

近段时间以来,以ChatGPT为首的生成式AI席卷全球,技术升级带来的生产力巨大提升,也正在对各个产业带来革命性改变,甚至产业逻辑也需要被重估。
而AI浪潮背后的“卖铲人”,英伟达一举迈入了万亿美元市值俱乐部。
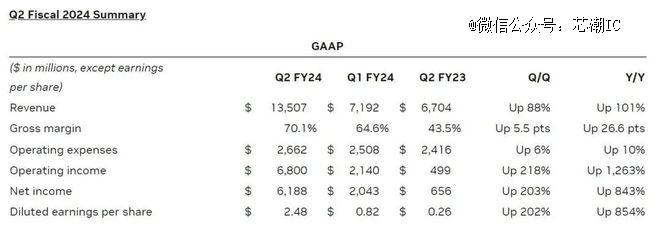
英伟达最近一个财季的业绩数据同样令人吃惊。财报数据显示,英伟达第二财季收入为135.07亿美元,创下纪录新高,这使分析师给出的110.4亿美元预期显得极为保守。
英伟达2023财年Q2营收数据
整体来看,英伟达的业务规模基本达到去年同期的两倍,这几乎完全要归功于市场对其AI芯片的旺盛需求,无论是初创企业,还是打造生成式AI服务的科技巨头们都在疯狂抢购这些AI芯片。
市场研究公司Omdia近日发布报告称,预计英伟达二季度用于AI和高性能计算应用的H100 GPU的出货量超过了900吨。并且预计其在未来几个季度的GPU销量将大致相同,因此英伟达今年将销售约3600 吨重的H100 GPU。
并且还不止这些,还有H800,以及上一代的A100、A800等GPU产品。因此,可以预计,随着英伟达从生成式AI热潮中获利,未来一年的出货量将会加快。
据行业内部消息透露,2023年英伟达H100的产量早已销售一空,现在交钱订购,至少要到2024年中才能拿到货。
谁将获得多少A100、H100 GPU,以及何时获得,都是硅谷当前最热门的话题。
英伟达*的客户们似乎也认可这一点。微软、亚马逊、谷歌和Meta等国际巨头最近发布截至6月的财季的财报时都暗示,它们有强烈意向继续在生成式AI能力上投入资金,尽管在其他领域的资本投资放缓。
AI教父Sam Altman就曾自曝,GPU已经告急,希望用ChatGPT的用户能少一点。Sam表示,受GPU限制,OpenAI已经推迟了多项短期计划。
据消息人士透露,中国的科技巨头百度、腾讯、阿里巴巴以及字节跳动公司今年向英伟达下达的交付订单金额已超过10亿美元,总共采购约10万张A800和H800芯片;明年交付的AI芯片价值更是达到40亿美元。
不光是科技公司在排队购买H100,沙特阿拉伯、阿联酋等中东国家也势头强劲,一次性就买了几千块H100 GPU。其中,阿联酋阿布扎比技术创新研究所开发的“猎鹰40B”模型是近期开源社区中炙手可热的商用大模型,反映阿联酋在增强基础算力方面不遗余力。
在一篇业内热转的《Nvidia H100 GPU:供需》文章中,作者也深度剖析了当前科技公司们对GPU的使用情况和需求。文章推测,小型和大型云提供商的大规模H100集群容量即将耗尽,H100的需求趋势至少会持续到2024年底。
正如英伟达CEO黄仁勋说:“我们目前的出货量远远不能满足需求。”
英伟达GPU芯片不光不愁卖,利润率还高得吓人。业内专家曾表示,英伟达H100的利润率接近1000%。消息公布后,迅速引发了芯片战场上的热议。
美国金融机构Raymond James在近期的一份报告中透露,H100芯片成本仅约3320美元,但英伟达对其客户的批量价格仍然高达2.5万-3万美元,高达1000%的利润率导致H100几乎成为了有史以来“*钱”的一款芯片。
这一点从季度财报中也能得到充分印证,英伟达Q2财季净利润高达61.8亿美元,同比上升843%。据悉,英伟达最近一个财季的调整后营业利润率达到了58%,这是至少十年来的最高水平,并且较其之前八个财季平均39%的营业利润率有大幅跃升。
英伟达井喷式的业绩增长和长期展望表明,AI需求并非昙花一现。巨大的市场空间,以及超乎想象的前景,吸引诸多厂商参与其中,将进一步刺激行业竞争。
