

在当下的AI赛道上,AI聊天、绘画一类的应用,早已枝繁叶茂。
然而,在此类同质化应用扎堆的情况下,一类颇有技术难度,也较少被人提及的方向,正在悄然崛起。
这就是最能调动人感官的视频AI领域。
根据twitter上的作者Will 郎瀚威统计的图表,今年8—9月,各大文生图类AI网站的访问量均开始呈现下降趋势。
然而,就在这种情况下,国外知名视频AI网站HeyGen的访问量上升了92%,流量跃居各大独立AI网站之首。
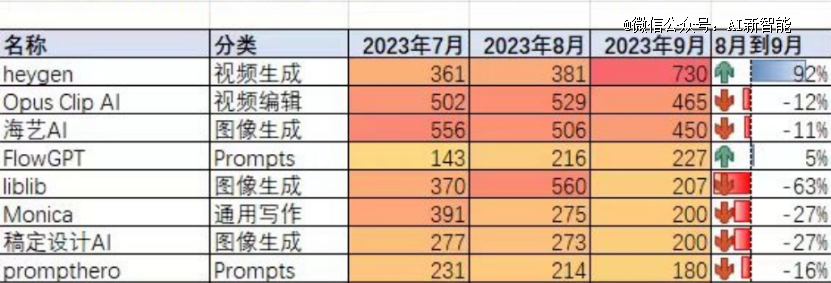
那么,为何此前一直默默无闻的视频AI,最近突然异军突起,盖过了风头正盛的文生图类AI应用?
而在GPT-4V发布,多模态技术不断取得突破的情况下,这一微妙的变化,又预示着什么?
01 多模态的前奏
从AI发展的大格局上来说,HeyGen的这波流量上升,或许只是多模态高歌猛进背景下的一个插曲。
从谷歌宣布Gemini具有多模态功能的消息,到OpenAI发布GPT-4V,各个AI巨头,似乎都将下一阶段竞争的焦点放在了多模态上。
那为何多模态成了巨头眼中关键的“突破点”?
原因或许就在于,其具有打破“专业壁垒”的意义。
在多模态尚未取得突破之前,不同模态、领域之间,存在着巨大的鸿沟。
写文案,做编辑的人,即使再妙笔生花,如果缺乏相应的美术知识,以及各种专业的提示词,也难以用AI画出出色的作品。
而一个画师如果没有受过专业的写作训练,缺乏谋篇布局的思路,也难以凭借AI写出上乘的文章。
类似的“壁垒”,在视频剪辑方面,也同样存在着。
根据知乎上一位视频剪辑方面的从业者介绍,一个完整的视频剪辑流程,包括了调色、整理素材、配字幕等一系列工作,要想熟练地进行剪辑,必须掌握PR、Edius、剪映等多种剪辑软件,同时还需熟悉各种转场、调色、粒子*等插件的使用。
如果想让视频呈现更丰富的效果,还要掌握b-roll转场、字幕遮罩、坡度变速等复杂的操作。
此外,素材的搜集和整理,也是剪辑工作中的一大“苦活”,倘若题材较为冷门,素材就会很不好找。有时尽管遇到了好的素材,也可能由于版权问题难以使用。
正是由于上述原因,视频剪辑,注定不是一个简单的、易于掌握的技能。
以国内知名网站B站为例,据一位B站上百万粉丝的UP主团队透露,为了保证视频更新的效率、质量,这些账号往往会配备数名较为熟练的剪辑人员,轮番进行剪辑。
那么,倘若有一种智能化的AI剪辑应用,能根据创作者想表达的思路,自动、高效地完成整个视频的制作,视频制作领域,又会发生怎样的颠覆呢?
实际上,这样的技术早已出现。
下面这两张图片,分别来自两段不同的视频片段。
你能分辨出哪个是真人,哪个是AI生成的吗?

