

ChatGPT问世以来,立刻在金融业引发了焦虑感,这个对技术有信仰的行业唯恐被一个飞奔中的时代洪流甩在身后。这种焦灼氛围,甚至一度卷到清净的寺庙。一位业内人士告诉数智前线,她在5月份去到大理出差时,在寺庙里都能碰到和她谈论大模型的金融人。
不过,这种焦虑正在慢慢归于寻常,大家的思路也开始清晰和理性。软通动力银行业务CTO孙洪军向数智前线描述了今年金融业对大模型态度的几个阶段:二三月,大家都很焦虑,怕落后;四五月,纷纷组建团队去做;之后几个月,大家在找方向、落地上遇到了困难,开始变得理性;现在,他们看标杆,把验证过的场景拿来试用。
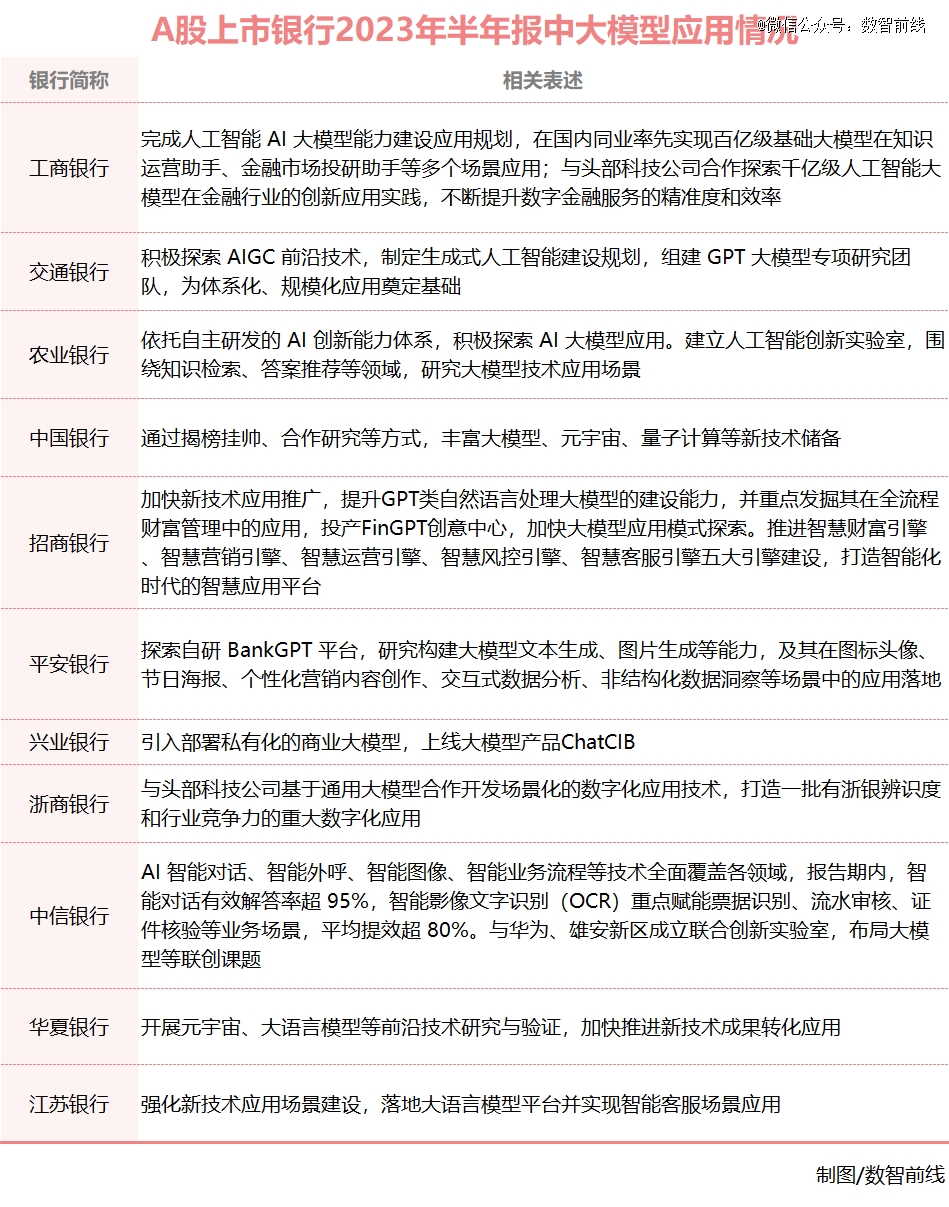
一个更新的趋势是,不少金融机构都已将大模型从战略层面重视起来。据不完全统计,A股上市公司中,至少有工商银行、农业银行、中国银行、交通银行等11家银行,都已在最新半年报中明确提出正在探索大模型的应用。从近期动作看,他们也正在从战略层面和顶层设计层面有更清晰的思考和路径规划。
01 从热情高涨到理性回归
“比起几个月前,现在能明显感觉金融客户对大模型的理解好了很多。”一位大厂金融行业资深人士告诉数智前线,年初ChatGPT刚出来时,大家的热情虽高,但对于大模型究竟是什么、该怎么用,其实了解得非常有限。
这一阶段,一方面一些大行率先行动,开始做各种“蹭热度”的宣传。比如早在今年3月,农行上线了类ChatGPT的大模型应用ChatABC。但业界评价不一。其时,一度有人认为,ChatABC这个名字强调了ChatGPT里不那么重要的Chat,反而忽略了GPT这个真正重要的部分。
另一方面,随着百度等多家厂商陆续发布大模型,一些头部金融机构的科技部门开始积极去跟大厂谈论大模型建设的事情。上述资深人士透露,这些金融机构的普遍诉求是,要自己去做一个大模型,希望厂商告诉他数据集怎么做,买多少服务器,怎么去训练。建行旗下的金融科技公司建信金科甚至提出,完成后是不是还能去做一些同业输出。
5月份以后,情况逐渐变化。受制于算力资源紧缺、成本高昂等大背景,很多金融机构开始从单纯希望自己建算力、建模型,转变到更加关心应用的价值。“现在每一家金融机构都在关心其他人用大模型做了什么,实现了怎样的效果。”
具体到不同规模的企业,也分出了两条路径。手握海量金融数据和应用场景的大型金融机构,可引入业界*的基础大模型,自建企业大模型,同时采用微调形式,形成专业领域的任务大模型,快速赋能业务,以弥补大模型建设周期过长的缺点;而中小金融机构可综合考虑ROI,按需引入各类大模型的公有云API或私有化部署服务,直接满足赋能诉求。
不过,由于金融行业本身对数据合规性、安全性、可信性等存在高要求,部分人士认为,这一行业的大模型落地进展,实际略滞后于年初预期。软通动力孙洪军介绍,他们最初预测金融行业可能会*大规模使用大模型,但从最终对接客户的情况来看,金融行业不如法律、招聘等行业走得快。
一些金融机构已经开始想办法,解决大模型落地过程中的各种“桎梏”。