在此趋势下,AI芯片的战役正愈演愈烈。
AMD、Intel、IBM等科技巨头以及新晋企业正陆续推出新的AI芯片,试图与英伟达AI芯片抗衡;谷歌、微软、亚马逊、阿里、百度等公司也纷纷布局自研芯片,以减少对外部供应商的依赖。
AMD:GPU市场的“二号玩家”
当前的AI芯片市场可以说是英伟达的天下,每一位挑战者想要动摇其根基都并非易事。AMD作为英伟达的老对手,自然不会放任其独揽如此庞大且增速超快的市场。
对于这位GPU市场的“二号玩家”,大家都期待其能拿出撼动英伟达“算力霸主”地位的“*武器”。
今年6月,备受业界瞩目的AMD发布了Instinct MI300系列产品。Instinct MI300系列产品主要包括MI300A、MI300X两个版本,以及集合了8个MI300X的Instinct Platform。
针对MI300A,AMD CEO苏姿丰声称,这是全球*为AI和HPC打造的APU加速卡,采用了“CPU+GPU+内存”的一体化组合形式,拥有13个小芯片,总共包含1460亿个晶体管,24个Zen 4 CPU核心,1个CDNA 3图形引擎和128GB HBM3内存。

Instinct MI300X是一款直接对标英伟达H100芯片,专门面向生成式AI推出的加速器。该产品采用了8个GPU Chiplet加4个I/O内存Chiplet的设计,总共12个5nm Chiplet封装在一起,使其集成的晶体管数量达到了1530亿,高于英伟达H100的800亿晶体管,是AMD投产以来*的芯片,可以加速ChatGPT等大模型应用。
与英伟达的H100芯片相比,AMD Instinct MI 300X的HBM密度是前者的2.4倍,带宽则为前者的1.6倍,理论上可以运行比H100更大的模型。
此外,AMD还发布了“AMD Instinct Platform”,集合了8个MI300X,可提供总计1.5TB的HBM3内存。
苏姿丰表示,随着模型参数规模越来越大,就需要更多的GPU来运行。而随着AMD芯片内存的增加,开发人员将不再需要那么多数量的GPU,能够为用户节省成本。此外,她还透露,MI300X将于今年第三季度向一些客户提供样品,并于第四季度量产。
那么,性能优异的MI300X能否与H100一较高下呢?
有业内专家表示,虽然本次AMD的MI300X采用了更大的192GB HBM3,但英伟达的产品也在迭代,等未来MI300X正式发售时,英伟达可能已经推出了参数更强的产品。而且由于AMD未公布新品价格,采用192GB HBM3的MI300X成本可能与H100相比可能不会有显著的价格优势。
其次,MI300X没有H100所拥有的用于加速Transformer大模型的引擎,这也意味着用同样数量的MI300X将花费更长的训练时间。当前,用于AI训练的GPU供不应求,价格水涨船高,MI300X的推出无疑将利于市场的良性竞争,但短期来看,AMD的MI300X可能更多是作为客户买不到H100的“替代品”。
至顶智库首席分析也表示,尽管从AMD本次公开的性能参数来看,MI300X在很多方面都优于英伟达的H100,但并不是性能越高,就越多人用,这不是一个正向关系。英伟达深耕GPU领域多年,所拥有的市场认可度和产品稳定性都是AMD所不具备的。另外在软件生态的建立和开发方面,英伟达的CUDA经过十几年积累已构建其他竞争对手短时间难以逾越的护城河。
虽然AMD目前也已经拥有了一套完整的库和工具ROCm,也能完全兼容CUDA,为AMD提供了说服客户迁移的条件和理由,但兼容只属权宜之计,只有进一步完善自己的生态才能形成竞争优势。未来,ROCm需支持更多的操作系统,在AI领域开拓更广泛的框架,以此吸引更多的开发者,相较于硬件参数,软件方面的门槛和壁垒更高,AMD需要较长的时间来完善。
