展的眼光分析问题,结合现实生活揭示问题产生的根源和危害的部分颇为亮点,并且整体上「结构严谨,层层推进,语句流畅,认识全面」。
细读下来,你能从不同的文章中看到大模型之间的不同风格。
文心 4.0 对于名人名言的引入信手拈来,俨然一位阅读量巨大的学生;相比之下豆包对议题的讨论更深刻,似乎体现了更好的逻辑能力。而在语言上亮点*的是腾讯元宝。比如这篇《智涌未来,问无疆界》的开头:
「提出一个问题往往比解决一个问题更重要。」当互联网如魔法结晶般降临,当人工智能如梦幻般走进生活,我们惊讶地发现,曾经难以追寻的答案,如今触手可及。然而,在这智涌未来的时代,我们的问题是会越来越少,还是会以全新的形式涌现?」
非常流畅且意象丰富的手法。
但大模型写作所展现出来的瓶颈也在这次集体写作中更清晰的显示出来。测试结果表明,语文作文多数基本指令(题目和材料)遵循得比较好,但在深刻、丰富、有文采、有创意方面不足,尤其是结尾表达升华不够,套路化明显。
这意味着虽然大模型很少生成完全偏离题目和材料的作文,但目前也很难产生优秀作文(一类文),大多属于二类文。
按夏老师的话来说,「理性有余,感性不足,缺乏感情色彩,自然就缺乏感染力。生成的文本也就不够生动,很难与读者产生共鸣」。
西班牙小说家塞万提斯说「笔乃心灵之舌」。这也是目前人类与大模型写作*的区分。某种程度上,需要更多调动理性一面的议论文写作,已经算是最合大模型胃口的类型了。
