

六月下旬,2023年的国际计算机架构会议(International Symposium on Computer Architecture,ISCA)在美国佛罗里达的奥兰多举办。ISCA是全球最*的计算机架构会议,许多经典处理器芯片的架构研究都是在这个会议上发布,而每年ISCA上发表的论文也是未来几年内计算芯片的重要风向标。今年恰逢ISCA五十周年纪念,全球最*的计算机架构领域学者也在上周发表了一篇回顾过去ISCA五十年发表论文走向的论文《Fifty Years of ISCA: A data-driven retrospective on key trends》(我们翻译如下),我们希望能接着这篇论文来洞察未来计算芯片的走向。
1、芯片工艺决定了未来计算芯片架构
论文《Fifty Years of ISCA: A data-driven retrospective on key trends》中,总结了ISCA举办至今五十年内,每个十年发表论文的共性主题。事实上,如果我们把这些主题的变化和半导体芯片工艺的变化结合起来的话,可以看到一个非常清晰的脉络:
首先,1973年到1992年的ISCA举办前二十年是单处理器性能突飞猛进的二十年,而对应半导体工艺则是Dennard Scaling规律占主导的二十年。在半导体领域中,“每18个月晶体管集成度翻倍”的摩尔定律广为人知,但是半导体工艺演进的过程中,除了晶体管之外,还牵扯到了电源电压和晶体管的时钟频率。Dennard Scaling就是摩尔定律在这二十年中的表现形式,即每18个月晶体管集成度翻倍(如摩尔定律所描述的),同时电源电压降低30%,时钟频率升高40%。因此,根据Dennard Scaling,每18个月芯片除了集成度翻倍之外,芯片的性能还会提高40%,而且芯片整体功耗不会发生变化。换句话说,在Dennard Scaling的时代,单芯片性能随着工艺节点变化突飞猛进,同时不用担心功耗过大。
这样的时代对应到处理器架构,就是如何把单核处理器的性能做到*,如何能把处理器的时钟频率尽可能提升,并且在一个时钟周期内做尽可能多的事情。ISCA上研究的重点方向就包括并行处理(例如流水线,超标量架构,分支预测,超长指令字等等),以及如何确保处理器不被速度较慢的主存所拖累(因此诞生了缓存架构的经典研究),这一点在1993年ISCA发表论文的关键字云中可以看到。
第二个时代是1993年到2012年,在这个时代中,半导体工艺继续维持摩尔定律,即芯片集成度持续指数级上升,但是Dennard Scaling在进入21世纪后逐渐到了尾声,就是说芯片在集成度翻倍是无法的同时,性能虽然提升但是不会有1.4倍这么多,电源电压虽然下降但是芯片的功耗密度不再维持不变而是会上升。对应到处理器架构,就意味着无论是从晶体管性能还是功耗的角度,继续把单核性能提升都不再是一个可持续的提升整体计算机性能的模式了,也就是在这20年,多处理器相关的研究得到了广泛重视,处理器芯片也从单核走向了多核时代。
第三个时代是2013年到今天。在这个时代,摩尔定律的发展受到了严重的挑战,虽然晶体管集成度还在上升,但是单晶体管性能的提升已经非常有限。而另一方面,各种层出不穷的新应用,尤其是人工智能应用,对于处理器芯片的性能提升却提出了非常高的要求。在这个时代,专用加速器(accelertor)已经取代了通用处理器(processor)成为了最热门的关键词——因为通用处理器的性能提升已经不足以满足新应用的需求,只有根据应用量身定做,并且使用算法-架构协同设计的专用加速器才能满足应用对于算力的需求。
2、未来将是计算芯片架构设计的黄金时代
展望未来,我们认为未来十年将是计算芯片架构领域的黄金十年,我们会看到大量有影响力巨大的研究出现,对于算法和应用产生深远的影响;另一方面,随着新应用和需求的出现,相关的加速器研究也会慢慢变得主流,因此计算芯片架构的研究覆盖面将进一步拓宽。
从计算芯片架构的影响力来看,我们已经从人工智能领域看到专用加速器的架构研究和演进对于整个科技行业乃至于人类社会带来的深远影响。从2015年开始,随着以神经网络为主流算法的人工智能成为主流,相关的加速器架构在几年内也发生了深刻而且意义巨大的改变。这些新的架构设计往往是结合了算法的相关特性,同时又助推了新一代人工智能算法的诞生。这里我们谨举几个例子:首先是谷歌的TPU架构设计,2017年的*代TPU架构设计考虑了当时*的卷积神经网络,使用了脉动阵列做计算并且搭配了大量片上SRAM,一举成为了一个经典设计,同时相关论文也是ISCA五十年内引用第二数量第二高的论文;后面几代的TPU则在大规模可扩展性等方面做了巨大的努力(例如专门研发了光学电路来实现超高性能数据互联),而最终这些架构上的新颖研究让TPU成为谷歌在人工智能领域最强的核心能力之一。另外一个例子则是Nvidia从2015年开始为人工智能设计的GPU架构演进;随着人工智能算法的发展,Nvidia在几代GPU中加入了大量和人工智能算法结合的架构要素,包括对于低精度计算(FP16,INT8)的支持,对于稀疏矩阵计算加速的支持,以及对于Transformer模块的专用支持等。这些架构上的改变,每一个都大大提升了GPU对于相关算法性能的提升,而Nvidia能一直占据人工智能加速领域的龙头地位,靠的不仅仅是每一代GPU都能使用*进的半导体工艺,而且是靠这些先进的架构设计,以及软件生态领域的护城河。