Cambrian-AI Research LLC首席分析师Karl Freund在《福布斯》杂志的最新报道中也指出,与英伟达的H100相比,MI300X面临着一些挑战。
一方面,英伟达H100已满载出货,而MI300X尚处于“襁褓之中”;其次,在AI产业里,英伟达具有*的软件生态系统和最多的研究人员,而AMD的软件生态没有那么完善。并且,AMD还未公开任何基准测试,而训练和运行AI大模型不仅仅取决于GPU性能,系统设计也尤为重要。
至于MI300X在内存上的优势,Karl Freund认为,英伟达也将提供具备相同内存规格的产品,因此这不会成为*优势。
综合来看,AMD想要撼动如日中天的英伟达,并非易事。
不过,不可否认的是,虽然短期内英伟达的“AI王座”难以撼动,但MI300X依旧是英伟达H100的有力竞争者,MI300X将成为除了英伟达H100以外的“第二选择”。
从长远来看,对于英伟达而言,AMD也是值得警惕的竞争对手。
Intel:争夺AI算力市场宝座
众所周知,目前GPU资源紧缺,英伟达的100系列在国内禁售,而百模大战之下算力的需求还在飙升。对于中国市场而言,当前急需AI芯片“解渴”,对于英特尔而言,眼下正值算力紧缺的窗口期,也是进攻的*时机。
今年7月,英特尔面向中国市场推出了AI芯片Habana Gaudi 2,直接对标英伟达GPU的100系列,欲争夺AI算力市场的宝座。
在发布会现场,英特尔直接将Gaudi 2和英伟达的A100进行比较,其野心可见一斑。根据英特尔公布的数据,Gaudi 2芯片是专为训练大语言模型而构建,采用7nm制程,有24个张量处理器核心。从计算机视觉模型训练到1760亿参数的BLOOMZ推理,Gaudi 2每瓦性能约A100的2倍,模型训练和部署的功耗降低约一半。
英特尔执行副总裁、数据中心与人工智能事业部总经理Sandra Rivera表示,在性能上,根据机器学习与人工智能开放产业联盟ML Commons在6月底公布的AI性能基准测试MLPerf Training 3.0结果显示,Gaudi 2是除了英伟达产品外,*能把MLPerf GPT 3.0模型跑起来的芯片。
随着大模型的日新月异,英特尔在近几个月内围绕着Gaudi 2继续进行优化。
据介绍,相比A100,Gaudi 2价格更有竞争力,且性能更高。接下来采用FP8软件的Gaudi 2预计能够提供比H100更高的性价比。
事实上,去年英特尔就已经在海外发布了Gaudi 2,此次在中国推出的是“中国*版”。
英特尔强调,目前在中国市场上,英特尔已经和浪潮信息、新华三、超聚变等国内主要的服务器厂商合作。Sandra Rivera表示:“中国市场对人工智能解决方案的需求非常强劲,我们正在与几乎所有传统客户洽谈。云服务提供商、通信服务提供商都是企业客户,因此对人工智能解决方案有着强烈的需求。”
另一方面,在产品路线上,英特尔近年一直强调XPU,即多样化、多组合的异构计算。在AI相关的产品线上,既有集成AI加速器的CPU处理器、有GPU产品,以及Habana Gaudi系列代表的ASIC类型AI芯片。
大模型的火热还在持续拉动AI芯片的需求。
据了解,英特尔的Gaudi 2处理器自7月份推出以来销量一直强劲,英特尔首席财务官David Zinsner在早些时候的一次会议上表示,已经看到越来越多的客户寻求其Gaudi芯片作为供应短缺的处理器的替代品。
