
大模型热度迟迟不退,有能力的企业纷纷抢占生态位。百度、阿里、华为、商汤、科大讯飞、360等大型互联网公司,都已经在国内展开了“诸神之战”。
在媒体报道中,参与了大模型竞技的公司几乎都是大公司。这是因为投入大模型,最直观的需求就是“钱”。大厂能成为“开卷”的主力军,主要是因为大模型的开发训练,资金、技术门槛都很高,并非创业者以及小公司可以轻松吃下的蛋糕。
例如国盛证券的一份研报显示,GPT-3训练一次的成本约为140万美元,对于一些更大的LLM模型,训练成本介于200万美元至1200万美元之间。这一成本于全球科技大企业而言并不便宜,但也在可接受范围内。
将大模型的投入“坦诚相告”
由于“贵”,投身大模型的很多企业其实都没告诉投资者们,自己花了多少钱,估计也是怕投资者看到后会产生认知偏差。
最近科大讯飞发了财报,倒是对这一点很坦诚,2023年一季度科大讯飞的利润转亏,其管理层明确表示,除了一些去年遗留的特殊问题外,是因为公司在2022年12月15日启动了“1+N认知智能大模型”的专项攻关,将于2023年5月6日正式发布讯飞星火大模型,攻关项目的新增投入一定程度上影响了当期利润。
科大讯飞的掌门人刘庆峰说得很明白:“针对大模型的技术投入,我们该投的投、绝不手软。”所以在行业内,大家不妨都坦诚点,毕竟大模型已经成为了“阳谋”,花钱投入也是为收获果实打基础。当年马斯克不就是嫌再次投资OpenAI太贵,后来又想去“摘桃子”被拒之门外了吗?
除了“投钱”以外,大模型还需要“投人”,在这一点上,国内外厂商的争抢都很激烈。“谷歌大脑”的大模型人才,从去年底到今年被OpenAI挖走了好几个;节点财经也听说,某一线大厂开价140万美元年薪,挖脚OpenAI的员工。在国内,有公司广发英雄帖,把公司的大部分股权拿出来奖励研发人才。
但是有NLP领域的专家对节点财经表示,做大模型这样的前沿核心技术研发还不能只靠高薪挖人才,更要考虑团队适配程度。
该人士举例,研发大模型是为了落地在业务上,技术团队应该充分了解业务特性。具体到业务场景,诉求存在着不小的差异,大模型的作用是实时掌握这些需求,并对此作出快速响应。
听起来理论很简单,落地可一点都不容易,如果技术团队没有磨合、不适配业务,很可能会导致迭代落后于业务变化。
不过科大讯飞却表示,未来一段时间公司不需要太多额外的人力投入,现在讯飞的团队和资金完全靠得住。有业内人士分析,科大讯飞敢于这样说,大概率是因为讯飞研究院作为人工智能创新研究院的“元老级”机构,建制完整、团结且没有技术上的内耗。
公开资料显示,目前讯飞研究院最核心的研究团队有200余人,其中有两位是《麻省理工科技评论》“35岁以下科技创新35人”榜单中*的年轻科学家,其他团队成员不少是和讯飞一起成长的博士,凭这一点可以能推测出,这群科学家的特点是“懂讯飞的业务诉求”。
此外在算力算法方面,讯飞也是业界公认的AI领域长期坚守者。公开资料显示,科大讯飞在Transformer深度神经网络算法方面拥有丰富经验,已经应用于讯飞的语音识别、图文识别、机器翻译等任务中,并达到国际*水平;而且讯飞创新提出了知识与大模型融合统一的理解框架X-Reasoner,有望弥补大模型的模糊记忆技术短板。