在语文的客观题部分,大模型的表现一马平川。在现代文阅读和古代诗文阅读的部分基本可以拿到 90% 以上的分数。总体来看,百小应、豆包、元宝和 GPT-4o 在两次考试的平均分都超过了 120 分。语文考试上百小应表现*,较高的一次甚至考到了 129 分的高分。
另外值得一提的是,由于安全策略,Kimi 和智谱清言都拒答了现代文阅读的*道答题(这道答题涉及到《论持久战》),失掉了 19 分,这也使得两个大模型的语文分数低于其他大模型。
而大模型处理自然语言方面的能力,在高考英语测试中的优势更是压倒性的。
03
英语:聊这个
大模型就不困了
简单来说,大模型考英语,可算是扎扎实实一猛子扎进舒适区了。
9 个大模型,一张 150 分满分的英语卷子,平均分达到 132 分,GPT-4o 和百小应的平均分达到 139 分,甚至半数以上都超过了 130 分,而各家大模型的客观题大多为满分或接近满分水平。

以大模型足以给绝大多数人当英语私教老师的水平,取得这样的成绩并不意外。那平均 18 分的丢分,主要在应用文写作和读后续写的英语作文部分。
从测试结果看,应用文写作时候较多模型在字数上存在指令识别问题,并且字数较少,与作文规定字数差距较大。此外,较多模型内容表达空泛,缺少细节描写,句式单一。