Gaudi是一个人工智能加速的专属产品。在英特尔产品里,Gaudi是针对大模型工作负载中性能*、*的一个产品。据Sandra Rivera表示:“明年我们还会有下一代产品Gaudi 3发布。在2025年的时候,我们会把Gaudi的AI芯片跟GPU路线图合二为一,推出一个更整合的GPU的产品。”
日前,英特尔在旧金山举行的“Intel Innovation”盛会上透露,下一代使用5nm工艺打造的Gaudi 3将在性能方面大幅提升。其中,BF16下的性能提升了四倍、计算能力提升了2倍、网络带宽的1.5倍以及HBM容量的提升1.5倍。
展望未来,在Gaudi 3之后, 英特尔计划推出一个代号为Falcon Shores 的继任者。
关于Falcon Shores,英特尔没有披露太多细节。但按照其最初规划,英特尔会于2024 年推出Falcon Shores芯片、原计划为“XPU”设计,即集成CPU和GPU。但在上个月的财报会上,英特尔调整了Falcon Shores的计划,并随后将其重新定位为独立GPU,并将于2025年发布。
整体来看,Gaudi系列作为英特尔AI的一艘旗舰,外界也拭目以待Gaudi 2在实际应用中的性能表现和算力实力。从硬件迭代到软件生态,AI芯片的竞争故事还将继续。
IBM:模拟AI芯片,引领行业趋势
人工智能的未来需要能源效率方面的新创新,从模型的设计方式到运行模型的硬件。
IBM最近公布了一款新的模拟AI芯片,据称其能效比当前业界*的英伟达H100高出14倍,这款新芯片旨在解决生成式人工智能的主要问题之一:高能耗。这意味着在相同的能量消耗下,它能够完成更多的计算任务。
这对于大型模型的运行来说尤为重要,因为这些大型模型通常需要更多的能量来运行。IBM的这款新芯片有望缓解生成式AI平台企业的压力,并可能在未来取代英伟达成为生成式AI平台的主导力量。
这是由于模拟芯片的构建方式造成的。这些组件与数字芯片的不同之处在于,数字芯片可以操纵模拟信号并理解0和1之间的灰度。数字芯片在当今时代应用最广泛,但它们只能处理不同的二进制信号,在功能、信号处理和应用领域也存在差异。
IBM声称其14nm模拟AI芯片每个组件可以编码3500万个相变存储设备,可以建模多达1700万个参数。同时,该芯片模仿了人脑的运作方式,微芯片直接在内存中执行计算,适用于节能语音识别和转录。
IBM在多个实验中展示了使用这种芯片的优点,其中一个系统能够以非常接近数字硬件设置的准确度转录人们说话的音频。此外,语音识别速度也得到了显著提升,提高了7倍。这对于许多需要实时响应的应用场景,如语音助手和智能音箱等,将带来更加顺畅的用户体验。
IBM这款模拟AI芯片的发布,标志着模拟芯片成为人工智能领域的新趋势。通过集成大量的相变存储单元,该芯片能够实现更高效的计算和能效。随着技术的不断发展,预计未来模拟芯片有望成为人工智能领域的新趋势,成为推动人工智能技术发展的核心驱动力。
总之,IBM的新型模拟AI芯片有望为生成式AI领域带来重大突破。英伟达GPU芯片是为当今许多生成式AI平台提供动力的组件。如果IBM迭代该原型并为大众市场做好准备,它很可能有一天会取代英伟达的芯片成为当前的中流砥柱。
SambaNova:新型AI芯片,挑战英伟达
高端GPU持续缺货之下,一家要挑战英伟达的芯片初创公司成为行业热议焦点。
这家独角兽企业SambaNova刚发布的新型AI芯片SN40L,该芯片由台积电5nm工艺制造,包含1020亿晶体管,峰值速度638TeraFLOPS,高达1.5T的内存,支持25.6万个token的序列长度。
与主要竞品相比,英伟达H100最高拥有80GB HBM3内存,AMD MI300拥有192GB HBM3内存。SN40L的高带宽HBM3内存实际比前两者小,更多依靠大容量DRAM。