而在算力投入上,讯飞过去几年就一直牵头承担着国家自主可控人工智能平台的诸多项目、在总部自建有业界一流的数据中心,为大模型训练平台建设奠定了基础条件,另外它之前与华为、寒武纪、曙光等企业,也都建立了深度算力合作。
所以推出大模型,并且让它具备商业化条件,对于互联网大厂来说并不是一蹴而就的,以科大讯飞为例,它能在认知大模型能实现快速突破、并且敢于披露和预测自己的投入,与长期在人才、算法、算力上的积累密不可分。
大模型赛道,国家队下场
在这场大模型带来的AI热中,还有很多“吃瓜群众”很难理解科技圈对大模型的拥趸,毕竟类似的场景在元宇宙、AR/VR等领域都出现过。但如果深入回顾人工智能的发展历史与传统AI时代的困境,就能理解大模型之于科技时代的含义。
我们可以将大模型的开发,理解为打造AI时代的“操作系统”,就像我们使用windows系统在电脑中完成工作一样,经由AI时代的“操作系统”大模型,人人都可以是开发者,生产出新产品和新的应用场景。
如果上升到这个层面,各个有能力的国家对大模型的基本要求就是“自主可控”。在360宣布进军大模型领域时,周鸿祎也在采访中提到,GPT是个生产力工具,这将决定未来国际竞争当中的国运。所以,国家队也在大模型的开发和训练上陆续下场。
不久前,中国电信布局了企业版的ChatGPT;复旦大学自然语言处理实验室开发的MOSS 模型已经上线开源;中科院自动化所早在2021年就发布业界*图文音三模态大模型“紫东·太初”,清华大学、北京大学等院校虽然没有推出大模型,但是也在人工智能领域国际*期刊发表了多篇大模型相关的重要文章。
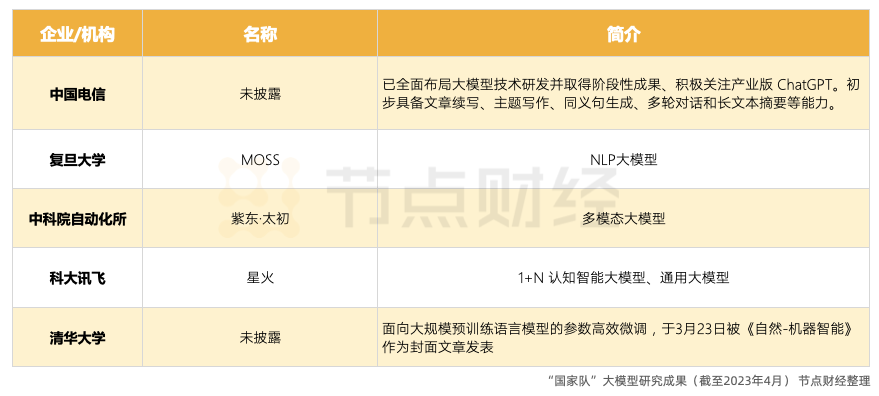
某知名互联网公司的NLP团队负责人对节点财经表示,国家队下场更容易在一些核心数据、参数上占有优势。大模型的训练的本质,就是把语料、数据、参数等当作“食物”喂给大模型,当食物品质越高,大模型就会越智能,还能节省算力。
例如作为“人工智能国家队”,科大讯飞在中文语料上有着明显优势。据了解,在多年认知智能系统研发推广中,科大讯飞积累了超过50TB的行业语料和每天超10亿人次用户交互的活跃应用,拥有大量的机器翻译、语音识别、语音合成等方面的数据,这些数据均是用于大模型训练和优化自然语言处理模型的重要来源之一。
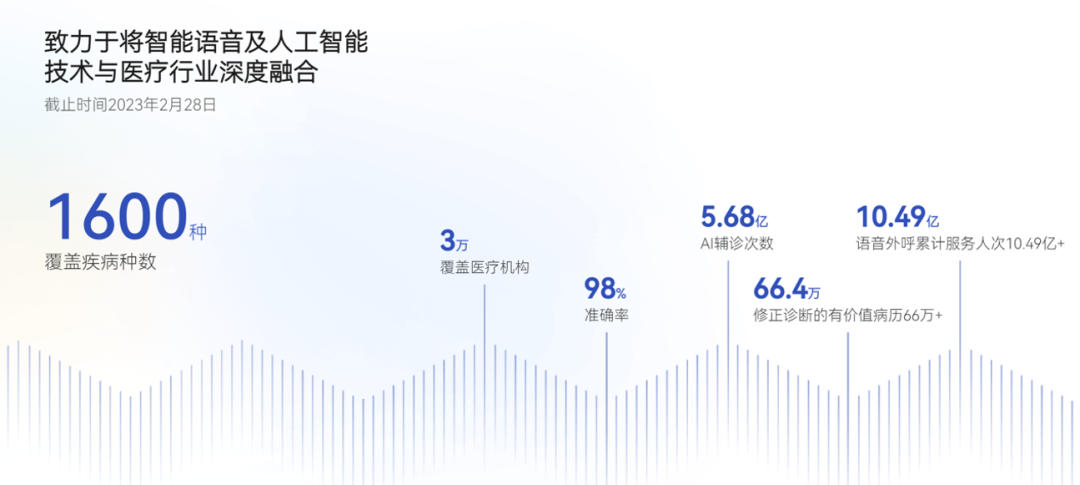
另外,科大讯飞要搭建的“认知大模型”特别注重多轮对话和逻辑推理,才能在行业中深度应用,这就意味着需要更高质量的数据和参数。以医疗领域为例,科大讯飞是全国*通过国家执业医师资格考试的“人工智能系统”,超过了96.3%的医学考生,现在科大讯飞已累计为基层医生提供了超过5.8亿次、日均超过70多万人次的人工智能辅诊。这就意味着在专业领域,科大讯飞可以避免一本正经地回复错误消息,使得专业保障性更强,大模型的落地也“更有专长”。
 科大讯飞,将人工智能与智慧医疗深度融合