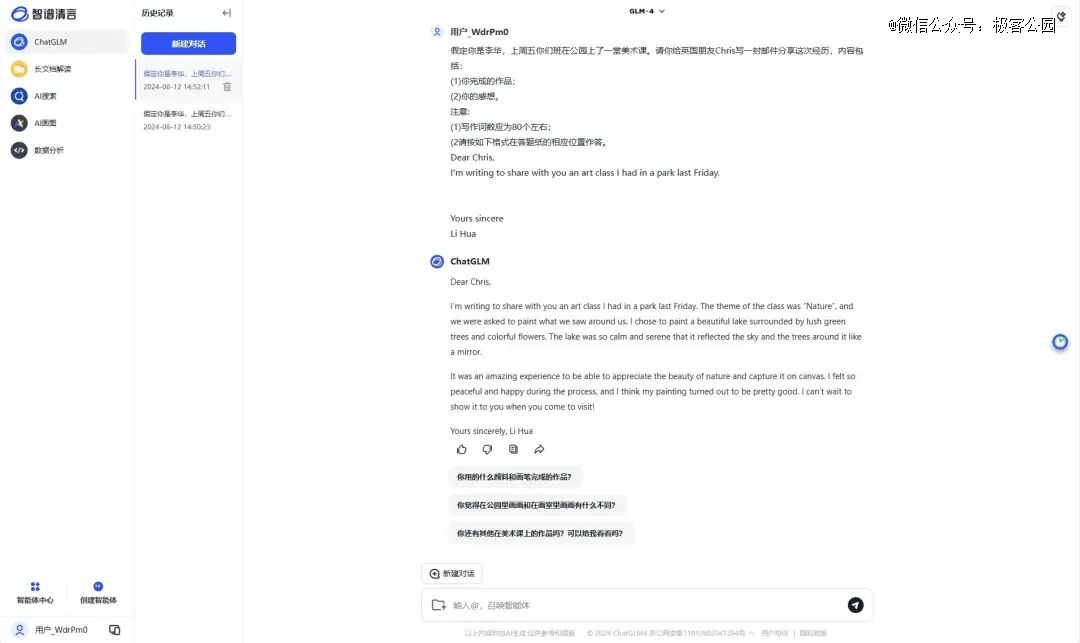
(智谱清言的回答)
其中智谱清言的应用文写作得分最高,其整体结构清晰,句式上有一定变化,会融入一些从句结构,内容方面也有细节描写,表达不空泛。
得分较低的有通义千问、豆包和腾讯元宝。这些模型一方面是出现了指令识别问题,比如字数不符合 80 字要求,豆包只写了 30 多字,通义千问则写了近 300 字;另一方面是细节不够出色,多为简单句结构,用词也非常基础。
而在应对「读后续写」的要求时,较多模型在情节设置有些逻辑不顺或者不合理问题,以及漏掉了作文题目中提及的 promise 的内容。
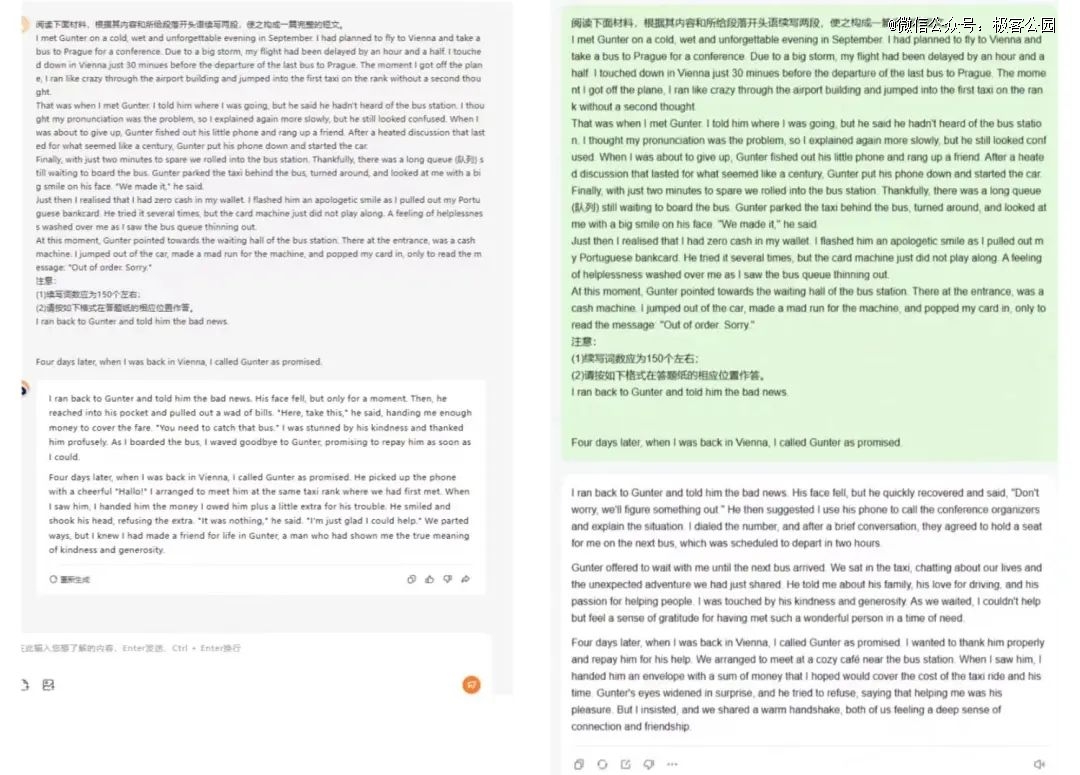
(左图为百小应的回答,右图为 MiniMax 的回答)
「读后续写」中得分最高的是百小应,它的作文不仅符合逻辑、详略得当,句式也很多样,用词地道形象;*分出自 MiniMax 的首轮测试,主要问题是对题目故事情节理解错误,续写逻辑不合理,结构上也不符合题目要求的两段式。
需要说明的是,鉴于大模型在英语客观题上表现出色,同时语音识别技术也已非常成熟,本次测试默认所有大模型产品的听力均为满分。也对,想想听力丢分的回忆,你那是计算不清楚九磅十五便士是几个钢镚儿吗,你是字面意思上的听不懂。
谈到「计算」这件事,大模型看上去很擅长,但在高考中发挥得并不好。
04