SambaNova CEO Rodrigo Liang表示,虽然DRAM速度更慢,但专用的软件编译器可以智能地分配三个内存层之间的负载,还允许编译器将8个芯片视为单个系统。
除了硬件指标,SN40L针对大模型做的优化还有同时提供密集和稀疏计算加速。
Gartner分析师认为,SN40L的一个可能优势在于多模态AI。GPU的架构非常严格,面对图像、视频、文本等多样数据时可能不够灵活,而SambaNova可以调整硬件来满足工作负载的要求。
相比其他芯片供应商,SambaNova业务模式也比较特别,芯片不单卖,而是出售其定制技术堆栈,从芯片到服务器系统,甚至包括部署大模型。
Rodrigo Liang指出,当前行业标准做法下运行万亿参数大模型需要数百枚芯片,我们的方法使总拥有成本只有标准方法的1/25。
根据Rodrigo Liang的说法,8个SN40L组成的集群总共可处理5万亿参数,相当于70个700亿参数大模型。全球2000强的企业只需购买两个这样的8芯片集群,就能满足所有大模型需求。
目前,SambaNova的芯片和系统已获得不少大型客户,包括世界排名前列的超算实验室,日本富岳、美国阿贡国家实验室、劳伦斯国家实验室,以及咨询公司埃森哲等。
云服务商自研AI芯片,摆脱英伟达
当下,英伟达还是当之无愧的“AI算力*”,A100、H100系列芯片占据金字塔*位置,是ChatGPT这样的大型语言模型背后的动力来源。
然而,不管是为了降低成本,还是减少对英伟达的依赖、提高议价能力,包括谷歌、亚马逊、微软、特斯拉、Meta、百度、阿里等在内的科技巨头们也都纷纷下场自研AI芯片。
以微软、谷歌、亚马逊三巨头为例来看,据不完全统计,这3家公司已经推出或计划发布了8款服务器和AI芯片。
在这场AI芯片竞赛中,亚马逊似乎占据了先机,已拥有两款AI专用芯片——训练芯片Trainium和推理芯片Inferentia。2023年初,专为人工智能打造的Inferentia 2发布,将计算性能提高了三倍,加速器总内存提高了四分之一,吞吐量提高了四分之一,延迟提高了十分之一。Inf2实例最多可支持1750亿个参数,这使其成为大规模模型推理的有力竞争者。
而早在2013年,谷歌就已秘密研发一款专注于AI机器学习算法的芯片,并将其用在内部的云计算数据中心中,以取代英伟达的GPU。2016年5月,这款自研芯片公诸于世,即TPU。
2020年,谷歌实际上已在其数据中心部署了人工智能芯片TPU v4。不过直到今年4月4日,谷歌才首次公开了技术细节:相比TPU v3,TPU v4性能提升2.1倍。基于TPU v4的超级计算机拥有4096块芯片,整体速度提高了约10倍。谷歌称,对于类似大小的系统,谷歌能做到比Graphcore IPU Bow快4.3-4.5倍,比英伟达A100快1.2-1.7倍,功耗低1.3-1.9倍。
目前,谷歌已将负责AI芯片的工程团队转移到了谷歌云,旨在提高谷歌云出售AI芯片给租用其服务器的公司的能力,从而与更大的竞争对手微软和亚马逊云科技相抗衡。虽然英伟达提供的GPU算力优势在前,但引爆本次AI的两位“大拿”OpenAI、Midjourney的算力系统采购的并非英伟达的GPU,而是用了谷歌的方案。
相比之下,微软在更大程度上依赖于英伟达、AMD和英特尔等芯片制造商的现成或定制硬件。
不过,据The Information报道,微软也正在计划推出自己的人工智能芯片。