答案是:这两个视频都是100%由AI生成的人像视频。
而它们均出自此前提到的HeyGen之手。
在HeyGen上,用户只需要用上传一段2分钟的小视频,就能达到和真人一样的效果,即使是像手势、面容和口型这种“细微肢体语言”也能调整。
而这类效果的实现,正是当下多模态技术发力的开端。
02 视频AI之力
如果要论HeyGen与其他同类视频AI应用*的区别,就是它可以利用现有数据来创造全新和从未有过的内容。
以往的类似应用,例如D-ID,虽然也能让用户从照片或者AI形象中生成视频,但是这样的技术,更多是基于复制或处理已有的内容的AI技术。
这些技术虽然也可以制作视频,但是需要用户提供自己的照片或录音,或者从D-ID提供的一些固定的AI形象中选择。这样就需要用户花费更多的时间和精力来准备和上传素材,也限制了用户的选择和定制空间。
而相较之下,HeyGen的技术则可以让用户从文本中直接生成视频,并使用多种不同的AI形象和声音。
除了HeyGen之外,在视频AI领域,许多正在蓄势待发的类似应用,也已经在悄然崛起。
例如能直接将脚本转化成视频的Pictory.AI就是其中之一。
Pictory 允许用户仅通过几次点击,就能将脚本转化为配有逼真的AI语音、匹配的素材和音乐的专业质量视频。
具体来说,在制作视频时,用户可以从Pictory 提供的多种模板中选择一种,来设置视频的样式。
之后,Pictory 会根据用户输入的文本和选择的模板和比例,自动地生成一个故事板。故事板是一个由多个场景组成的视频序列,每个场景包含了文字、图片、AI语音和一段音乐。
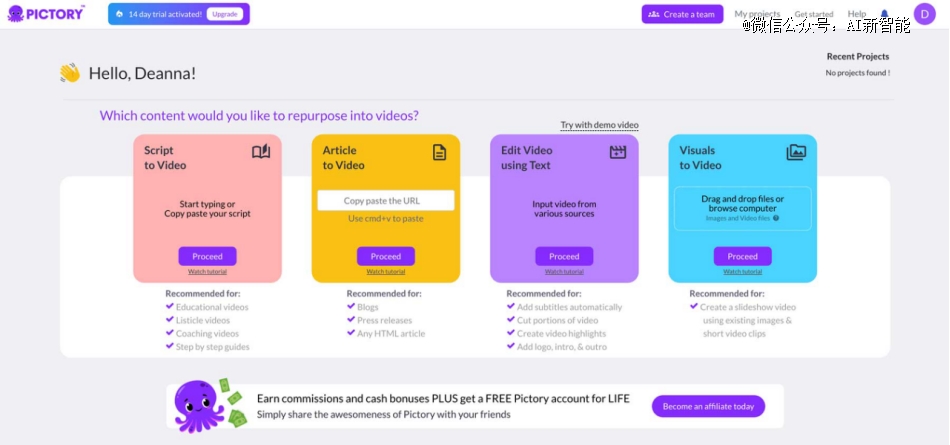
最后,用户可以在故事板上预览视频的效果,并进行一些编辑和调整。
如此一来,团队不需要昂贵的摄影师、剪辑师,也能制作出专业的、高质量的视频。
同样地,用3D CGI角色替换真人演员的Wonder Studio,也是旨在提高视频制作效率的AI应用之一。
Wonder Studio 是一个基于网页的视频平台,它可以让用户轻松地将任意的计算机生成的角色(CGI character)添加到任何场景中,使用AI技术来实现无缝的融合。
用户只需要拍摄自己想要的场景,并上传到网站上,Wonder Studio 的AI引擎就会自动分析场景中的演员的表演,包括他们的动作和面部表情,并将这些信息转换成运动数据,然后用这些数据来驱动用户选择的CGI角色。
这样,用户就可以*地用3D CGI角色替换真人演员,无需使用复杂的3D软件或者昂贵的制作设备,例如动作捕捉服。