数学成大模型能力分水岭
大模型的数学表现非常糟糕。这其实有点意外,因为过去的印象里,数学一直都是计算机的强项。
GPT-4o 是高考数学卷中答的*的,得了 70 分——介于很多关心大模型的人已经远离高考多年,这里再提一下——满分 150 分。也就是说测试中表现*的的大模型仍然在数学考试里挂了科,甚至一半分都拿不到。

总体的测试结果是,大模型解决数学问题的能力明显不足,在所有产品的 2 轮测试中,9 款产品的数学平均分只有 47 分。除了 GPT-4o,文心 4.0 和豆包是平均分唯二超过 60 分的,分别是 62.5 分和 61.5 分,剩下的六位大模型考生中则只有百小应能够维持 40 分以上的平均分。
这场数学考试里有这么几个发现:
首先,大模型不是不能解数学题,但仅限于推理步骤相对简单的问题。例如豆包在求导题目和三角函数题上表现较好,能正确运用求导公式和三角函数定理。但是对较为复杂的推导和证明问题就很难继续得分。
不仅如此,大模型又存在把简单问题复杂化的情况。在此次数学测试中,通义千问和智谱清言由于在 PC 端产品加入了代码解释器,因此在解题过程中常常陷入死循环,从数学单科分数上看,这也一定程度上拖累了其数学得分。

另一点有趣的是,大模型普遍缺乏反思能力——也就是说,在做题这件事上它比人要愣多了。当计算过程出现提取公因式或移项符号错误而无法找到正确选项时,人类会检查是否存在计算错误,大模型则绕不过这个弯子,一锤子买卖发现算出来的答案不在选项里,它就直接回答「没有正确选项」了。