从另一个角度来看,这些计算架构领域的演进,已经对于我们的整体社会带来了深远的影响。例如,最近已经对于各大行业的生产模式带来深远影响的ChatGPT,其背后的大语言模型需要海量的算力支持才能在合理的时间内完成计算,而这些都离不开过去十年中人工智能加速器芯片架构领域的研究,可以说每一个研究都在为今天ChatGPT的成功添砖加瓦。而随着这类下一代人工智能给社会带来全新的变革,相关的人工智能加速器架构领域也会得到整个社会前所未有的关注,因此计算芯片架构的未来十年可谓是黄金十年。
除了重点领域的纵向影响力巨大之外,加速器芯片架构领域横向发展也会很快,这里的横向主要是指会有新的应用对于新的专用加速器芯片有需求。从最近几年的ISCA(以及其他的相关芯片会议例如ISSCC)来看,已经有一些新的加速器领域正在蓬勃发展,包括:
加密计算,尤其是同态加密(homomorphic)计算,该领域可以云端服务器在不解密用户数据的前提下,就完成相关的计算(例如把加密的用户数据直接送到机器学习模型里做计算)。我们知道,人工智能对于数据的需求是前所未有的,而加密计算技术有可能在保护用户隐私的前提下同时给人工智能算法提供高质量的数据,从而成为人工智能的关键赋能技术之一。加密计算对于算力需求很高,相关的加速器研究也得到了非常多的关注,2022年ISCA引用数量最多的两篇论文都是关于加密计算加速器架构,其潜力可见一斑。
量子计算,在物理、化学以及规划领域,相关算法都是NP-Hard问题,即经典算法无法在合理的时间范围内得到*解,而量子计算则可以解决相关的问题。因此,最近量子计算,或者使用量子计算相关算法的计算芯片架构研究也是加速器最有潜力的新领域之一。
仿生计算,目前人工智能神经网络计算的功耗非常惊人,相对而言人类大脑的功耗比起执行人工智能计算的硬件来说要低几个数量级,因此如何使用neuromorphic等仿生计算来降低计算功耗,并且通过模仿生物大脑的计算模式来启迪下一代人工智能算法也是一个非常有潜力的方向。
3、未来计算芯片架构设计需要系统级思维
半导体工艺摩尔定律正在接近尾声,但是芯片性能和能效比的指数发展规律仍然如火如荼,尤其是在热门的专用加速器领域——例如GPU计算的能效比就是每2.2年改善两倍。
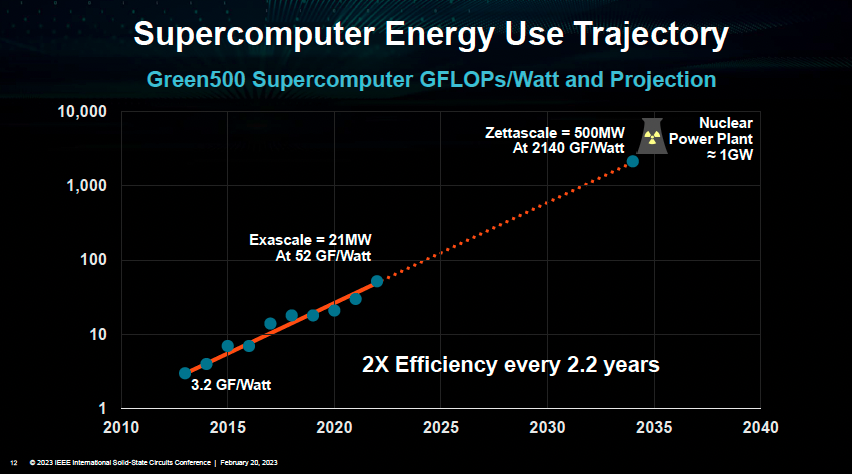
如前所述,为了维持这样的指数级性能上升,专用加速器的一个核心要点是与上层算法协同优化,从而可以产生巨大的推动力:目前人工智能模xin型里面最常用的Transformer模块就是一个典型例子,Transformer在诞生之初就比较适合在GPU上做运算因为其计算主要是矩阵计算,另一方面Nvidia在设计GPU架构时又加入了对于Transformer的优化,最终使得以Transformer为底层模块的大语言模型能够顺利实现大规模训练,并且点燃下一代人工智能。
下一代芯片架构设计除了需要和上层算法打通之外,还需要能把半导体电路系统中的高级封装乃至半导体器件都纳入设计和优化范围,从而实现*的性能。例如,随着未来整体芯片架构变得越来越复杂,而先进工艺的良率难以提高,这就意味着系统中会有更多的小的芯片粒,而这就需要能以一种灵活的架构支持这样的多芯片系统,同时能提供性能和效率的显著提升。显然,这样灵活的架构需要能把对于芯片粒高级封装的技术考虑在内。AMD就是这样在架构中积极考虑高级封装,从而实现性能显著提升的典型例子;其CDNA3和3D V-Cache等最新的架构设计中,高级封装(包括芯片粒和3D堆叠)都是架构中的重要因素。回到ISCA上面的研究,我们也可以发现在2023年的研究词云中,“电路”(circuit)首次出现。ISCA在往年都是专注于抽象层次较高的架构设计,但是如我们所说的摩尔定律遇到瓶颈,未来的架构需要能使用系统级思维把底层电路系统也纳入考虑范围之内,这也是我们认为今年ISCA词云中出现电路这个关键词的原因。
总结我们的观察,ISCA给了我们一个非常好的预测未来的角度。以史为鉴,过去50年半导体工艺始终主导着计算芯片架构的设计;未来半导体工艺演进速度减慢但是应用对于性能需求的提升仍然保持指数级增长,因此需要芯片架构设计从多个纬度来看都变得越来越重要。从纵向维度来看,架构设计需要能够有系统级思维,把上层算法到下层电路和半导体器件都打通实现*设计,而从横向维度来看,随着新应用层出不穷,会有越来越多的专用加速器领域出现。