03 趋势及国内现状
从以上视频AI的技术特点中,我们至少可以总结出目前视频AI技术的两大趋势:
1、制作流程极大简化
利用生成式AI技术,人们能够以自动化、智能化的方式,将文本、图像、音频、视频等多模态数据重新组合,来创造全新和从未有过的内容,在降低成本的同时,也打破了各个模态(或专业)之间的“技术壁垒”。
而这一壁垒的打破,正是生成式AI走向通用化、普及化的关键。

2、内容的多样性和定制性
利用多模态AI的技术,人们能够处理和关联多种信息模态,从而在内容创作过程中,更好地表达自己的个性和风格,并适应不同的场合和目的。
这是以往受限于已有素材的单一模态技术难以实现的。
在上述两大趋势中,目前国内的视频AI应用,只勉强做到了“简化”这一步。
虽然国内目前也有一些与HeyGen类似的AI视频应用,例如腾讯智影、一帧秒创、万彩微影等。这些应用也利用了AI技术来简化视频创作过程,并提供了文本配音、文章转视频、数字人播报等功能。
然而,在具体的生成效果方面,国内应用的视频清晰度、素材丰富度,以及定制化功能方面,仍与HeyGen等应用有着较大差距。
从总体上来说,这类应用仍旧只能在平台提供的素材库内,选择有限的元素进行创作,并且在某些类别(如数字人视频)上,国产应用生成的视频,也未达到HeyGen视频那样流畅、逼真的标准。
如果说,在本轮AI革命中,国内视频AI技术仅仅止步于“降本”这一环节,从长远来看,是远远不足以征服智能化时代的观众的。
从当下观众的态度来看,AI制作的视频仍处于一种“不受待见”的状态,很多观众仍然觉得,在视频中使用AI技术,是一种偷懒、不负责,且廉价的制作方式。
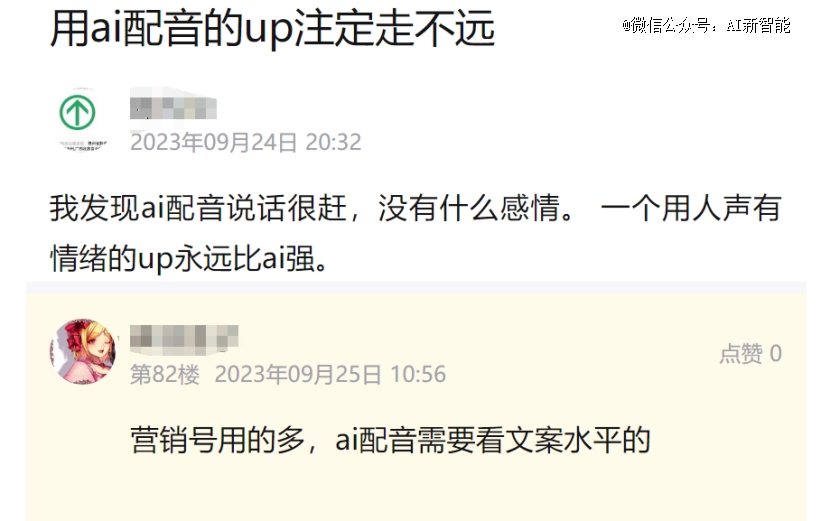
究其原因,是因为当下国内的部分AI技术,仍未突破一种感官上的阈值,仍然让人明显觉察到“这不是人做的”。
于是就给人造成了一种“没有感情”、“粗制滥造”的印象。
更有甚者,甚至将那些使用了AI技术的视频,打上了“营销号”的标签。
面对这样的环境,任何珍惜自己羽毛的视频创作者,都不敢轻易使用AI技术了,因为生怕被人当成“营销号”,扣上“粗制滥造”的帽子。
生成式AI的进步,确实极大简化了视频制作的流程,但在已经到来的智能时代,观众们已经不想再看到那些批量的、流水线式的“低劣”视频了。
而要想摘掉这样的“低劣”标签,真正地让作品具有感情和灵魂,除了一个劲儿地“降本”之外,在个性化、拟真度,以及素材丰富性方面,国产视频AI还有很长的路要走。