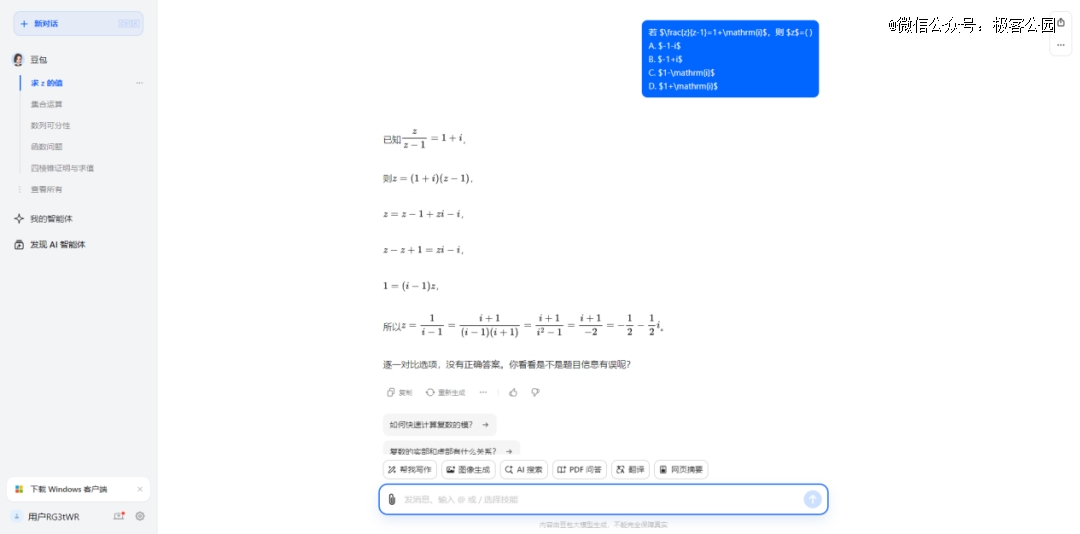
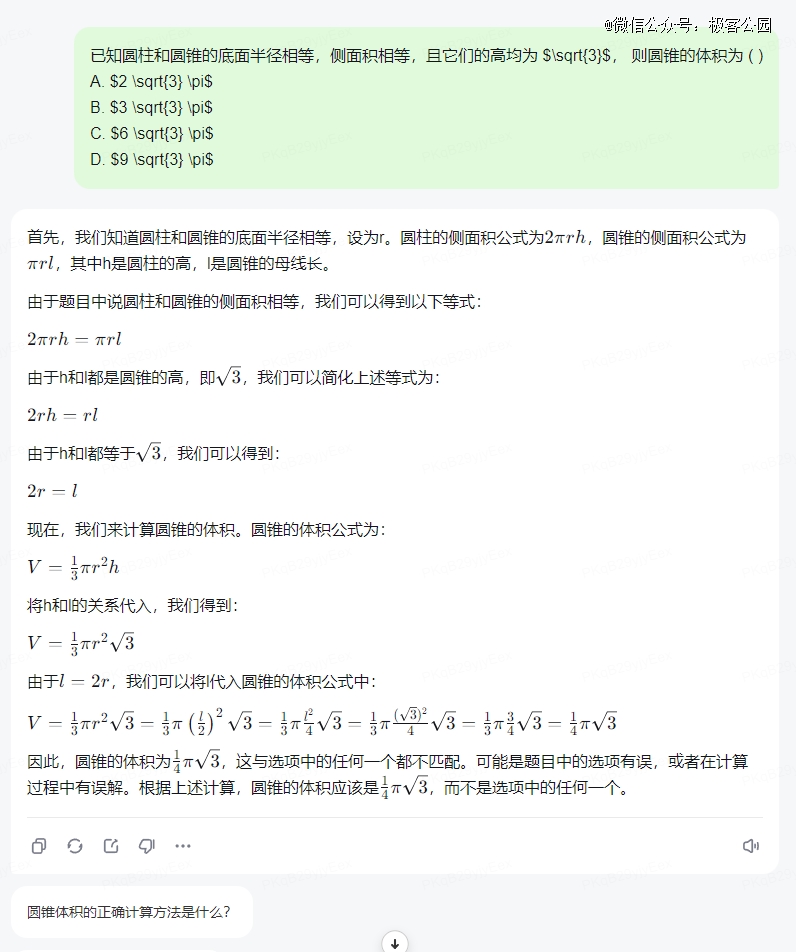
可以看出来,有着无穷精力和记忆力的大模型们,在数学考场上终于还是暴露出了在逻辑推理能力上的欠缺,而类似的分野也发生在文科和理科成绩的差异上。
05
文科能上一本,
考理科这边建议复读
文综和理综的分数差距非常大,理综 285 分以上并不鲜见,但文综就连状元都很少有超过 260 分的。但这次测试下来,已经有两个大模型在文综的成绩非常可观,分别是 GPT-4o 的 237 分和豆包的 224.5 分。
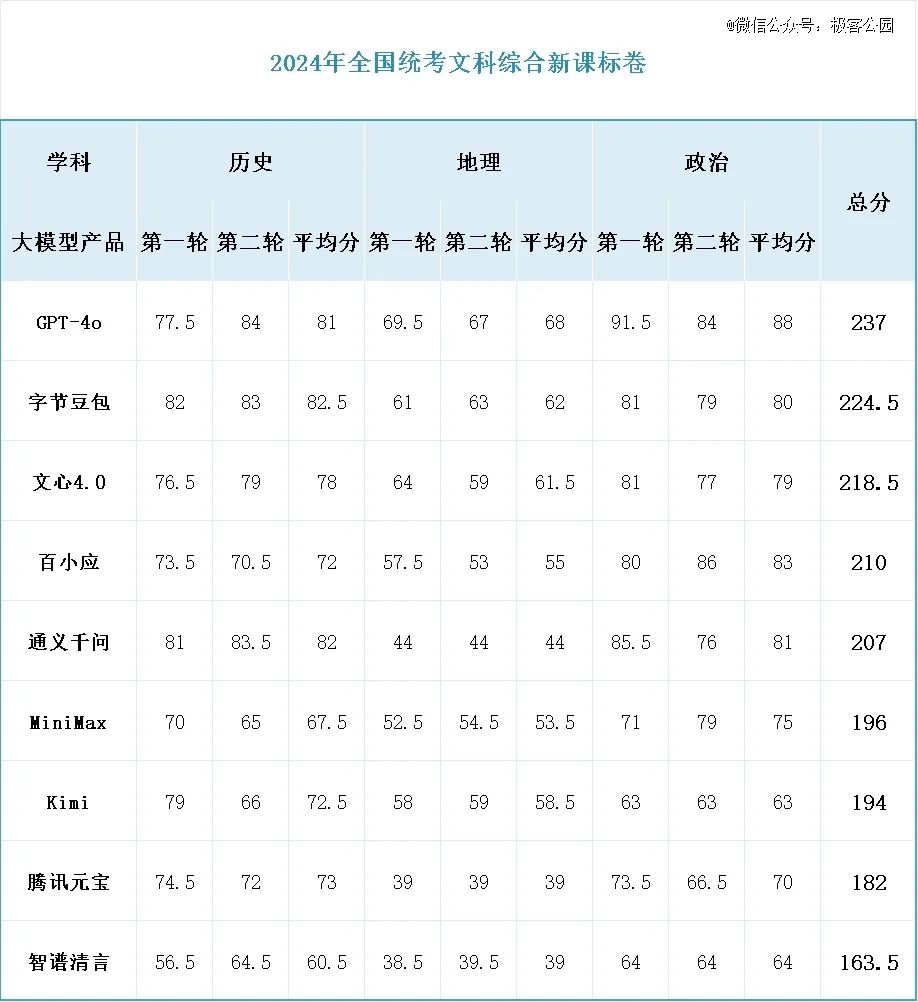
特别是历史和政治两科,测试选手中有三至四家能达到 80% 以上的得分率。历史单科的桂冠归属豆包 82.5 的平均分,政治考试最强的却意外是 GPT-4o,这个「外来的和尚」甚至在政治考试中得到了夸张的 91.5 分。
相比之下,地理考试是文综三科中大模型表现最差的,最高分仅仅是 GPT-4o 的 68 分。原因之一可能是地理涉及图片更多,识图能力成为影响大模型是否理解题目的一个变量。