了解该项目的知情人士称,微软早在2019年就开始在内部开发代号为“雅典娜”的芯片,这些芯片已经提供给一小批微软和OpenAI员工,他们已经在测试这项技术。微软希望这款芯片的性能比其斥资数亿美元从其他供应商侧购置的芯片性能更优,这样就可以为价值高昂的人工智能工作节省成本。
据悉,这些芯片是为训练大语言模型等软件而设计,同时可支持推理,能为ChatGPT背后的所有AI软件提供动力。另据一位知情人士透露,微软的AI芯片规划中囊括了雅典娜芯片的未来几代产品,最初的雅典娜芯片都将基于5nm工艺生产,可能在明年进入大规模生产阶段。
今年5月,微软还发布了一系列芯片相关招聘信息,正在为AISoC(人工智能芯片及解决方案)团队寻找一名首席设计工程师。据称,该团队正在研究“能够以极其高效的方式执行复杂和高性能功能的尖端人工智能设计”。换句话说,微软某种程度上已把自己的未来寄托在人工智能开发机构OpenAI的一系列技术上,想要制造出比现成的GPU和相关加速器更高效的芯片来运行这些模型。
与此同时,Meta公司披露其正在构建*专门用于运行AI模型的定制芯片——MTIA芯片,使用名为RISC-V的开源芯片架构,预计于2025年问世。
另一边,随着美国对高性能芯片出口限制措施不断加强,英伟达A100、H100被限售,A800、H800严重缺货,国产AI芯片肩负起填补市场空缺的重要使命。
目前,包括华为、阿里、百度昆仑芯、壁仞科技、寒武纪、天数智芯、瀚博半导体等也在GPU赛道发力,取得一定成绩。不过需要重视的是,尽管国产GPU在价格方面有一定优势,但在算力和生态方面,仍然与英伟达存在差距。
整体来看,当英伟达的一些主要客户开始自己开发AI芯片,无疑会让英伟达面临更为激烈的竞争。
根据TrendForce集邦咨询数据显示,目前主要由搭载英伟达 A100、H100、AMD MI300,以及大型CSP业者如Google、AWS等自主研发ASIC的AI服务器成长需求较为强劲,2023年AI服务器出货量出货量预估近120万台,年增率近38%,AI芯片出货量同步看涨,可望成长突破五成。
在市场的巨大需求下,上述一众厂商的谋划明显是奔着跟英伟达抢生意而来。而面对行业“围剿”的同时,摩根士丹利分析师也给英伟达贴上了“泡沫”的标签。
很多人或许认为,英伟达借力AI热潮过得风生水起是个新现象,但实际上这酝酿已久。英伟达在ChatGPT面世十年前就定下了AI战略,据标普全球市场财智汇编的记录,英伟达早在2006年就开始向投资者宣传旗下为AI开发人员所用的CUDA编程语言。
英伟达的AI战略具有长期性和前瞻性,只是如今随着AI技术的崛起,那颗在十几年前射出的子弹,在今天击中英伟达眉心。
当然,在市场中众多企业的追赶下,英伟达也并没有停下自己的脚步。今年8月,在洛杉矶的SIGGRAPH大会上,英伟达拿出了最新一代依托于搭载*HBM3e处理器的GH200 Grace Hopper超级芯片平台,证明这股AI热并非摇摇欲坠的空中楼阁。
与当前一代产品相比,最新版本的GH200超级芯片内存容量增加了3.5倍,带宽增加了3倍;相比最热门的H100芯片,其内存增加1.7倍,传输频宽增加1.5倍。
可见,除了现有A100、H100等热门产品出货持续维持增长以外,英伟达也在持续发布多项用于AI和数据中心的新产品,以进一步巩固自身在AI领域的话语权和统治力。
虽然随着时间的推移,英伟达可能会面临比现在更激烈的竞争。
但从当前进程来看,英伟达和黄仁勋让算力=GPU=英伟达的“理念”植入人心,而这么广阔的市场,竟然真的几乎只有英伟达一家公司一家独大,英伟达的业绩一路狂飙、英伟达在芯片领域的统治力,目前尚看不到尽头。
虽然这种狂飙不太可能永远持续下去,但英伟达给出的信号强烈暗示,其进程远未结束,AI狂飙才刚开始。