科大讯飞,将人工智能与智慧医疗深度融合
还有不少机构在研报中提到,科大讯飞在教育领域的应用规模比医疗更大、数据更翔实,未来的增长更强劲。机构们的肯定也印证了,在真正有刚需、适合认知智能大模型的地方,国家队下场后可以推动大模型在具体行业上做得更透。
投入大模型,反哺根据地
在大模型的“诸神之战”中还有个特点,即面对着市场上成百上千个大模型投资标的,一级市场和二级市场在投资上都有些不知所措。
有VC合伙人评价,大家都看好大模型的发展趋势,也更愿意做跟投,但是一级市场的投资人不一定都能看懂大模型的落地前景,没有领投人就不知道如何开始。二级市场的投资者则提出了灵魂疑问,现在宣布投身大模型的公司这么多,如何判断他们是蹭热点还是真做大模型?我不想买到只会炒作概念的“妖股”。
上海一券商的计算机行业卖方分析师提出了一个解决方案,对于上市公司,可以仔细观察企业有没有让大模型反哺主要业务的发展。
例如百度的文心一言全面嵌入百度内部工作平台如流、对外也上车了百度apollo等业务;钉钉也表示全面接入阿里的 "通义千问 "大模型,增加了 10余种 AI能力、对外也表示要开放;WPS AI表示将嵌入金山办公全线产品,科大讯飞的投资者交流会中也表示,大模型对于其根据地业务,有着很大推动意义。
据了解,科大讯飞即将发布的星火大模型是“1+N认知智能大模型”,其中“1”是代表的是大模型训练平台,“N”是应用于教育、医疗、人机交互、办公、翻译、工业、汽车等多个根据地领域的专用大模型版本。
能提出这样的模型架构,是因为科大讯飞在行业内是少数既懂B端又懂C端的AI公司。刘庆峰预测道,超大规模的大模型已经到了一个临界点,下一个阶段应该用更多专业的子模型来协同训练,获得更可靠的成效。
这个专业阶段的子模型,关联的就是科大讯飞的“根据地业务”,之前我们看科大讯飞的财报时,其根据地业务的基本盘一直非常稳健,例如去年即使在宏观因素的挤压和疫情影响时,科大讯飞根据地业务仍能实现23%的增长。而基于上文提到语料、数据、参数的优势,专业模型通过协调联动,根据地业务还能形成效益的提升。
刘庆峰同样预测道,讯飞在教育、医疗等根据地业务上的大模型成效不比千亿级模型差。特别是想要形成通用领域的智慧涌现,需要把这些模型的知识相互衔接,在整体的大模型中去统一训练,未来就有希望在教育、办公、医疗等应用领域抢占先机。有不少机构同样预测道,星火认知大模型反哺业务,会让科大讯飞的根据地业务壁垒更加深厚。
几天前,被誉为“AI界传奇”的陆奇在《我的大模型世界观》演讲中提到了对于大模型的展望,即大模型是平台型机会,以模型为先的平台需要以下几个特征:1.开箱即用;2.要有一个足够简单和好的商业模式;3.有自己杀手级应用。
所以星火大模型的发布落地,不仅是简单易用的专业化模型;还可以在科大讯飞自己的教育、医疗、办公等场景打造经典应用;再经由讯飞的开放平台开放出去,让AI认知大模型从“可用”阶段迈入“常用”阶段,带动AI时代的“操作系统”更加普惠化;最后为大模型的使用者创造现金流、创造真金白银的产业附加值,这才是大模型的发展“伟力”。