比如在算力方面,业内人士观察,金融业目前涌现出了几种解决思路:
其一,直接自建算力,成本相对高昂,但好处是安全性足够高。适用于实力雄厚、希望自建行业或企业大模型的金融机构,典型如建行、工行等国有大行。
知情人士告诉数智前线,为了搭建算力,建行在前不久刚下单了一笔H800的算力大单。
其二,算力混合部署,即在敏感数据不出域的情况下,接受从公有云上调用大模型服务接口,同时通过私有化部署的方式处理本地的数据服务。这种方式成本相对较低,只需投入几十万元买上几张卡即可满足需求,适用于资金相对薄弱,只按需进行应用的中小型金融机构。
不过,即便如此,很多中小机构仍然会面临买不到也买不起大模型所需的GPU卡的难题。针对这个问题,上述资深人士向数智前线透露,证监会最近正在进行一些课题研究,探索是否能够以一种折中的方式,牵头搭建一个面向证券行业的大模型基础设施,集中算力、通用大模型等资源,让行业里的中小金融机构也能用上大模型的服务,以防止它们“技术掉队”。
不仅是算力上,随着最近半年多大家对大模型的落地探索,不少金融机构也逐渐加强了对数据的治理。
腾讯云副总裁胡利明介绍,目前除了在数据治理领域有成熟实践的头部大行,越来越多的腰部金融机构也在开始陆续去构建数据中台和数据治理的体系,像今年上半年的北部湾银行、湖南农信等等,都是腰部机构。胡利明认为,构建一个完善的数据治理体系和数据湖技术平台,将会是未来金融机构IT建设非常重要的主旋律。
也有银行正通过大模型+MLOps的方式解决数据问题。比如农业银行,通过采用MLOps模式建立大模型数据闭环体系,实现了整个流程的自动化,以及多源异构数据的统一管理和高效处理,据悉目前已构建和沉淀2.6TB高质量训练数据集。
02
从外围场景切入
过去半年多,不管是大模型的服务商们,还是各大金融机构,大家都在疯狂找场景,智慧办公、智能开发、智慧营销、智能客服、智慧投研、智能风控、需求分析等都被一一探索。
每家金融机构,也都对大模型有着丰富的畅想和构思。建行称内部已有20多个场景投放应用,农行说他们在30多个场景中进行了试点,广发证券则表示,正在探索将大模型和此前推出的虚拟数字人平台打通……
但当要真正将大模型落地进行业里,大家的一个共识是,先内部后外部。毕竟,当前阶段而言,大模型技术并不成熟,比如幻觉问题,而金融行业却是一个强监管、高安全、高可信的行业。
“短期内不建议直接对客使用。”中国工商银行首席技术官吕仲涛认为,金融机构应优先将大模型面向金融文本和金融图像分析理解创作的智力密集型场景,以助手形式,人机协同来提升业务人员工作质效。
胡利明也告诉数智前线,很多金融客户都认为代码助手和客服助手是前期能直接出一些成果的场景。而像投研、投顾等场景,价值很大,但很难快速出来效果,对数据的要求也高。
目前,代码助手已在不少金融机构落地。比如工行,构建了基于大模型的智能研发体系,编码助手生成代码量占总代码量的比值达到40%。又比如在保险领域,阳光保险研发了基于大模型的常青藤辅助编程插件,直接嵌入内部开发工具。