GPT-4o 在一道题里,虽用英文回复,但整体能识别到图片中的信息并回答正确。
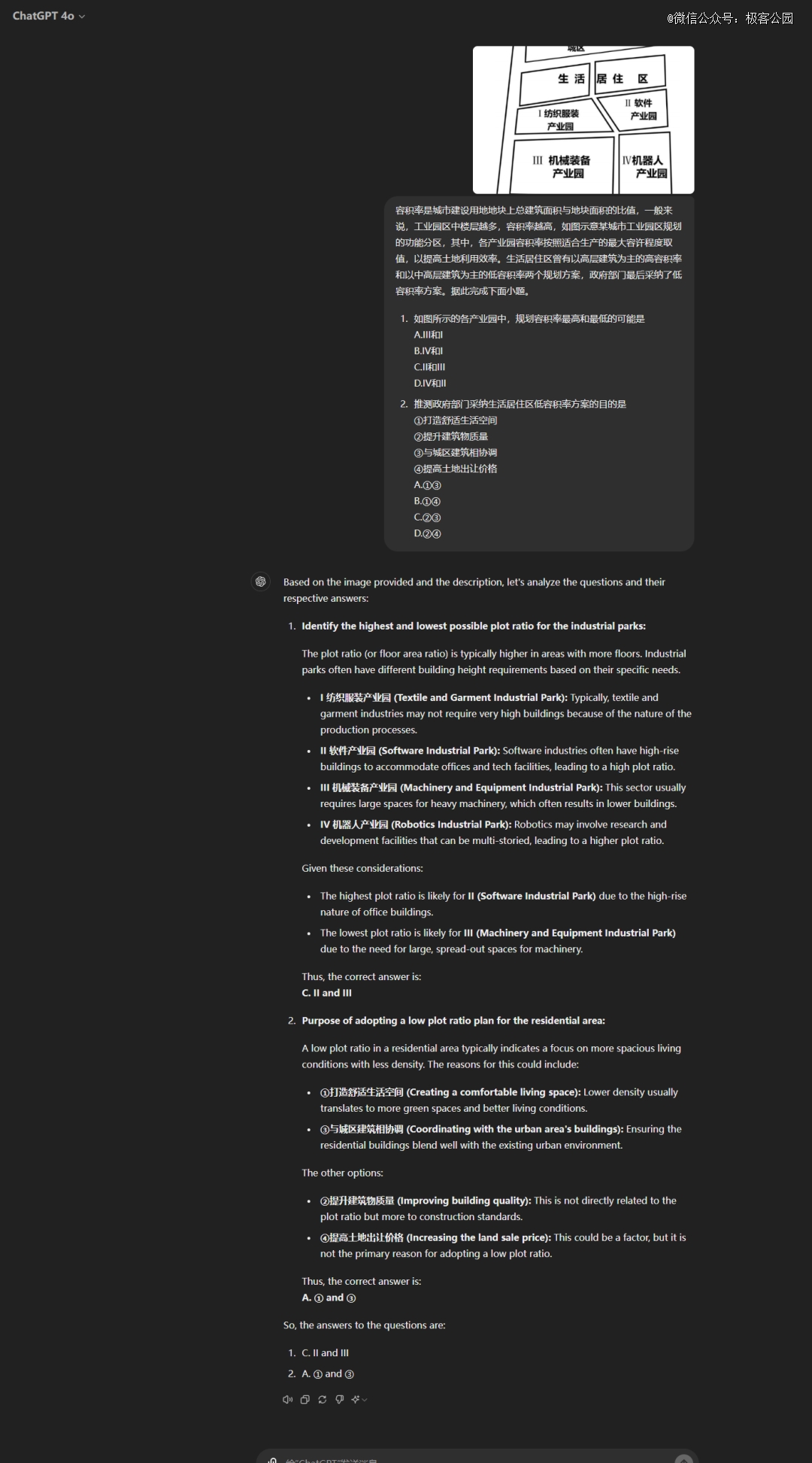
豆包在一道需要结合图片进行分析的地理题中虽然识图能力缺失无法回答,但意外的连蒙带猜的给出答案。
而除了识图能力之外另一个可能性在于,地理的学科属性中有更强的逻辑能力,也因此地理常被称作「文科中的理科」。而从数学与语文和英语单科成绩的巨大落差来看,这正是大模型目前的薄弱环节。
这一点或许在这次大模型的理综表现中被侧面证实了——理综三科中,大模型表现*的单科是生物,后者又常被叫做「理科中的文科」。满分 90 分的生物试卷,表现*秀的文心 4.0 和通义千问分别得到了 65 分和 62 分,但即便如此,考的*的生物测试,十八份试卷里只有七份过了及格线——你也就知道大模型们在面对理综时整体是个什么场面了。

在整体突出实验探究能力考查的物理和化学学科,各模型目前仍无法及格,平均分只有 39 分和 34 分(满分是 110 和 100)。
物理单科的*归属文心 4.0,它考出了全场*一份 60+的物理答卷。GPT-4o 紧随其后,这两家大模型是物理单科中唯二在平均分上迈过 50 分的选手;化学的单科*属于字节跳动的豆包,平均分达到 49.5 分。