基于此,一部分厂商也在围绕大模型代码生成的能力,直接为金融客户提供开箱即用的产品。软通动力孙洪军介绍,他们的一款产品,就是在大模型本身的代码补全能力上,补充任务分解、精准回答、突破上下文限制等一系列工作,实现用户的开箱即用。目前,该产品在汇丰银行已为3000多人所使用,代码自动补全率为50%~90%。
智慧办公领域,也有不少落地案例。负责华为盘古金融行业大模型产品的祝博士介绍,他们基于盘古金融大模型推出的网点问答,7月在工行上线后,已经陆续推广了几百个网点,答案采纳率超过85%。目前,文档问答孵化成的标准解决方案,又快速复制到交行、农行、银联以及上交所等。
不过,业内人士判断,这些已经广泛落地的场景,实际都还不是金融机构的核心应用,大模型距离深入金融行业的业务层面还有一定距离。
“我们自己判断,在业务应用场景这块儿做的难度还是挺大的。”孙洪军说,营销、风控、合规等场景都是大模型可能带来变革,同时也是金融客户需求点所在的部分,但就目前的情况而言,这些工作,还要取决于底层大模型厂商们的能力提升情况,再去把业务场景做起来。
上述大厂大模型资深人士则向数智前线预测,到今年底之前,会有一批真正在金融机构核心业务场景里,用上大模型的项目建设或招标信息出来。
而在此之前,一些顶层设计层面的改变正在进行。
9月初蚂蚁集团主办的外滩大会上,复旦大学教授、上海市数据科学重点实验室主任肖仰华做出这样一个判断:未来的整个智能化、数字化系统,都将重新建立在大模型的基础之上。这就要求金融行业在推动大模型落地过程中,要重新架构系统。同时,也不能忽视传统小模型的价值,而应该让大模型、小模型协同起来。
这一趋势已在金融行业得到广泛体现。“现在金融机构试点做大模型,基本上会采取分层的模式。”胡利明介绍,不同于过去一个场景需要搭建一个平台的烟囱化模式,大模型其实给了金融机构们一个从零开始,更加科学地去做整体的系统规划的机会。
可以看到,目前已经有多家头部金融机构,都已经基于大模型,搭建了包含基础设施层、模型层、大模型服务层、应用层等多个层级的分层系统框架,如农行、华夏银行、广发证券、阳光保险等。
这些框架体系,普遍有两大突出特点:其一,大模型发挥中枢能力,将传统模型作为技能进行调用;其二,大模型层采用多模型策略,内部赛马,选出*效果。
实际上,不止金融机构,在当前格局未定的情况下,一些大模型应用提供商,也在采用多模型策略,优选服务效果。孙洪军透露,软通动力的底层模型层也融合了大量大语言模型,他们会根据每个大模型返回的回答,组装优选后给到用户。
03 人才缺口依然庞大
大模型的应用,已经开始对金融行业的人员结构带来一些挑战和变革。
此前,上海一家金融科技公司的人士曾告诉数智前线,随着ChatGPT的出现,从今年初到5月底,他所在的公司已经裁掉了300多位大数据分析师。而在几年前,这还是一个炙手可热的职业。这一度引发他的焦虑,甚至开始提前考虑起自己女儿将来的择业问题。
来自工行的金融领域资深人士,也分享了大模型对人的替代效应。工行原来每天早上都会有实习生将各方面的信息归纳汇总,再给到投研部门的人,但现在实习生的这些工作通过大模型即可完成。
不过,一些银行其实并不希望大模型带来减员。比如拥有20万网点员工的工行,就明确向华为提出,他们不希望员工被大模型取代,而应该是大模型带来新的机会,提升员工的服务质量和工作效率,同时也释放出部分员工,做更多高价值的事情。
这其中不乏人员和结构稳定的考量。但另一方面,也是因为行内很多岗位还有人才缺口。
孙洪军告诉数智前线,大行有一堆干不完的活,部分IT需求的工期甚至排到了明年年底,他们的期望是,大模型能助力员工干更多的活,把效率和速度“卷”起来,而不是带来人员的缩减。
更重要的是,大模型的火来得又急又烈,短时间内,稀缺的人才供给难以匹配上激增的需求。这就好比当初iPhone手机刚出来时,大家想做应用,满世界找一个iOS程序员,又贵又难。
9月初的一场金融科技大会上,中国农业银行研发中心副总经理赵焕芳总结了金融行业目前在将大模型能力用到核心业务流程中会遇到的6大挑战,其中之一正是人才。赵焕芳称,他们最近招了一些新员工,同时也在做校招,一问是不是学AI这个领域的,占比非常高,再问大模型,“寥寥无几”。
孙洪军对此同样深有体会,国庆前一周,他们才刚收到过一家银行客户的人才支援请求。这家银行因自行搭建的大模型团队中有一人需暂时请假,模型训练工作一时面临人手不足问题,不得不临时对外寻求支持。
“现在这方面的人才确实很少,还需一定时间来进行培育。”孙洪军认为,直接应用大模型的人才需求相对简单,需要的是会提问题的人。但如果自建行业或企业大模型,则需要金融机构有一支精干得力的垂直大模型技术队伍。
腾讯云副总裁胡利明也坦言,AI大模型这块儿的人才缺口非常之大,头部机构目前都在招一些AI专业相关人才,如算法博士等。这是因为,金融客户虽然能从大模型厂商处获得一定的技术支持,但他们毕竟才是最终的使用方和创新的主导方,需要一定的人才积累,来支撑它整个AI大平台的构建,各项AI应用的规划,以及在整个建模、调优和精调的过程中,和大模型厂商一起去做场景叠加、模型叠加等相关优化,不断去拓展AI模型应用的面和效果。
一些玩家已经采取行动。华为祝博士介绍,他们专门联合工行实验室的人力资源团队,梳理了大模型在企业应用的人员转身实践,设计出系列培训课程,如Prompt调优、微调、大模型运营等,并与远程银行、UX设计、网点等部门合作,建立联合项目组,驱动企业人员能力提升。
“大模型是半生品,离成品还差得很远,必须是领域的人一块努力才能做成成品。”一位业内资深人士总结称,大厂的大模型会对企业现有传统方面的才能带来某种提升,但不会产生范式的改变,范式的改变必须是金融体系内部有一支队伍要深入融合内部需求,做出很大的变量才有可能做出来。
值得一提的是,在这个过程中,金融机构的人员结构也会迎来一些调整和变革。“会用大模型的开发人员,肯定会比不会用的人,更容易在这个环境中留存下来。”孙洪军说。