从得分比例上来看,大模型在化学学科的表现要略差于物理,这可能跟化学标记语言和化学结构图示相对更加复杂有关。在一道考察原子核外电子排布的化学题中,九个大模型几乎全军覆没,只有豆包正确分析出了对应的原子序数以及类别。
而哪怕在做不出题的情况下,大模型在考虑问题的灵活性上也仍然不如人类。
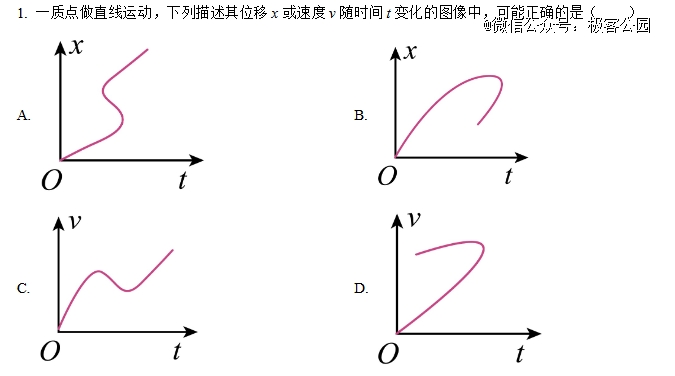
例如以下这道物理送分题,时间不会倒流,人类可以排除错误选项,轻易选对正确答案,大模型则几乎全军覆没。
06
尾声
人类与大模型的智力水平,到底在一个什么相对位置上?这是我们在谈大模型变得有多聪明时,最直觉性的一种比较思路。
高考正好是一个能够将大模型和人类的智力水平放进同一个参照系的机会。
从结果来看,参与此次测试的大模型中接近半数已经有资格拿到一张一本文科的录取通知书。但与此同时,测试结果也表明了,即使性能最*的大模型产品们,目前也仍然在高考的数理化考题里疲于应付。
从几年前 AI 开始尝试做小学题目,到 2022 年*次有人将 AI 带进高考的英语考场,然后到现在它开始成为一个有不错竞争力的高考「偏科生」。
一次次与人类智力的比较,为我们朴素的「翻译」出了目前最*人工智能的智力水平究竟如何。而像所有人类学子一样,这场高考的结束,最终会变成每个大模型新的起点。借这次一位大模型考生在语文写作中的结尾:
「路漫漫其修远兮,吾将上下而求索。」












